 RK3588部署Deepseek模型全流程
RK3588部署Deepseek模型全流程




开发环境:
主机环境:windows下vmware中的ubuntu22.04版本
注意:转换7B模型的时候需要用到32G的运行内存,本人实测,建议最少给虚拟机分配40G的运存才能稳定转换。不建议使用swap交换空间,会经常卡死。如果电脑内存不够建议加内存条
1.5b模型转换成rkllm格式后的大小为1.9G,7b模型转换后为7.7G左右,请保证ubuntu下磁盘空间剩余充足
目标机(orangepi5pro开发板)环境:

注意:如果想使用rk3588的npu运行和推理deepseek-r1-1.5b/7b模型,npu版本最低为0.9.8,本人亲测0.9.6版本不支持。进入到开发板的系统中,执行cat /proc/rknpu/version或者cat /sys/kernel/debug/rknpu/version可查看当前的版本。如果不知道如何更换npu版本,请参照香橙派5 RK3588S NPU驱动升级0.9.8_香橙派3588安装github系统linux-优快云博客
部署步骤(以下1-6步都在虚拟机的ubuntu里操作)
1,安装anaconda软件环境,详细可参考在Ubuntu中安装Anaconda和创建虚拟环境(保姆级教学,值得借鉴与信任)_ubuntu anaconda创建虚拟环境-优快云博客
2,anaconda安装完成后,执行conda create -n RKLLM-Toolkit python=3.8新建conda环境
,然后用conda env list命令可验证是否创建成功
conda环境创建成功后,执行conda activate RKLLM-Toolkit,激活并进入到RKLLM-Toolkit环境(退出已激活的conda环境到默认的base的命令为conda deactivate)
下图为正确安装anaconda和正确激活RKLLM-Toolkit环境的示例

3,获取rkllm转换工具
airockchip/rknn-llm at release-v1.1.4将此网站的仓库git clone下来,进入到rknn-llm-release-v1.1.4/rkllm-toolkit/packages目录下并执行pip install rkllm_toolkit-1.1.4-cp38-cp38-linux_x86_64.whl,耐心等待安装完成
4,下载DeepSeek-R1-Distill-Qwen-1.5B/DeepSeek-R1-Distill-Qwen-7B原始模型
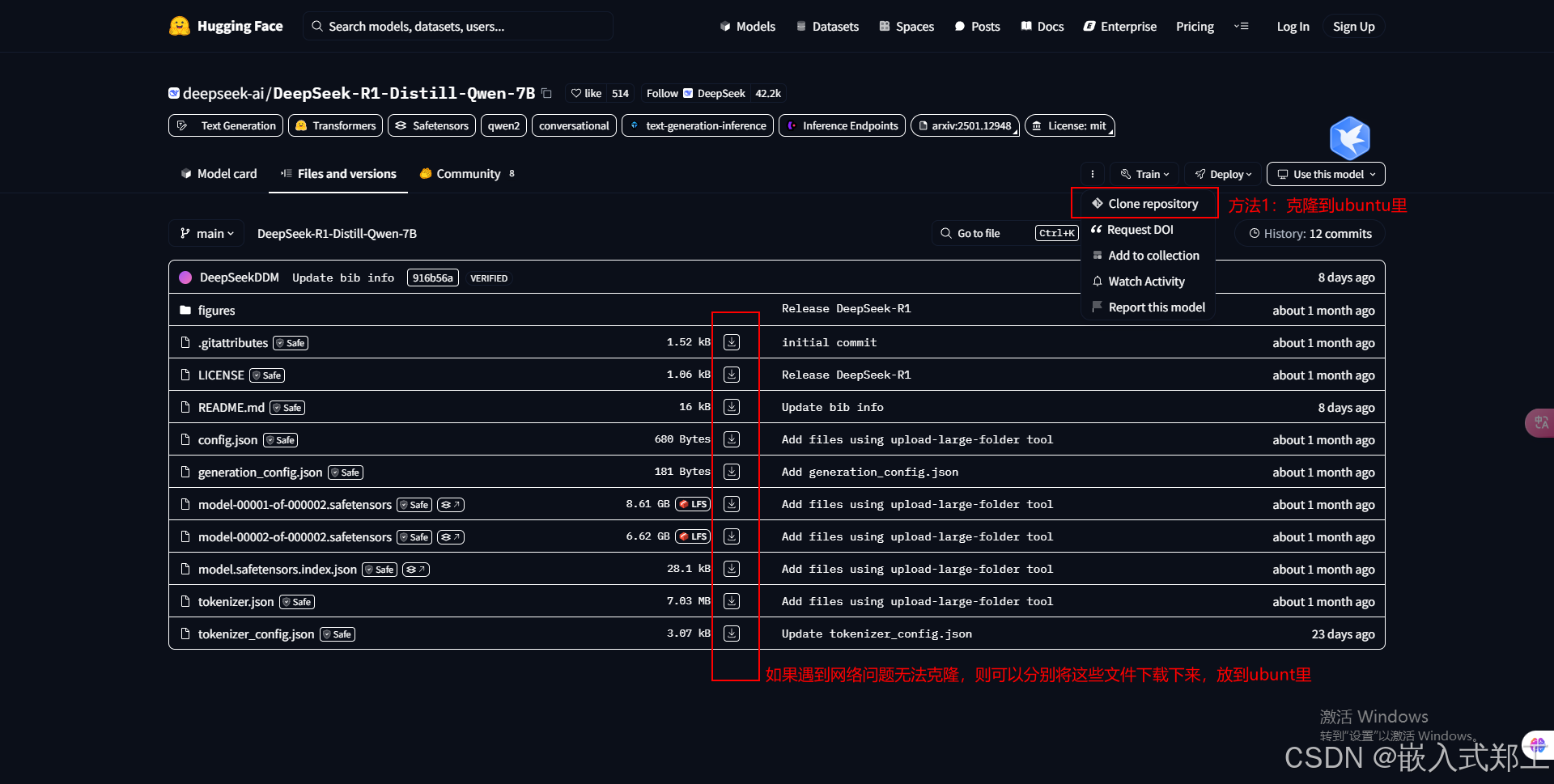
方法一:直接通过浏览器打开并下载deepseek-ai/DeepSeek-R1-Distill-Qwen-7B at main (huggingface.co)
方法二:在ubuntu终端通过命令下载
安装huggingface工具并指定源镜像地址:
pip3 install huggingface-cli -i https://mirrors.huaweicloud.com/repository/pypi/simple
export HF_ENDPOINT=https://hf-mirror.com
将deepseek-ai/DeepSeek-R1-xx模型资源下载到本地当前目录下:
huggingface-cli download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --local-dir . --local-dir-use-symlinks False
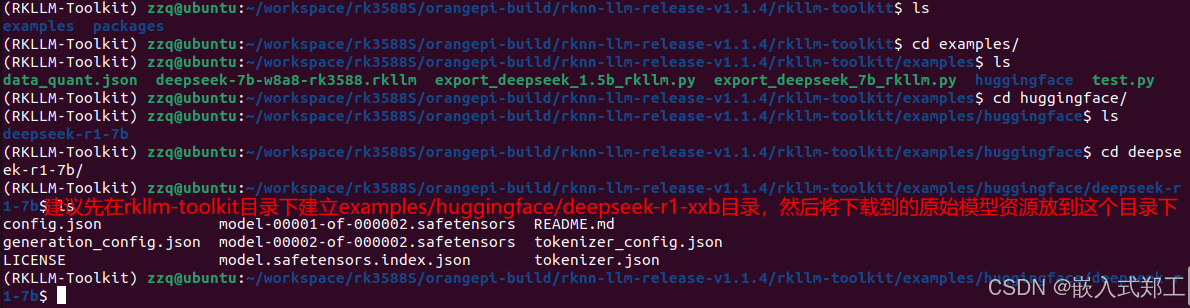
5,创建必要的文件,保证后面能正常执行转换
克隆的仓库里的rknn-llm-release-v1.1.4/rkllm-toolkit/examples目录下只有一个test.py文件,我们需要在这里新建data_quant.json和export_deepseek_7b_rkllm.py这两个文件,
data_quant.json文件内容示例如下:
[{"input":"Human: 你好!\nAssistant: ", "target": "你好!我是人工智能助手KK!"},{"input":"Human: 你可以干什么?\nAssistant: ", "target": "我可以唱跳rap"}]export_deepseek_7b_rkllm.py文件内容示例如下:
rom rkllm.api import RKLLM
import os
#os.environ['CUDA_VISIBLE_DEVICES']='0'
#注意这里替换成第四步下载的deepseek模型存放的实际目录
modelpath = './huggingface/deepseek-r1-7b'
llm = RKLLM()
# Load model
# Use 'export CUDA_VISIBLE_DEVICES=0' to specify GPU device
# options ['cpu', 'cuda']
ret = llm.load_huggingface(model=modelpath, model_lora = None, device='cpu')
if ret != 0:
print('Load model failed!')
exit(ret)
# Build model
dataset = "./data_quant.json"
qparams = None
ret = llm.build(do_quantization=True, optimization_level=1, quantized_dtype='w8a8',
quantized_algorithm='normal', target_platform='rk3588', num_npu_core=3,
extra_qparams=qparams,dataset=dataset)
if ret != 0:
print('Build model failed!')
exit(ret)
# Export rkllm model
ret = llm.export_rkllm(f"./deepseek-7b-w8a8-rk3588.rkllm")
if ret != 0:
print('Export model failed!')
exit(ret)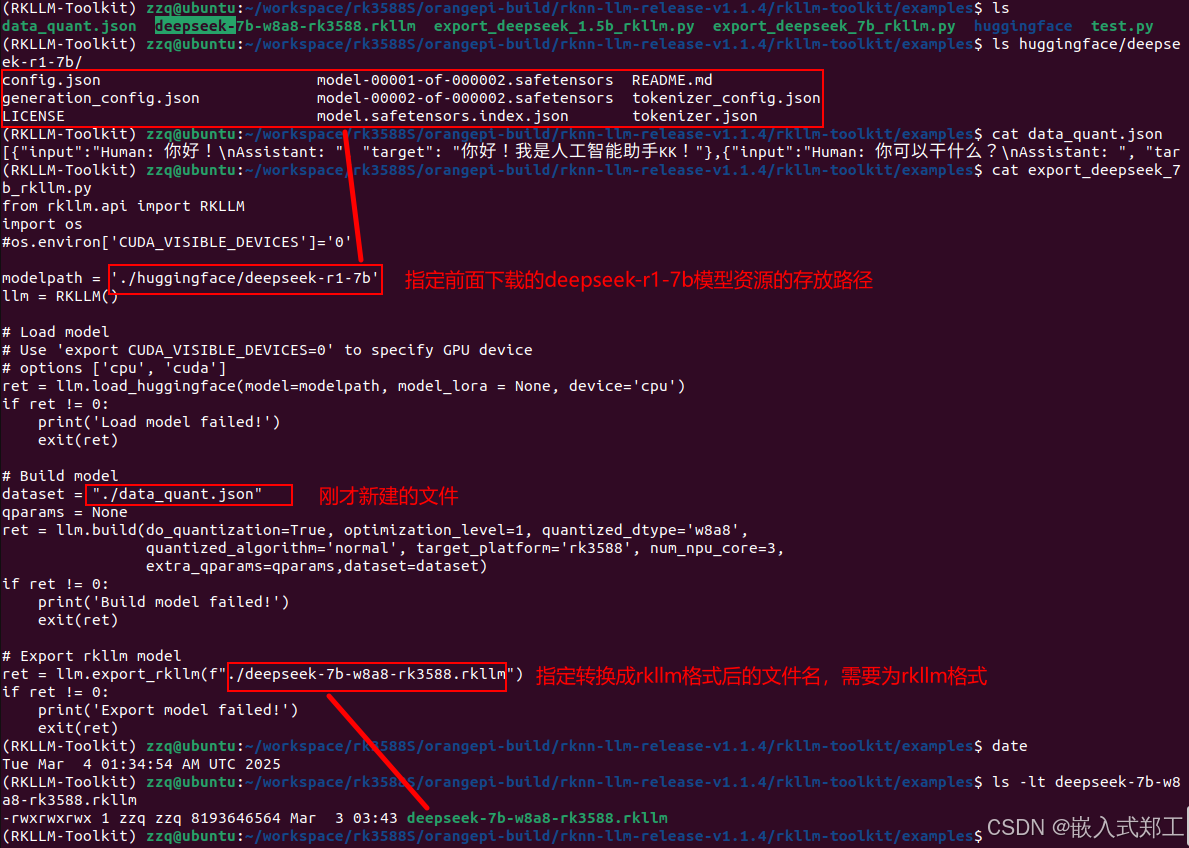
6,使用rknn-toolkit工具将原始的huggingface格式的DeepSeek-R1-xx模型转化为瑞芯微支持的rkllm格式,这样才能使用瑞芯微的npu进行推理(注意:需要在conda activate RKLLM-Toolkit环境下运行,请先激活)
执行python export_deepseek_7b_rkllm.py命令,开始转换,整个过程大概要20-30分钟
转换过程如图所示:这是一个相当大的任务,cpu和磁盘以及内存的利用率很高
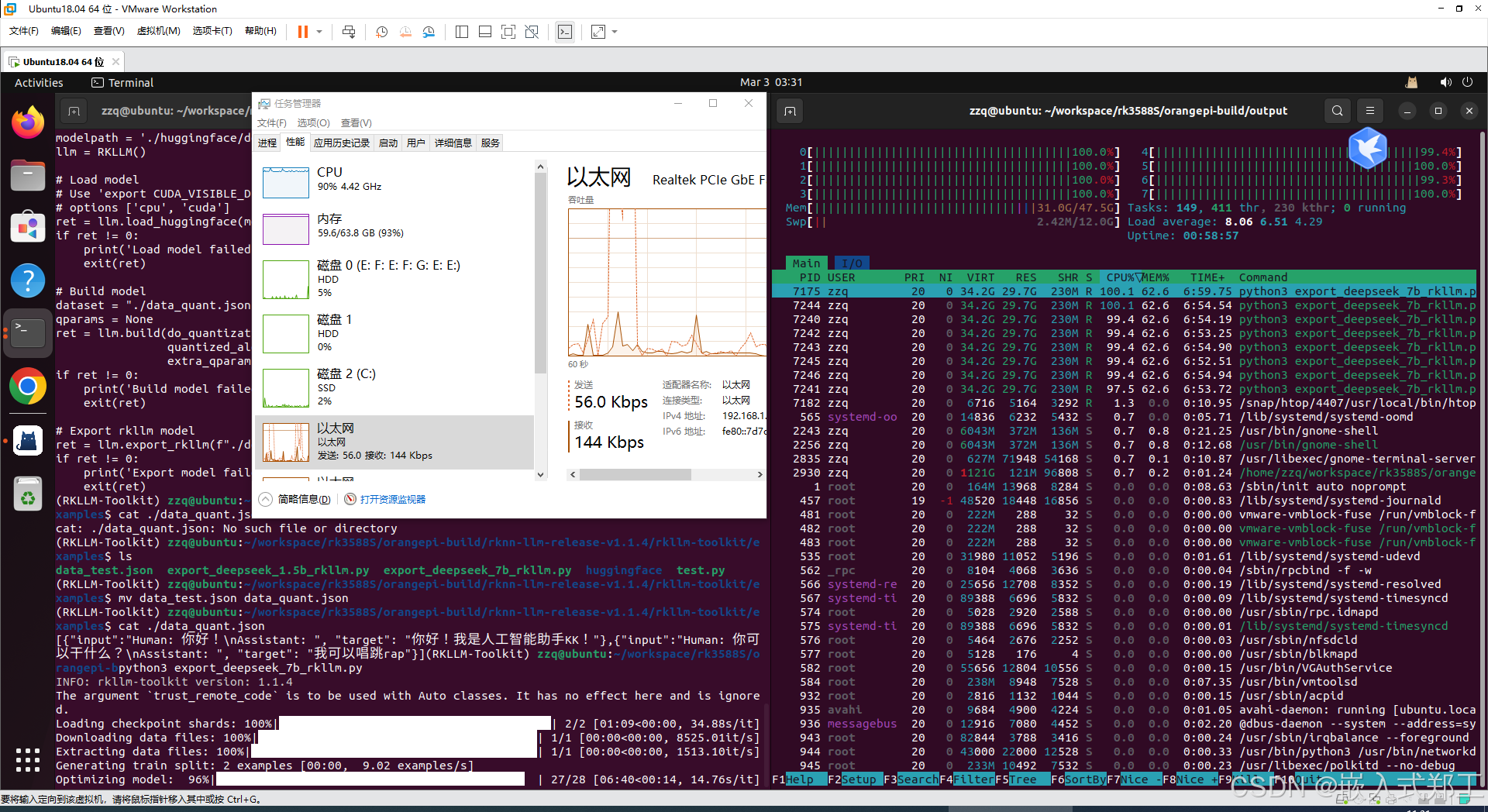

转换完成后会生成deepseek-7b-w8a8-rk3588.rkllm这个文件,将它传到开发板的LINUX系统里

7,部署开发板环境,以便使用rk3588的npu运行转换后的deepseek模型(下面步骤都在开发板的ubuntu系统中操作)
git clone GitHub - airockchip/rknn-llm
sudo cp rkllm-runtime/Linux/librkllm_api/aarch64/librkllmrt.so /usr/lib/librkllmrt.so
cd examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy
chmod a+x build-linux.sh
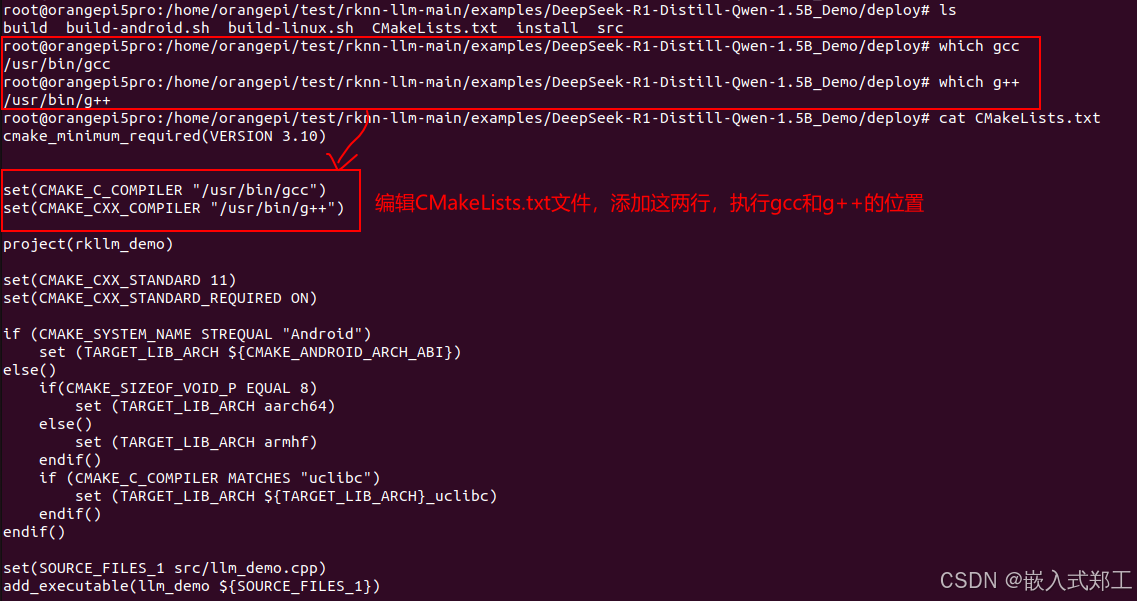
./build-linux.sh
执行完上面的脚本后,会在当前文件夹会出现install/demo_Linux_aarch64目录,将第六步生成的转换后的模型拷贝到这里
cd install/demo_Linux_aarch64
diff lib/librkllmrt.so /usr/lib/librkllmrt.so //验证一下刚生成的这个库文件是不是和rknn-llm-main/rkllm-runtime/Linux/librkllm_api/aarch64/librkllmrt.so的一样,要保证它们是1.1.4版本的才能满足这个模型的运行要求

8,在开发板上使用rk3588的npu推理和运行转换后的deepseek模型
cd rknn-llm-main/examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/install/demo_Linux_aarch64
执行命令taskset 0xf0 ./llm_demo ./deepseek-7b-w8a8-rk3588.rkllm 5000 5000
命令解释:在 RK3588S 芯片的全部 4 个 Cortex-A76 大核心上,运行一个名为 llm_demo 的程序。该程序会加载并使用一个名为 deepseek-7b-w8a8-rk3588.rkllm 的 70 亿参数、经过 8 位量化并为 RK3588 优化的 DeepSeek 模型,同时传递了两个值为 5000 的数字参数给这个演示程序。通过将计算密集型的 LLM 推理任务绑定到性能更强的大核心上,通常是为了获得更好的执行性能和更快的响应速度。
命令成功运行界面如下:
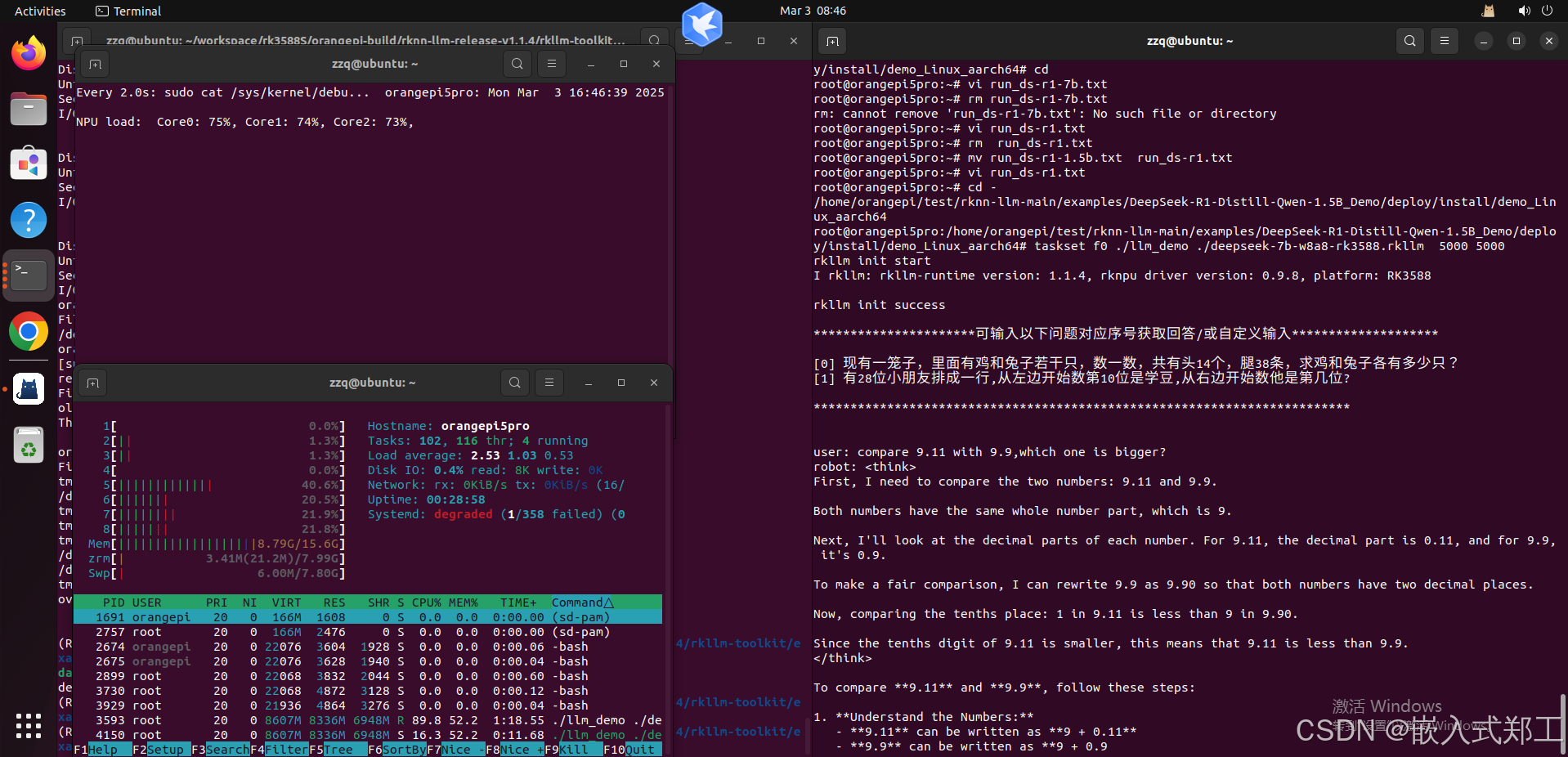
使用watch sudo cat /sys/kernel/debug/rknpu/load命令实时监控npu利用率,此时正在使用npu进行推理和运算,NPU的三个核心负载率比较均衡,都是70%+,而且CPU参与率明显下降(相比使用ollama方式的时候cpu占用率为100%),内存占用大概9G
至此,大功告成!!!
以上1-8步实现了通过rk3588的NPU运行ds的方法,另外分享另一种可以在3588上运行deepseek的方法(只使用CPU推理运行):
直接在开发板系统中执行ollama run deepseek-r1:1.5b或者ollama run deepseek-r1:7b 命令,默默等待就行了。他会去下载ollama工具以及deepseek-r1模型,下载完之后会自动运行该模型。后期如果再次运行,再次执行这条命令就行,他不会重复去下载的
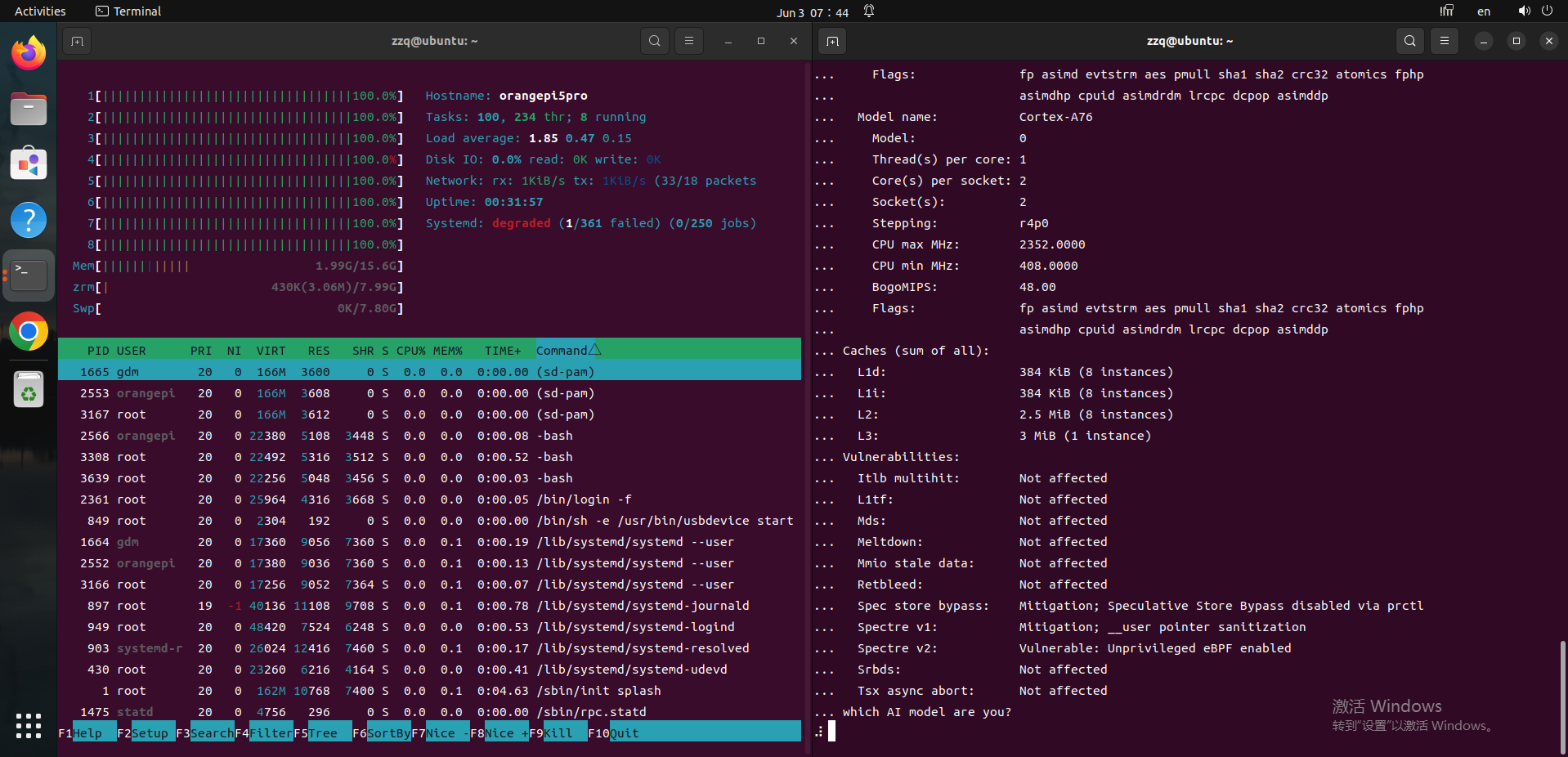
我试过用这种方式,一旦让他开始回答你的问题,cpu的八个核心负载一下全部飙到100%,CPU发烫严重,如果使用NPU的话,就不会有感觉。我认为使用ollama运行deepseek的方式只适合自己玩一下,不适合在生产中使用,因为在用cpu进行AI推理的时候吧cpu全占满了,其他的进程任务就别想执行了


















 232
232







 到【灌水乐园】发言
到【灌水乐园】发言







