







前言
在 RK3588 上部署大模型可以显著提升计算效率、节能、加速推理过程,并实现本地化推理,适合各种边缘计算应用,如智能设备、自动驾驶、工业机器人、健康监测等领域。此外,RK3588 配备了强大的 NPU(神经网络处理单元),可以加速深度学习推理过程。通过在 RK3588 上部署大模型,NPU 能够显著提高模型推理速度,减少推理时间,尤其在进行实时推理时十分重要。
1.部署方式
现有我知道的部署方式有两种,一是利用ollama去部署,二是使用rknn官方代码库去部署,前者使用cpu,后者使用npu,先说结论两者token速度相差不大。
废话少说,下面分享部署过程。
1.1 利用ollama部署
这里就不多说了,因为之前写过一篇利用ollama部署deepseek的文章,这里就不赘述,直接甩命令:
# 下载并安装ollama
curl -fsSL https://ollama.com/install.sh | sh
# 下载deepseek-1.5b
ollama pull deepseek-r1:1.5b
# 运行deepseek
ollama run deepseek-r1:1.5b
运行之后可以看到,cpu的占用几乎满了:
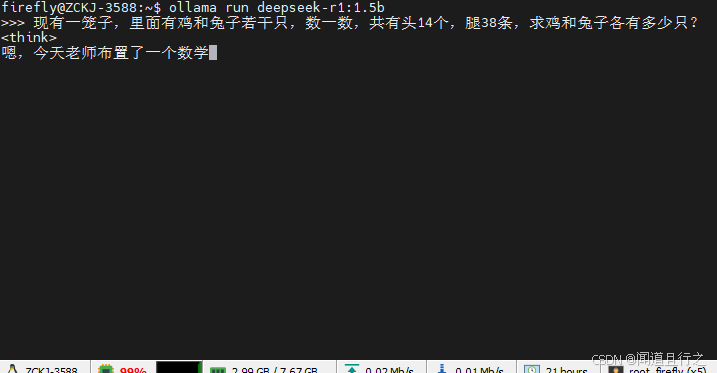](https://i-blog.csdnimg.cn/direct/6f4497d465d14bab990f3809e521424c.png)
watch sudo cat /sys/kernel/debug/rknpu/load
查看一下npu的占用率,根本没动:

1.2 官方代码库部署
1.2.1 安装依赖(x86_64机器)
conda create -n rkllm python=3.10
conda activate rkllm
pip install rkllm_toolkit-1.1.4-cp310-cp310-linux_x86_64.whl
这里的rkllm_toolkit安装包可以去这里下载:rknn-llm,如果嫌下载慢可以私信问我要。
1.2.2 下载模型及转换模型(x86_64机器)
下载项目地址:rknn-llm
下载模型地址:
DeepSeek-R1-Distill-Qwen-1.5B
cd examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/export/
python export_rkllm.py
转换之前记得修改你的模型路径:

转换之后地模型后缀为rkllm。
1.2.3 编译运行代码(x86_64机器)(可选)
①先下载下载交叉编译工具链 gcc-arm-10.2-2020.11-x86_64-aarch64-none-linux-gnu
这里多说一句,交叉编译工具链的作用是是为了在x86_64平台下编译arrch平台下能够执行的文件。
②修改examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/build-linux.sh中GCC_COMPILER_PATH的路径:
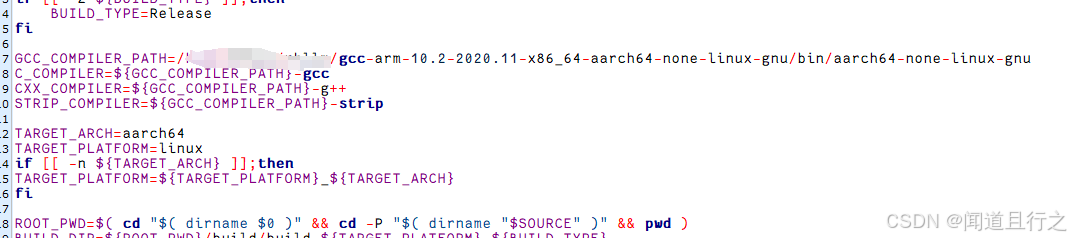
③开始编译:
cd examples/DeepSeek-R1-Distill-Qwen-1.5B_Demo/deploy/
bash build-linux.sh
如图所示,编译之后所需库和可执行文件在deploy/install/demo_Linux_aarch64/目录下:
1.2.4 直接下载编译好的代码(x86_64机器)(可选)
如果不想自己编译代码,这里有编译好的代码:
git clone https://www.modelscope.cn/radxa/DeepSeek-R1-Distill-Qwen-1.5B_RKLLM.git
注:1.2.3和1.2.4必选其中一个
1.2.5 运行代码(RK3588)
将转化模型和代码复制到rk3588后,执行以下命令:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:./lib
export RKLLM_LOG_LEVEL=1
./llm_demo DeepSeek-R1-Distill-Qwen-1.5B.rkllm 10000 10000
这里可以看到,cpu的利用率下去了:
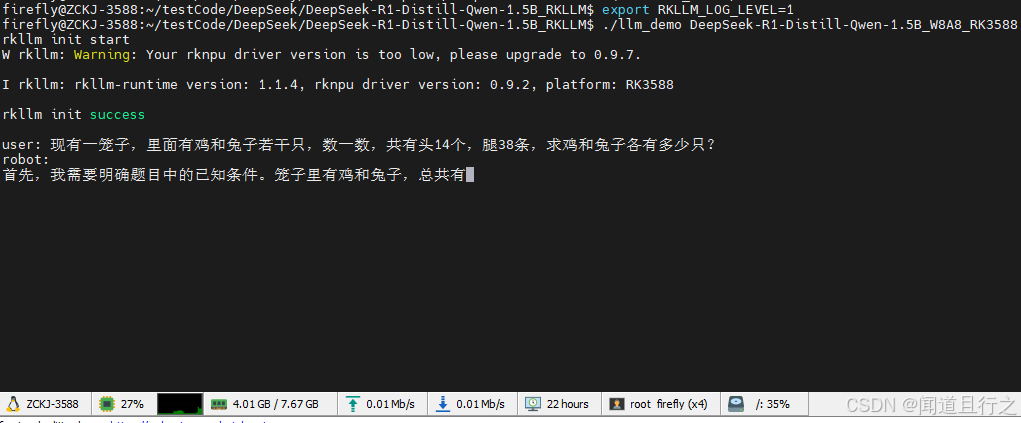
每个npu的占用率大概在30%-40%之间:

参考
RKLLM DeepSeek-R1
这里推荐一个网站,在Hugging Face下不下来的模型可以在这里下载!!魔搭社区
总结
本文介绍了两种在RK3588上部署deepseek-1.5b的方法,虽然两种方法的token是差不多的,但是我还是推荐使用npu的方法去推理大模型,后续会继续测试deepseek中更大参数体量的模型,测试一下rk3588的极限在哪里。


















 2601
2601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









