 批归一化在神经网络中的作用
批归一化在神经网络中的作用





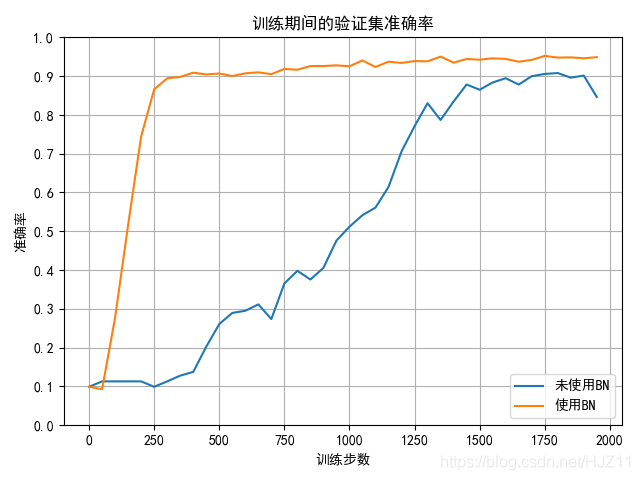
 本文通过对比有无批归一化的神经网络,展示了批归一化如何加速训练过程并提高模型准确率。实验使用MNIST数据集,通过可视化训练期间的验证集准确率,直观展现批归一化带来的收敛速度提升。
本文通过对比有无批归一化的神经网络,展示了批归一化如何加速训练过程并提高模型准确率。实验使用MNIST数据集,通过可视化训练期间的验证集准确率,直观展现批归一化带来的收敛速度提升。
"""
*关于代码的两点说明:*
>本代码所编写的类并不代表是tensorflow最好的实践--只是为了展示批归一化。
>本案例使用了MNIST数据集作为展示,但代码中设计的网络并不是作为手写字母识别用。之所以如此设计网络结构:
1、忠于原论文;2、网络足够复杂,并可以展示批归一化可以加速网络训练。
"""
import tensorflow as tf
import tqdm
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
from tensorflow.examples.tutorials.mnist import input_data
# 设置字符集,防止中文乱码
mpl.rcParams['font.sans-serif'] = [u'simHei']
mpl.rcParams['axes.unicode_minus'] = False
mnist = input_data.read_data_sets("./data", one_hot=True)
"""
下面创建了一个 `NeuralNet`类。(可以创建带批归一化或不带批归一化的网络)
"""
class NeuralNet:
def __init__(self, initial_weights, activation_fn, use_batch_norm):
"""
Initializes this object, creating a TensorFlow graph using the given parameters.
:param initial_weights:(是一个np.array的列表) list of NumPy arrays or Tensors
Initial values for the weights for every layer in the network. We pass these in
so we can create multiple networks with the same starting weights to eliminate
training differences caused by random initialization differences.
The number of items in the list defines the number of layers in the network,
and the shapes of the items in the list define the number of nodes in each layer.
e.g. Passing in 3 matrices of shape (784, 256), (256, 100), and (100, 10) would
create a network with 784 inputs going into a hidden layer with 256 nodes,
followed by a hidden layer with 100 nodes, followed by an output layer with 10 nodes.
:param activation_fn: Callable
The function used for the output of each hidden layer. The network will use the same
activation function on every hidden layer and no activate function on the output layer.
e.g. Pass tf.nn.relu to use ReLU activations on your hidden layers.
:param use_batch_norm: bool
Pass True to create a network that uses batch normalization; False otherwise
Note: this network will not use batch normalization on layers that do not have an
activation function.
"""
# 跟踪是否使用批归一化
self.use_batch_norm = use_batch_norm
self.name = "使用BN" if use_batch_norm else "未使用BN"
# self.name = "With Batch Norm" if use_batch_norm else "Without Batch Norm"
# 批归一化在训练和推理期间,计算方式不同。
# 故is_training占位符,告诉网络使用何种方式。
self.is_training = tf.placeholder(tf.bool, name="is_training")
# 记录训练准确率,以便作图。
self.training_accuracies = []
# 创建网络图
self.build_network(initial_weights, activation_fn)
def build_network(self, initial_weights, activation_fn):
"""
Build the graph. The graph still needs to be trained via the `train` method.
:param initial_weights: list of NumPy arrays or Tensors
:param activation_fn: Callable
"""
self.input_layer = tf.placeholder(tf.float32, [None, initial_weights[0].shape[0]])
layer_in = self.input_layer
# 做了一个循环,构建全连接网络
for weights in initial_weights[:-1]:
layer_in = self.fully_connected(layer_in, weights, activation_fn)
self.output_layer = self.fully_connected(layer_in, initial_weights[-1])
def fully_connected(self, layer_in, initial_weights, activation_fn=None):
"""
创建一个标准的全连接层,它的输入和输出节点数由参数`initial_weights` 中定义了。
Creates a standard, fully connected layer. Its number of inputs and outputs will be
defined by the shape of `initial_weights`, and its starting weight values will be
taken directly from that same parameter. If `self.use_batch_norm` is True, this
layer will include batch normalization, otherwise it will not.
:param layer_in: Tensor
The Tensor that feeds into this layer. It's either the input to the network or the output
of a previous layer.
:param initial_weights: NumPy array or Tensor
Initial values for this layer's weights. The shape defines the number of nodes in the layer.
e.g. Passing in 3 matrix of shape (784, 256) would create a layer with 784 inputs and 256
outputs.
:param activation_fn: Callable or None (default None)
The non-linearity used for the output of the layer. If None, this layer will not include
batch normalization, regardless of the value of `self.use_batch_norm`.
e.g. Pass tf.nn.relu to use ReLU activations on your hidden layers.
"""
# 注意:最后一层输出层不使用批归一化
if self.use_batch_norm and activation_fn:
# todo-批归一化使用权重,但并不需要偏置项。因为其计算 gamma和beta 2个变量,使得偏置项不是必要的。
weights = tf.Variable(initial_weights)
linear_output = tf.matmul(layer_in, weights)
# 对线性组合进行批归一化
batch_normalized_output = tf.layers.batch_normalization(linear_output, training=self.is_training)
# 在批归一化后,使用激活函数。
return activation_fn(batch_normalized_output)
else:
# todo-不使用批归一化时,创建一个标准的全链接(需要创建bias变量)
weights = tf.Variable(initial_weights)
biases = tf.Variable(tf.zeros([initial_weights.shape[-1]]))
linear_output = tf.add(tf.matmul(layer_in, weights), biases)
return linear_output if not activation_fn else activation_fn(linear_output)
def train(self, session, learning_rate, training_batches, batches_per_sample,
save_model_as=None):
"""
Trains the model on the MNIST training dataset.
:param session: Session
Used to run training graph operations.
:param learning_rate: float
Learning rate used during gradient descent.
:param training_batches: int
Number of batches to train.
:param batches_per_sample: int
How many batches to train before sampling the validation accuracy.
:param save_model_as: string or None (default None)
Name to use if you want to save the trained model.
"""
# 目标标签占位符
labels = tf.placeholder(tf.float32, [None, 10])
# 定义损失和优化器
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=self.output_layer))
# 定义准确率
correct_prediction = tf.equal(tf.argmax(self.output_layer, 1), tf.argmax(labels, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
if self.use_batch_norm:
# todo 若不在dependencies中定义update ops ,那么批归一化不会更新全局统计量 ,
# 这将导致模型在推理阶段效果低下。
"""
tf.get_collection() :返回具有给定`name`的集合中的值列表,该列表包含它们所在的顺序的值集。
tf.GraphKeys 标准库使用名称来收集和检索与图关联的值
例如opt.minimize()方法中参数:var_list:--默认就是使用从图中收集的`GraphKeys.TRAINABLE_VARIABLES`
"""
with tf.control_dependencies(tf.get_collection(tf.GraphKeys.UPDATE_OPS)):
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy)
else:
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy)
# 批量训练 (tqdm 用于展示时间)
for i in tqdm.tqdm(range(training_batches)):
# 使用了批量== 60
batch_xs, batch_ys = mnist.train.next_batch(60)
session.run(train_step, feed_dict={self.input_layer: batch_xs,
labels: batch_ys,
self.is_training: True})
# 定期收集验证集的准确率,所以self.is_training设置为False。
if i % batches_per_sample == 0:
test_accuracy = session.run(accuracy, feed_dict={self.input_layer: mnist.validation.images,
labels: mnist.validation.labels,
self.is_training: False})
self.training_accuracies.append(test_accuracy)
# 训练结束后,报告测试数据集准确率
test_accuracy = session.run(accuracy, feed_dict={self.input_layer: mnist.validation.images,
labels: mnist.validation.labels,
self.is_training: False})
print('{}: 训练结束, 最终验证集准确率为 = {}'.format(self.name, test_accuracy))
# 保存模型。并通过test方法调用,用于预测。
if save_model_as:
tf.train.Saver().save(session, save_model_as)
def test(self, session, test_training_accuracy=False,
include_individual_predictions=False, restore_from=None):
"""
Trains a trained model on the MNIST testing dataset.
:param session: Session
Used to run the testing graph operations.
:param test_training_accuracy: bool (default False)
If True, perform inference with batch normalization using batch mean and variance;
if False, perform inference with batch normalization using estimated population mean and variance.
Note: in real life, *always* perform inference using the population mean and variance.
This parameter exists just to support demonstrating what happens if you don't.
:param include_individual_predictions: bool (default True)
This function always performs an accuracy test against the entire test set. But if this parameter
is True, it performs an extra test, doing 200 predictions one at a time, and displays the results
and accuracy.
:param restore_from: string or None (default None)
Name of a saved model if you want to test with previously saved weights.
"""
# 存储实际真实标签
labels = tf.placeholder(tf.float32, [None, 10])
correct_prediction = tf.equal(tf.argmax(self.output_layer, 1), tf.argmax(labels, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 从之前保存的模型中恢复。
if restore_from:
tf.train.Saver().restore(session, restore_from)
# 测试集准确率
test_accuracy = session.run(accuracy, feed_dict={self.input_layer: mnist.test.images,
labels: mnist.test.labels,
self.is_training: test_training_accuracy})
print('-' * 75)
print('{}: 在完整的测试集上的准确率为 = {}'.format(self.name, test_accuracy))
# 取代批量预测,而以单张图片预测
if include_individual_predictions:
predictions = []
correct = 0
# 预测200张图片
for i in range(200):
# 注意:传入了`test_training_accuracy`==False 给`self.is_training`参数,是告诉模型:
# 使用训练时候估计的全局统计量,而不是该批的统计量。
pred, corr = session.run([tf.arg_max(self.output_layer, 1), accuracy],
feed_dict={self.input_layer: [mnist.test.images[i]],
labels: [mnist.test.labels[i]],
self.is_training: test_training_accuracy})
correct += corr
predictions.append(pred[0])
print("200 Predictions:", predictions)
print("Accuracy on 200 samples:", correct / 200)
# todo-定义一个函数。`plot_training_accuracies`,可视化`training_accuracies`列表,该列表保存了训练期间验证集准确率。
def plot_training_accuracies(*args, **kwargs):
"""
Displays a plot of the accuracies calculated during training to demonstrate
how many iterations it took for the model(s) to converge.
:param args: One or more NeuralNet objects
You can supply any number of NeuralNet objects as unnamed arguments
and this will display their training accuracies. Be sure to call `train`
the NeuralNets before calling this function.
:param kwargs:
You can supply any named parameters here, but `batches_per_sample` is the only
one we look for. It should match the `batches_per_sample` value you passed
to the `train` function.
"""
fig, ax = plt.subplots()
batches_per_sample = kwargs['batches_per_sample']
for nn in args:
ax.plot(range(0, len(nn.training_accuracies) * batches_per_sample, batches_per_sample),
nn.training_accuracies, label=nn.name)
ax.set_xlabel('训练步数')
ax.set_ylabel('准确率')
ax.set_title('训练期间的验证集准确率')
ax.legend(loc=4)
ax.set_ylim([0, 1])
plt.yticks(np.arange(0, 1.1, 0.1))
plt.grid(True)
plt.show()
# todo-定义1个函数。`train_and_test`,创建2个网络,一个做批归一化,一个不做批归一化。两者都将训练并测试。
# 并调用函数 `plot_training_accuracies`来可视化其训练过程中准确率的变化。更重要一点:
# 我们将在网络之外定义同一个权重,传入2个网络中,这样确保2个网络从完全相同权重出发进行训练。
def train_and_test(use_bad_weights, learning_rate, activation_fn, training_batches=50000, batches_per_sample=500):
"""
Creates two networks, one with and one without batch normalization, then trains them
with identical starting weights, layers, batches, etc. Finally tests and plots their accuracies.
:param use_bad_weights: bool
If True, initialize the weights of both networks to wildly inappropriate weights;
if False, use reasonable starting weights.
:param learning_rate: float
Learning rate used during gradient descent.
:param activation_fn: Callable
The function used for the output of each hidden layer. The network will use the same
activation function on every hidden layer and no activate function on the output layer.
e.g. Pass tf.nn.relu to use ReLU activations on your hidden layers.
:param training_batches: (default 50000)
Number of batches to train.
:param batches_per_sample: (default 500)
How many batches to train before sampling the validation accuracy.
"""
#
# 注意: 使用了权重来定义网络各层的维度。原论文中使用了3层隐藏层,每层节点数量为100。
# 大家可以随意更改网络结构。只要确保输入维度==784,输出为==10即可。
if use_bad_weights:
# 下面是糟糕的权重,因为其标准差为==5 .
weights = [np.random.normal(size=(784, 100), scale=5.0).astype(np.float32),
np.random.normal(size=(100, 100), scale=5.0).astype(np.float32),
np.random.normal(size=(100, 100), scale=5.0).astype(np.float32),
np.random.normal(size=(100, 10), scale=5.0).astype(np.float32)
]
else:
# 好的初始化权重
weights = [np.random.normal(size=(784, 100), scale=0.05).astype(np.float32),
np.random.normal(size=(100, 100), scale=0.05).astype(np.float32),
np.random.normal(size=(100, 100), scale=0.05).astype(np.float32),
np.random.normal(size=(100, 10), scale=0.05).astype(np.float32)
]
# 确保TensorFlow's默认图为空。
tf.reset_default_graph()
# 创建2个网络结构相同的网络。(唯一区别:一个有批归一化,一个无)
nn = NeuralNet(weights, activation_fn, False)
bn = NeuralNet(weights, activation_fn, True)
# 训练并测试
with tf.Session() as sess:
tf.global_variables_initializer().run()
nn.train(sess, learning_rate, training_batches, batches_per_sample)
bn.train(sess, learning_rate, training_batches, batches_per_sample)
nn.test(sess)
bn.test(sess)
# 可视化 训练期间验证准确率是如何变化的。
# 并比较模型收敛的速度。
plot_training_accuracies(nn, bn, batches_per_sample=batches_per_sample)
if __name__ == '__main__':
# 参数:use_bad_weights, learning_rate,
# activation_fn, training_batches = 50000, batches_per_sample = 500)
# train_and_test(True, 0.01, tf.nn.relu, 2000, 50) # 学习率为0.01
train_and_test(False, 1, tf.nn.sigmoid, 2000, 50) # 学习率为1
D:\Anaconda\python.exe D:/AI20/HJZ/04-深度学习/3-CNN/20191207/0502_BN_Lesson上课的.py
WARNING:tensorflow:From D:/AI20/HJZ/04-深度学习/3-CNN/20191207/0502_BN_Lesson上课的.py:22: read_data_sets (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use alternatives such as official/mnist/dataset.py from tensorflow/models.
WARNING:tensorflow:From D:\Anaconda\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\mnist.py:260: maybe_download (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.
Instructions for updating:
Please write your own downloading logic.
WARNING:tensorflow:From D:\Anaconda\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\base.py:252: _internal_retry.<locals>.wrap.<locals>.wrapped_fn (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version.
Instructions for updating:
Please use urllib or similar directly.
WARNING:tensorflow:From D:\Anaconda\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\mnist.py:262: extract_images (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes.
Instructions for updating:
Extracting ./data\train-images-idx3-ubyte.gz
Please use tf.data to implement this functionality.
WARNING:tensorflow:From D:\Anaconda\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\mnist.py:267: extract_labels (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Successfully downloaded train-labels-idx1-ubyte.gz 28881 bytes.
Instructions for updating:
Extracting ./data\train-labels-idx1-ubyte.gz
Please use tf.data to implement this functionality.
WARNING:tensorflow:From D:\Anaconda\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\mnist.py:110: dense_to_one_hot (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use tf.one_hot on tensors.
Successfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes.
Extracting ./data\t10k-images-idx3-ubyte.gz
Successfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes.
Extracting ./data\t10k-labels-idx1-ubyte.gz
WARNING:tensorflow:From D:\Anaconda\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\mnist.py:290: DataSet.__init__ (from tensorflow.contrib.learn.python.learn.datasets.mnist) is deprecated and will be removed in a future version.
Instructions for updating:
Please use alternatives such as official/mnist/dataset.py from tensorflow/models.
2019-12-28 17:02:58.419991: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
WARNING:tensorflow:From D:/AI20/HJZ/04-深度学习/3-CNN/20191207/0502_BN_Lesson上课的.py:141: softmax_cross_entropy_with_logits (from tensorflow.python.ops.nn_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Future major versions of TensorFlow will allow gradients to flow
into the labels input on backprop by default.
See @{tf.nn.softmax_cross_entropy_with_logits_v2}.
100%|██████████| 2000/2000 [00:03<00:00, 634.30it/s]
未使用BN: 训练结束, 最终验证集准确率为 = 0.9168000221252441
100%|██████████| 2000/2000 [00:04<00:00, 414.52it/s]
使用BN: 训练结束, 最终验证集准确率为 = 0.9502000212669373
---------------------------------------------------------------------------
未使用BN: 在完整的测试集上的准确率为 = 0.9090999960899353
---------------------------------------------------------------------------
使用BN: 在完整的测试集上的准确率为 = 0.9527000188827515
Process finished with exit code 0


















 248
248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









