




浩瀚深度([SHA: 688292])旗下企业级大数据平台选择 Apache Doris 作为核心数据库解决方案,目前已在全国范围内十余个生产环境中稳步运行,其中最大规模集群部署于 117 个高性能服务器节点,单表原始数据量超 13PB,行数突破 534 万亿,日均导入数据约 145TB,节假日峰值达 158TB,是目前已知国内最大单表。凭借 Apache Doris 的高可靠、高性能与高可扩展能力,该集群已持续稳定运行半年以上,充分验证了其在超大规模数据场景下的卓越表现。
浩瀚深度作为国内互联网流量解析与数据智能化领域的领军企业,深耕行业三十余载,持续为国内互联网提供高性能、高精度、高可靠的整体解决方案。公司业务覆盖网络可视化、AI 智能、数据治理、数据价值挖掘及安全防护,是一家集软硬件产品研发、生产、销售和服务于一体的大型高科技企业。
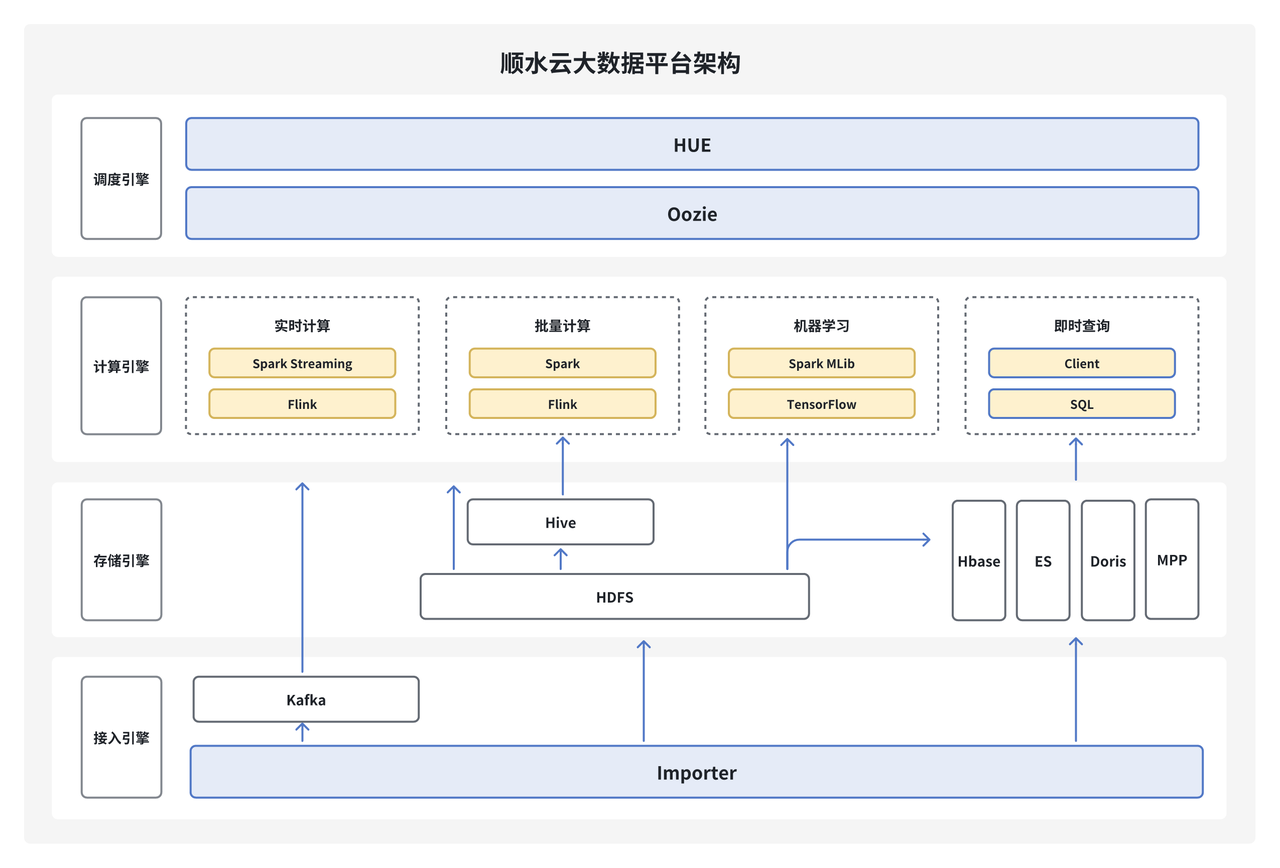
顺水云大数据平台(StreamCloud)作为浩瀚深度自主研发的企业级的大数据平台产品,涵盖了从数据采集、数据存储、数据处理、数据挖掘、数据治理到数据共享的完整数据开发流程。帮助企业客户快速构建 PB 级数据中台,目前已经在通信、金融、交通等领域落地部署 100+ 项目,管理超过 130PB 数据,集群节点规模近万个。
为满足客户每日写入及查询万亿级增量数据的严苛需求,顺水云对 MPP 数据库产品进行了多轮选型测试,并在实际生产环境中尝试过 Greenplum、ClickHouse 等多个方案。经过综合比对,最终选定 Apache Doris 作为核心数据库解决方案。目前,该方案已在全国十余个生产环境上线运行,其中规模最大的集群部署于 117 个高性能服务器节点之上,单表原始数据量超 13PB,行数突破 534 万亿,日均导入数据量约 145TB ,节假日峰值数据量约 158TB,且已持续稳定运行半年以上。
早期架构以及痛点
早期架构如图所示,数据主要来源为用户上网日志,数据经过采集设备解析还原后发送到接口机上,再由接口机上程序接入 HDFS 集群,基于 Apache Spark 将不同类型话单经过加工、回填、合成等流程处理后生成结果数据,最终写入至 ClickHouse 中,用于日志存储与快速查询、流量质量分析、面向政企市场的用户画像 & 精准营销等场景。
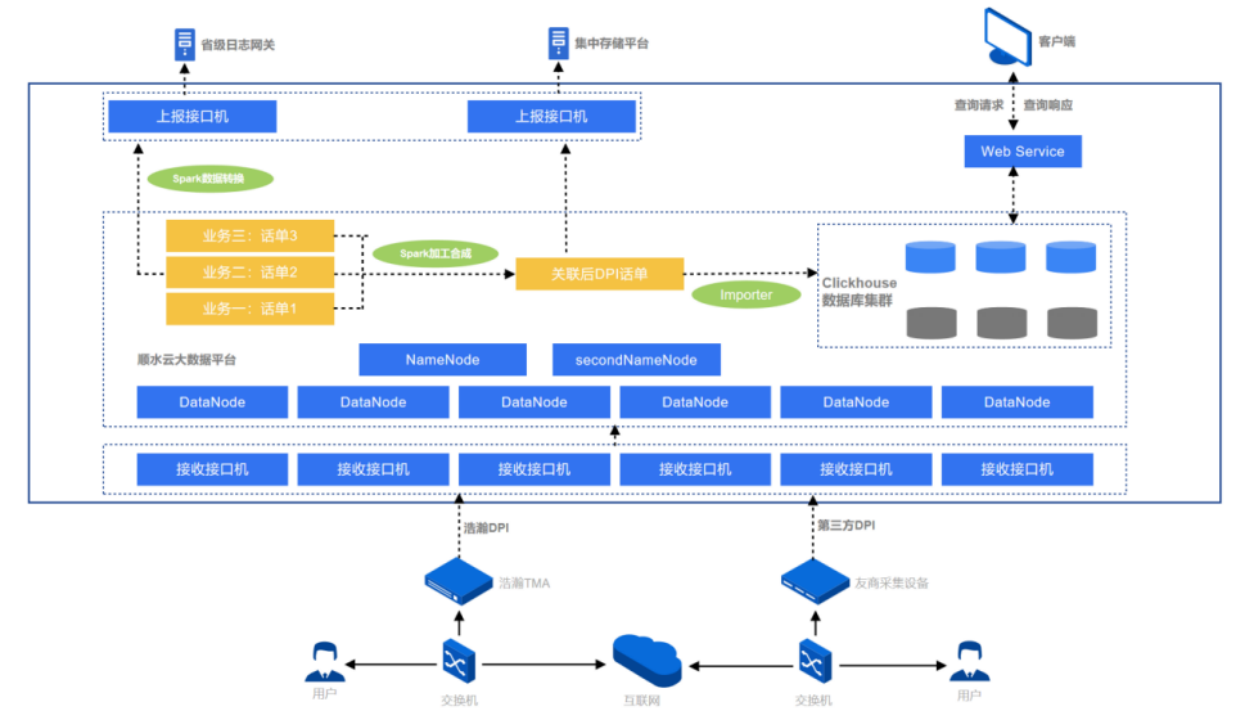
随着业务数据体量逐渐庞大,对于高吞吐的数据写入、亿级数据的秒级响应、海量数据关联查询的需求也愈加迫切,以 ClickHouse 为核心的 OLAP 查询分析引擎体系在使用过程中对业务人员开发、运维人员维护存在如下痛点:
- 写入稳定性差且存储成本较高:为降低存储成本,我们尝试使用 ZSTD 压缩格式,但因其高压缩比带来的性能开销,频繁出现“too many parts”及当日数据入库积压问题。为保障业务稳定运行,只能增加存储成本使用默认的 LZ4 压缩;
- 运维成本高:使用自研的数据入库工具,由于不同接口机上数据量和导入性能差异,导致 ClickHouse 集群上各节点数据量不均衡,由于 ClickHouse 架构特性,坏盘时数据无法自动迁移,需要人工持续干预;
- 并发查询能力不足:在并发查询较多场景下,查询性能下降明显,无法支持业务需求;
- JOIN 能力不足:由于 ClickHouse 自身组件设计无法支持多表或大表 Join 查询场景,难以满足大表关联查询需求。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1124
1124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











