




- 预训练的概念
- 常见的分类预训练模型
- 图像预训练模型的发展史
- 预训练的策略
- 预训练代码实战:resnet18
作业:(1)尝试在cifar10对比如下其他的预训练模型,观察差异,尽可能和他人选择的不同;(2)尝试通过ctrl进入resnet的内部,观察残差究竟是什么
前置——残差连接
- 在深度学习中,模型的层数并不是越深,效果就越好(存在梯度消失、网络退化)。
- 残差连接:让层学习目标映射H(x)与输入x之间的残差F(x) = H(x) - x,简化学习目标
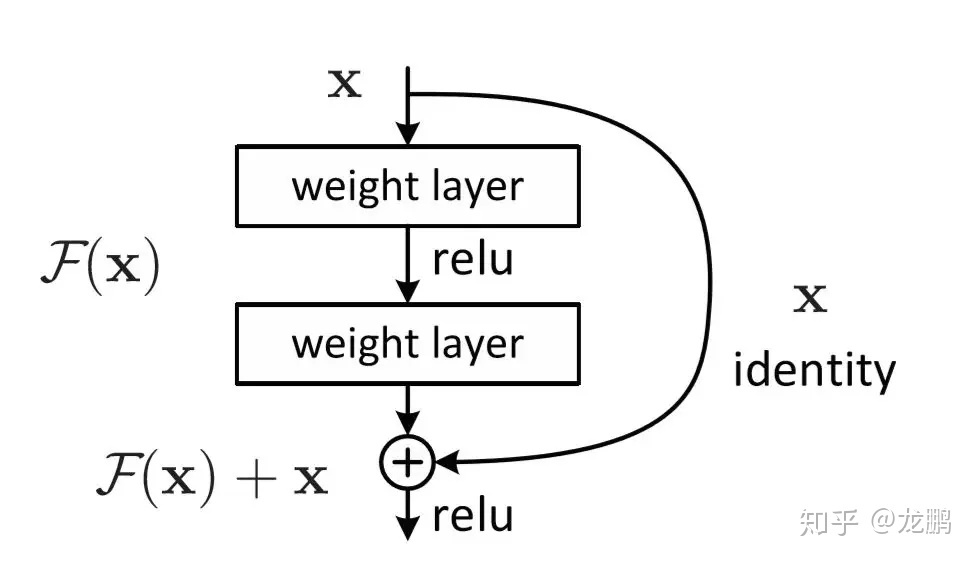
说明:

预训练
预训练:通常指在大规模通用数据集上先训练一个模型,使其学习到广泛的知识或通用的特征表示,然后再将这个模型用于特定任务的微调(Fine-tuning)阶段。
使用预训练的原因:
- 数据效率高并减少训练成本:预训练模型可被多个下游任务复用,节省重复训练的成本。
- 提升泛化能力:预训练让模型掌握语言、图像等领域的通用表示,从而在面对新任务时具备更强的泛化能力。
- 促进迁移学习:模型将从源域(大规模通用数据)学到的知识迁移到目标域(具体任务)。
几个概念:
- 微调:用预训练模型的参数,再在自己数据集上训练来调整该参数的过程
- 迁移学习:模型将从预训练模型学到的知识迁移到自己数据集的思想
- 上游任务:预训练的过程
- 下游任务:微调的过程
说明:(1)要选择类似任务的数据集预训练的模型参数:存在相似特征提取(2)预训练模型要在大规模数据集(比如ImageNet)训练得到:数据量大和尺寸大更易学习到通用特征。
经典预训练模型
(1) CNN架构:AlexNet、VGG16、ResNet18、MobileNetV2。

(2)Transformer类:适用于较大尺寸图像(如224x224),在CIFAR10上需上采样图像尺寸或调整Patch大小。如ViT-Base、Swin Transformer、DeiT。

(3)自监督:无需人工标注,通过 pretext task(如掩码图像重建)学习特征,适合数据稀缺场景

预训练模型发展史
1. CNN架构发展脉络,总体分为三个阶段:

2. 模型架构演进关键点:
- 深度突破:从LeNet的7层到ResNet152的152层,残差连接解决了深度网络的训练难题。
- 计算效率:GoogLeNet(Inception)和MobileNet通过结构优化,在保持精度的同时大幅降低参数量。
- 特征复用:DenseNet的密集连接设计使模型能更好地利用浅层特征,适合小数据集。
- 自动化设计:EfficientNet使用神经架构搜索(NAS)自动寻找最优网络配置,开创了AutoML在CNN中的应用。
3. 预训练模型的选择,使用时可以通过主流框架(如pytorch中的torchvision.model)加载预训练权重,然后迁移学习。

预训练的策略
微调的本质:用预训练模型的结构和训练好的参数,继续训练。
因此,使用预训练时:先选择模型结构并加载模型参数,然后在自己的数据集上继续训练。在这个过程的修改点和注意点:
- 需要resize图片大小,适配模型
- 修改全连接层,适应数据集(比如ImageNet类别为1000,而Cifar-10只有10个类别)
- 开始先冻结特征提取器(卷积层)的参数,只训练全连接层,5-10个epoch后解冻。原因:初始阶段不稳定,可能破坏预训练模型的通用特征提取;全连接层相对稳定后,解冻后进行精细调整,学习独特的领域特征(当前任务)。
预训练代码实战
1.定义模型(使用ResNet18)
支持预训练参数加载,以及全连接层的修改
# 4-定义ResNet18模型
from torchvision.models import resnet18
def create_resnet18(pretrained=True,num_classes=10):
# 加载参数
model = resnet18(pretrained=pretrained)
# 修改全连接层:输出类别数目
in_features = model.fc.in_features # 获取最后一层的输入数目
model.fc = nn.Linear(in_features=in_features,out_features=num_classes) # 修改输出类别数
# 迁移模型
model = model.to(device) # device为全局变量
return model
2.定义冻结/解冻模型层的函数
冻结与解冻逻辑的切换;打印冻结状态(参数数目变化)
# 5-定义冻结/解冻模型层的函数
def freeze_model(model,freeze=True):
# 冻结逻辑
for name,param in model.named_parameters():
if 'fc' not in name:
param.requires_grad = not freeze
# 打印冻结状态
# p.numel()返回张量中元素的个数
frozen_params = sum(p.numel() for p in model.parameters() if not p.requires_grad)
total_params = sum(p.numel() for p in model.parameters())
if freeze:
print('已冻结模型卷积层参数:{}/{} 参数'.format(frozen_params,total_params))
else:
print('已解冻模型所有参数:{}/{} 参数可训练'.format(total_params,total_params))
return model3.创建模型(实例化)
创建完成后,测试单张图片的获取(可以使用iter()迭代器实现单次获取操作)
# 创建ResNet18模型(加载ImageNet预训练权重,不进行微调)
model = create_resnet18(pretrained=True, num_classes=10)
model.eval() # 设置为推理模式,关闭dropout层,固定BatchNorm层的均值和方差
# 测试单张图片(示例)
from torchvision import utils
# 从测试数据集中获取一张图片
dataiter = iter(test_loader) # 创建数据加载器的迭代器,适合单次获取
images, labels = dataiter.next() # 获取一个batch的数据(多个(img,label))
images = images[:1].to(device) # 取第1张图片;: 表示所有通道,:1 表示取第0张图片(保持batch维度)
# 前向传播
with torch.no_grad():
outputs = model(images)
_, predicted = torch.max(outputs, 1)
# 显示图片和预测结果
# utils.make_grid():将张量转换为网格格式用于显示;permute(1, 2, 0):调整维度顺序[H, W, C]
plt.imshow(utils.make_grid(images.cpu(), normalize=True).permute(1, 2, 0))
plt.title(f"预测类别: {predicted.item()}")
plt.axis('off')
plt.show()4.阶段式训练
在之前的训练代码上,加入冻结和解冻的逻辑,实现阶段式训练。
# 6. 训练函数(支持学习率调度器)
def train_with_freeze_schedule(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs,freeze_epochs):
train_loss_history = []
test_loss_history = []
train_acc_history = []
test_acc_history = []
all_iter_losses = []
iter_indices = []
# ----加入冻结逻辑-----------------------------------------------------
if freeze_epochs > 0:
model = freeze_model(model=model)
for epoch in range(epochs):
if epoch == freeze_epochs: # 解冻
model = freeze_model(model,freeze=False)
# 解冻后调整优化器(可选)
#optimizer.param_groups[0]['lr'] = 1e-4 # 降低学习率防止过拟合
# ---------------------------------------------------------------------
model.train() # 设置为训练模式
running_loss = 0.0
correct_train = 0
total_train = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 记录Iteration损失
iter_loss = loss.item()
all_iter_losses.append(iter_loss)
iter_indices.append(epoch * len(train_loader) + batch_idx + 1)
# 统计训练指标
running_loss += iter_loss
_, predicted = output.max(1)
total_train += target.size(0)
correct_train += predicted.eq(target).sum().item()
# 每100批次打印进度
if (batch_idx + 1) % 100 == 0:
print(f"Epoch {epoch+1}/{epochs} | Batch {batch_idx+1}/{len(train_loader)} "
f"| 单Batch损失: {iter_loss:.4f}")
# 计算 epoch 级指标
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = 100. * correct_train / total_train
# 测试阶段
model.eval()
correct_test = 0
total_test = 0
test_loss = 0.0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = output.max(1)
total_test += target.size(0)
correct_test += predicted.eq(target).sum().item()
epoch_test_loss = test_loss / len(test_loader)
epoch_test_acc = 100. * correct_test / total_test
# 记录历史数据
train_loss_history.append(epoch_train_loss)
test_loss_history.append(epoch_test_loss)
train_acc_history.append(epoch_train_acc)
test_acc_history.append(epoch_test_acc)
# 更新学习率调度器
if scheduler is not None:
scheduler.step(epoch_test_loss)
# 打印 epoch 结果
print(f"Epoch {epoch+1} 完成 | 训练损失: {epoch_train_loss:.4f} "
f"| 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%")
# 绘制损失和准确率曲线
plot_iter_losses(all_iter_losses, iter_indices)
plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)
return epoch_test_acc # 返回最终测试准确率5.完整代码
这里使用了函数封装,并定义了main()函数,适合py文件的转换。
# 定义主函数
def main():
# 参数设置
epochs = 40 # 总共的训练轮次
freeze_epochs = 5 # 冻结轮次
lr = 1e-3 # 初始学习率
weight_decay = 1e-4 # 权重衰减:添加L2正则化项惩罚大的权重值,防止过拟合
# 创建resnet18模型
model = create_resnet18(pretrained=True,num_classes=10)
# 创建损失函数、优化器、调度器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(),lr=lr,weight_decay=weight_decay)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer=optimizer,
mode='min',
patience=2,
factor=0.5,
verbose=True # 当学习率发生变化时是否打印提示信息
)
# 训练
print('开始训练')
final_acc = train_with_freeze_schedule(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs,freeze_epochs)
print(f'训练完成!最终测试准确率为:{final_acc:.2f}%')
# # 保存模型
# torch.save(model.state_dict(), 'resnet18_cifar10_finetuned.pth')
# print("模型已保存至: resnet18_cifar10_finetuned.pth")
# 调用主函数
if __name__ == '__main__':
main()
剩下部分完整版:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 1. 数据预处理(训练集增强,测试集标准化)
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(
root='./data',
train=True,
download=True,
transform=train_transform
)
test_dataset = datasets.CIFAR10(
root='./data',
train=False,
transform=test_transform
)
# 3. 创建数据加载器(可调整batch_size)
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 4-定义ResNet18模型
from torchvision.models import resnet18
def create_resnet18(pretrained=True,num_classes=10):
# 加载参数
model = resnet18(pretrained=pretrained)
# 修改全连接层:输出类别数目
in_features = model.fc.in_features # 获取最后一层的输入数目
model.fc = nn.Linear(in_features=in_features,out_features=num_classes) # 修改输出类别数
# 迁移模型
model = model.to(device) # device为全局变量
return model
# 5-定义冻结/解冻模型层的函数
def freeze_model(model,freeze=True):
# 冻结逻辑
for name,param in model.named_parameters():
if 'fc' not in name:
param.requires_grad = not freeze
# 打印冻结状态
# p.numel()返回张量中元素的个数
frozen_params = sum(p.numel() for p in model.parameters() if not p.requires_grad)
total_params = sum(p.numel() for p in model.parameters())
if freeze:
print('已冻结模型卷积层参数:{}/{} 参数'.format(frozen_params,total_params))
else:
print('已解冻模型所有参数:{}/{} 参数可训练'.format(total_params,total_params))
return model
# 6. 训练函数(支持学习率调度器)
def train_with_freeze_schedule(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs,freeze_epochs):
train_loss_history = []
test_loss_history = []
train_acc_history = []
test_acc_history = []
all_iter_losses = []
iter_indices = []
if freeze_epochs > 0:
model = freeze_model(model=model)
for epoch in range(epochs):
if epoch == freeze_epochs: # 解冻
model = freeze_model(model,freeze=False)
# 解冻后调整优化器(可选)
#optimizer.param_groups[0]['lr'] = 1e-4 # 降低学习率防止过拟合
model.train() # 设置为训练模式
running_loss = 0.0
correct_train = 0
total_train = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 记录Iteration损失
iter_loss = loss.item()
all_iter_losses.append(iter_loss)
iter_indices.append(epoch * len(train_loader) + batch_idx + 1)
# 统计训练指标
running_loss += iter_loss
_, predicted = output.max(1)
total_train += target.size(0)
correct_train += predicted.eq(target).sum().item()
# 每100批次打印进度
if (batch_idx + 1) % 100 == 0:
print(f"Epoch {epoch+1}/{epochs} | Batch {batch_idx+1}/{len(train_loader)} "
f"| 单Batch损失: {iter_loss:.4f}")
# 计算 epoch 级指标
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = 100. * correct_train / total_train
# 测试阶段
model.eval()
correct_test = 0
total_test = 0
test_loss = 0.0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = output.max(1)
total_test += target.size(0)
correct_test += predicted.eq(target).sum().item()
epoch_test_loss = test_loss / len(test_loader)
epoch_test_acc = 100. * correct_test / total_test
# 记录历史数据
train_loss_history.append(epoch_train_loss)
test_loss_history.append(epoch_test_loss)
train_acc_history.append(epoch_train_acc)
test_acc_history.append(epoch_test_acc)
# 更新学习率调度器
if scheduler is not None:
scheduler.step(epoch_test_loss)
# 打印 epoch 结果
print(f"Epoch {epoch+1} 完成 | 训练损失: {epoch_train_loss:.4f} "
f"| 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%")
# 绘制损失和准确率曲线
plot_iter_losses(all_iter_losses, iter_indices)
plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)
return epoch_test_acc # 返回最终测试准确率
# 7. 绘制Iteration损失曲线
def plot_iter_losses(losses, indices):
plt.figure(figsize=(10, 4))
plt.plot(indices, losses, 'b-', alpha=0.7)
plt.xlabel('Iteration(Batch序号)')
plt.ylabel('损失值')
plt.title('训练过程中的Iteration损失变化')
plt.grid(True)
plt.show()
# 8. 绘制Epoch级指标曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):
epochs = range(1, len(train_acc) + 1)
plt.figure(figsize=(12, 5))
# 准确率曲线
plt.subplot(1, 2, 1)
plt.plot(epochs, train_acc, 'b-', label='训练准确率')
plt.plot(epochs, test_acc, 'r-', label='测试准确率')
plt.xlabel('Epoch')
plt.ylabel('准确率 (%)')
plt.title('准确率随Epoch变化')
plt.legend()
plt.grid(True)
# 损失曲线
plt.subplot(1, 2, 2)
plt.plot(epochs, train_loss, 'b-', label='训练损失')
plt.plot(epochs, test_loss, 'r-', label='测试损失')
plt.xlabel('Epoch')
plt.ylabel('损失值')
plt.title('损失值随Epoch变化')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
作业
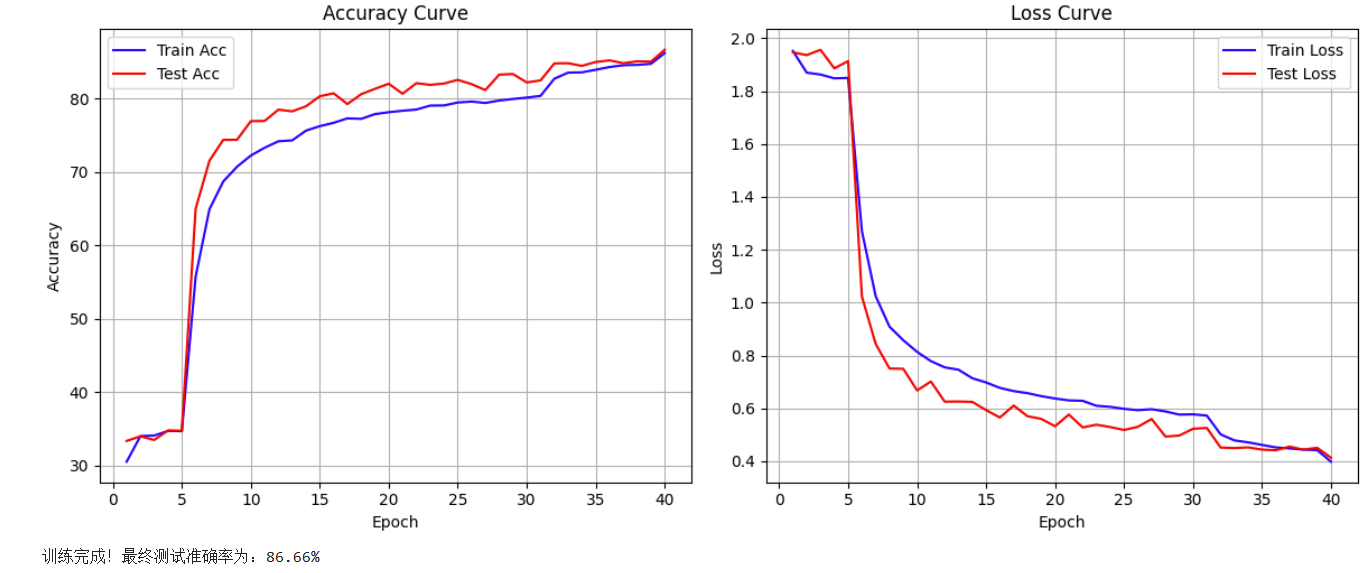
1.对比预训练模型
ResNet18
最终准确率为 86.66 %
from torchvision.models import resnet18
def create_resnet18(pretrained=True,num_classes=10):
# 加载参数
model = resnet18(pretrained=pretrained)
# 修改全连接层:输出类别数目
in_features = model.fc.in_features # 获取最后一层的输入数目
model.fc = nn.Linear(in_features=in_features,out_features=num_classes) # 修改输出类别数
# 迁移模型
model = model.to(device) # device为全局变量
return model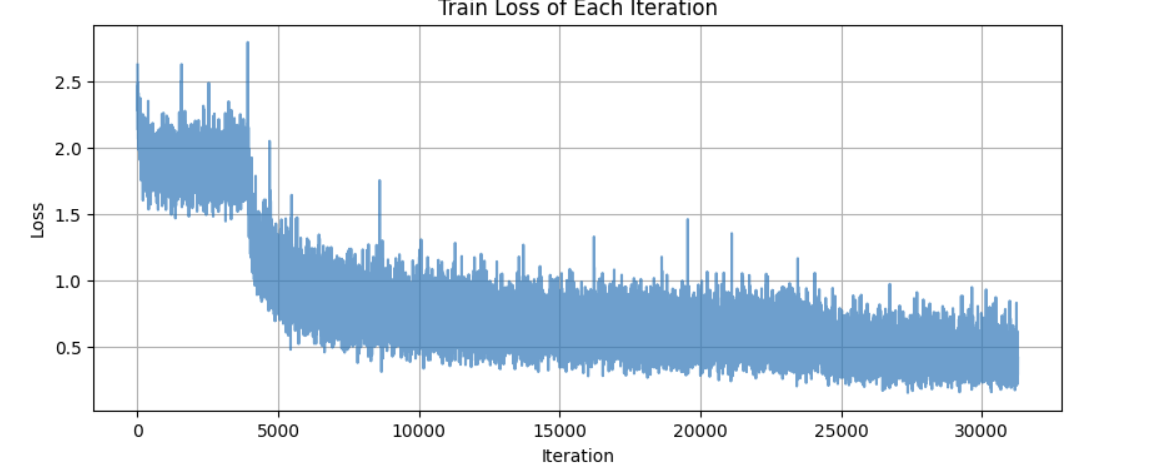
EfficientNet-B0
最终准确率为 88.15 %
from torchvision.models import efficientnet_b0
def create_efficientnet_b0(pretrained=True,num_classes=10):
# 加载参数
model = efficientnet_b0(pretrained=pretrained)
# 修改全连接层:输出类别数目
in_features = model.classifier[1].in_features # 获取最后一层的输入数目
model.classifier[1] = nn.Linear(in_features=in_features,out_features=num_classes) # 修改输出类别数
# 迁移模型
model = model.to(device) # device为全局变量
return model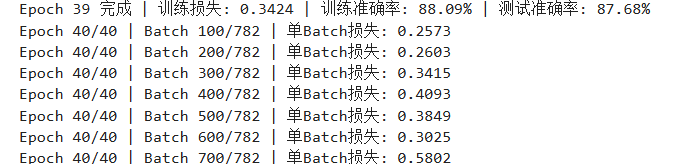
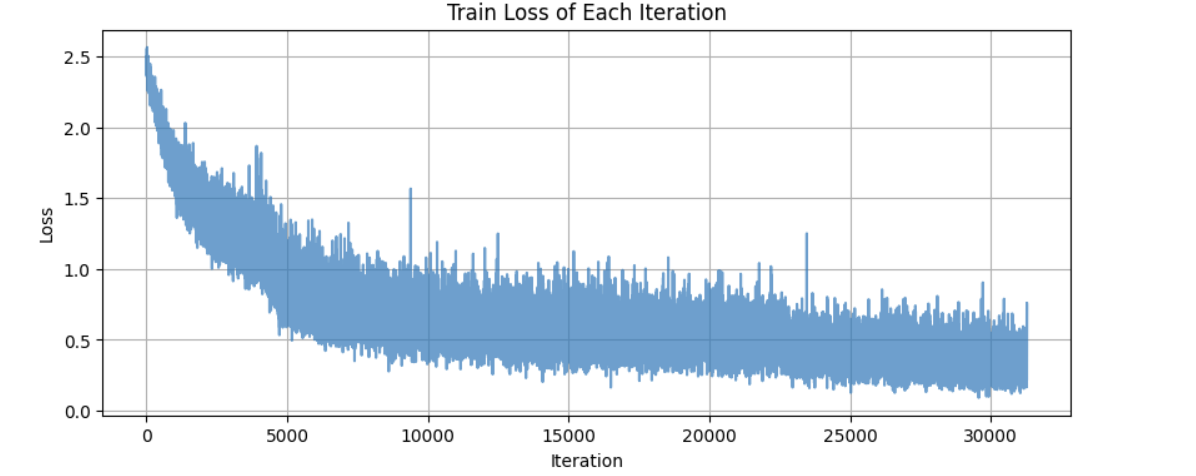
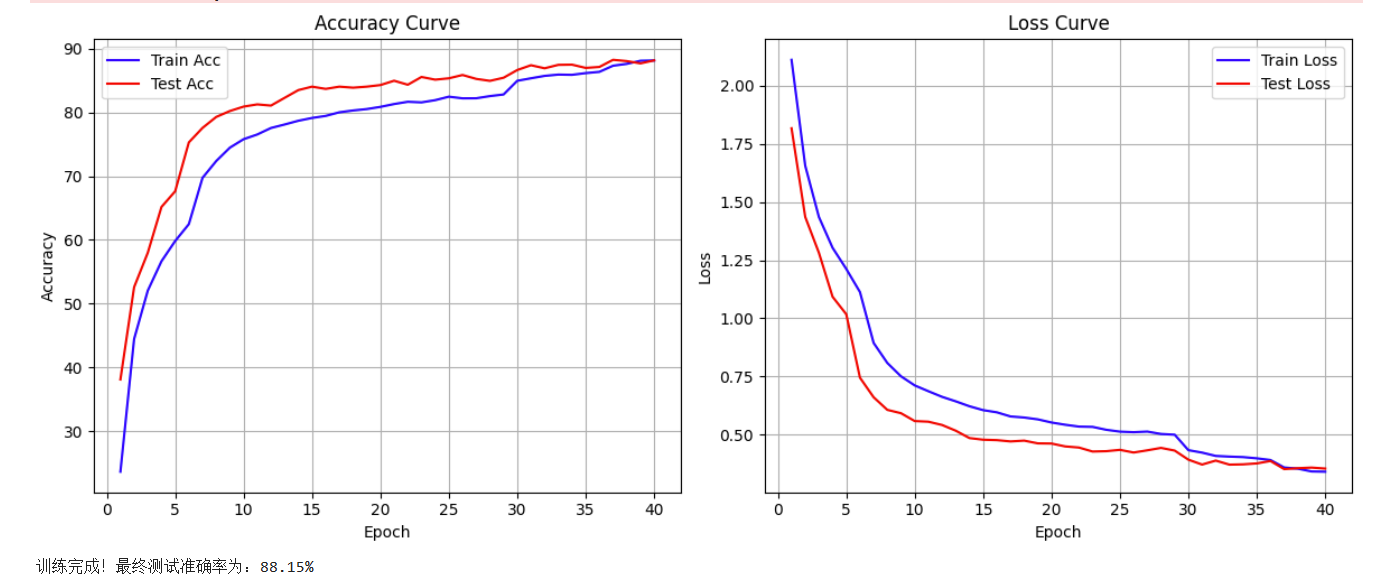
2.ResNet内部
通过ctrl进入resnet内部,找到残差块:
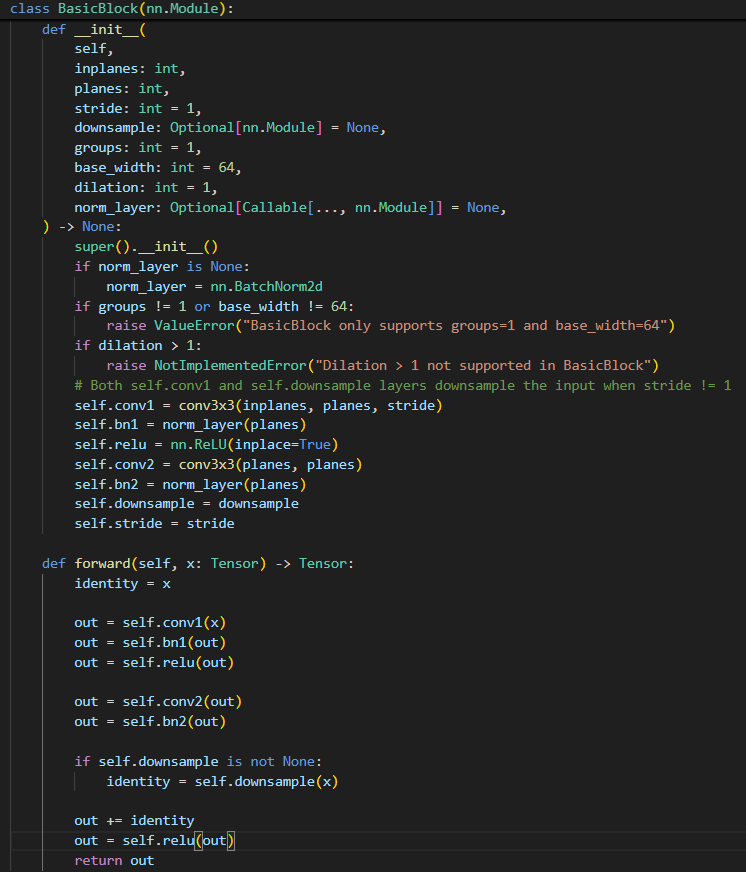
在前向传播中,可以看到x会走两条路:
- 主路:经过一些权重层(比如两个卷积层),我们将其整体看作是在学习残差函数
F(x)。 - 捷径:直接“跳跃”过这些层,保持为
x本身。 - 然后主路和捷径两者相加:H(x)=F(x) + x,最后经过激活函数输出。


















 749
749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









