 图像数据与显存占用分析
图像数据与显存占用分析





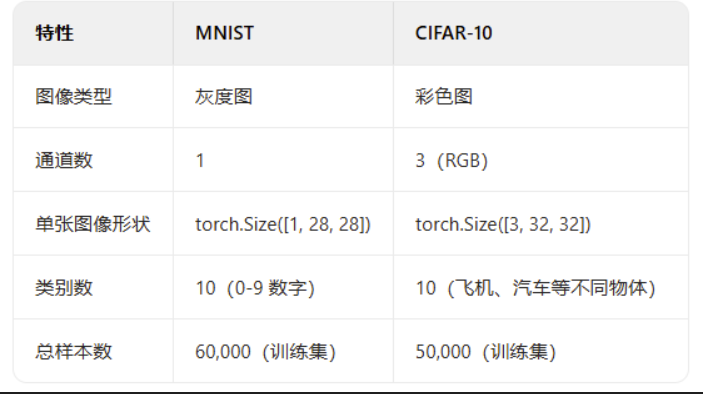
- 图像数据的格式:灰度和彩色数据
- 模型的定义
- 显存占用的4种地方:模型参数+梯度参数;优化器参数;数据批量所占显存;神经元输出中间状态
- batchisize和训练的关系
一、图像数据的介绍
结构化数据的形状是(样本数,特征数),而图像数据的形状是(通道数,高度,宽度)。下面是对图像数据形状的三个维度索引的说明:
- 0:通道数,如灰度图的取值为1(1个颜色通道),彩色图(RGB)取值为3
- 1:高度,图像的垂直像素数值
- 2:宽度,图像的水平像素数值
1.1 灰度数据
以Mnist手写数据为例,它是黑白照片,所以通道数为1。图像尺寸为28*28像素。因此它的图像数据形状为(1,28,28)。
# 打印下图片的形状
image.shape
# 输出 torch.Size([1, 28, 28])关于黑白图像的显示,注意单通道图像在imshow中输入(height,width)
# 加载数据,创建dataset
# 取出图片
idx = torch.randint(0,len(train_dataset),size=(1,)).item() # 转换为标量
image,label = train_dataset[idx]
# 可视化
def imshow(img):
img = img*0.3081 + 0.1307 # 反标准化
nping = img.numpy() # 转换为numpy数组
# 单通道,nping[0]即(高度,宽度);cmap指定颜色映射为灰色
plt.imshow(nping[0],cmap='gray')
plt.show()
print('Label:{}'.format(label))
imshow(image)1.2 彩色数据
以cifar-10数据为例,彩色照片,图像尺寸为32*32像素,故而图像数据的形状为(3,32,32)。
# 打印图片形状
print(f"图像形状: {image.shape}")
# 输出: torch.Size([3, 32, 32])注意:在使用imshow图像显示时,维度的顺序需要调整为(高度,宽度,通道数)(Channel Last)。实现的方法是np.transpose()。
# 加载数据,创建dataset
# 取出图片
idx = torch.randint(0,len(train_dataset),size=(1,)).item()
image,label = train_dataset[idx]
# 可视化
def imshow(img):
img = img*0.5 + 0.5 # 反标准化
nping = img.numpy() # 转换为numpy数组
plt.imshow(np.transpose(nping,(1,2,0))) # 调整维度顺序
plt.axis('off') # 关闭坐标轴显示
plt.show()
print('Label:{}'.format(label))
imshow(image)
1.3 小结
对于灰度图和彩色图来说,区别在颜色通道数上:灰度图为1,彩色图(标准RGB)为3。当然,通道数的取值并布仅仅局限于1和3,还可以取4(RGB+Alpha)、10(多光谱)等。
此外,由于通道数的不同,灰度图和彩色图在使用imshow进行可视化显示的时候,也有一定的区别:维度顺序(channel last),若为单通道则隐藏通道数(仅高度和宽度)。
二、MLP模型定义(图像相关)
图像数据的MLP模型定义整体上与结构化数据的定义类似,但需要一个额外的步骤:将图像数据展平为一维向量的格式输入。这是因为MLP要求输入层是一维向量,而图像是二维结构。
2.1 黑白图像的模型定义
# 定义MLP——黑白图像
class MLP(nn.Module):
def __init__(self,input_size=784,hidden_size=128,num_classes=10):
super(MLP,self).__init__()
self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量
self.layer1 = nn.Linear(input_size,hidden_size) # 第一层:784个输入,128个神经元
self.relu = nn.ReLU() # 激活函数
self.layer2 = nn.Linear(hidden_size,num_classes) # 第二层:128个输入,10个输出(10个类别)
def forward(self,x):
x = self.flatten(x) # 展平图像
out = self.layer1(x) # 第一层线性变换
out = self.relu(out) # 应用ReLU激活函数
out = self.layer2(out) # 第二层线性变换,输出logits
return out
# 实例化
model = MLP()
# 设置设备
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
# 查看模型可视化
from torchsummary import summary
summary(model,input_size=(1,28,28)) # 输入尺寸为MNIST图像尺寸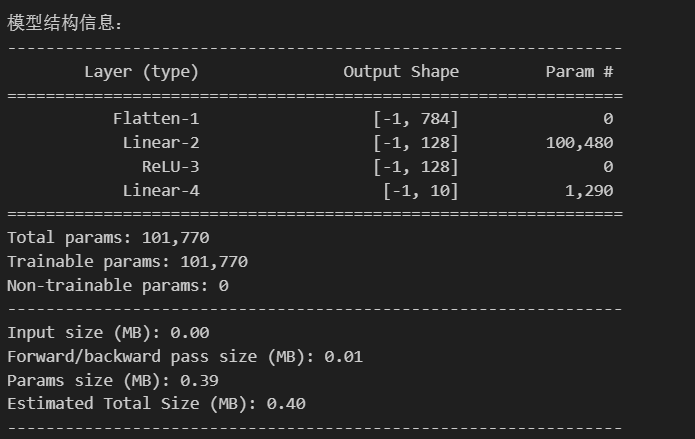
参数计算,权重和偏置:

2.2 彩色图像的模型定义
类似地,得到彩色图像的模型定义:
# 定义MLP——彩色图像
class MLP(nn.Module):
def __init__(self,input_size=3072,hidden_size=128,num_classes=10):
super(MLP,self).__init__()
self.flatten = nn.Flatten() # 将3*32*32的图像展平为784维向量
self.layer1 = nn.Linear(input_size,hidden_size) # 第一层:3072个输入,128个神经元
self.relu = nn.ReLU() # 激活函数
self.layer2 = nn.Linear(hidden_size,num_classes) # 第二层:128个输入,10个输出(10个类别)
def forward(self,x):
x = self.flatten(x) # 展平图像:[batch, 3, 32, 32] → [batch, 3072]
out = self.layer1(x) # 第一层线性变换:[batch, 3072] → [batch, 128]
out = self.relu(out) # 应用ReLU激活函数
out = self.layer2(out) # 第二层线性变换:[batch, 128] → [batch, 10]
return out
# 实例化
model = MLP()
# 设置设备
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
# 查看模型可视化
from torchsummary import summary
summary(model,input_size=(3,32,32)) # 输入尺寸为CIFAR-10 彩色图像(3×32×32)
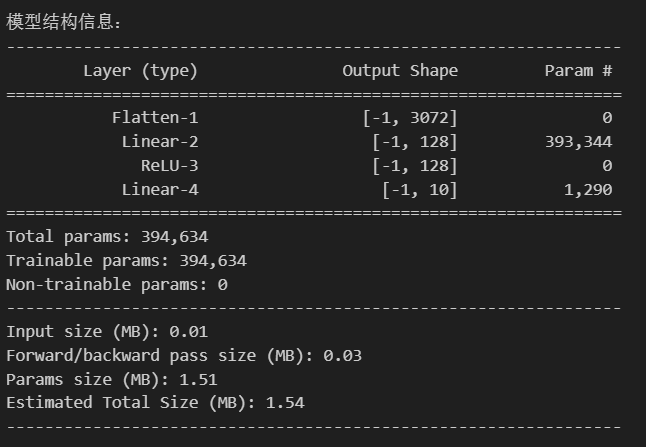
参数计算:

2.3 小结
根据上面的例子,与前面的结构化数据相比,可以发现以下差异:
(1)输入前需要先进行展平操作。有两种实现方法:一是定义flatten方法,二是在前向传播中使用x = x.view(-1, 28 * 28) 将图像展平为一维向量
(2)输入数据的尺寸(input_size)包含了通道数:(3,32,32)
三、显存占用的4种地方
在面对数据集过大的情况下,由于无法一次性将数据全部加入到显存中,所以采取了分批次加载这种方式。即一次只加载一部分数据,保证在显存的范围内。
那么显存设置多少合适呢?如果设置的太小,那么每个batchsize的训练不足以发挥显卡的能力,浪费计算资源;如果设置的太大,会出现OOM(out of memory)
显存占用的主要组成部分包括模型参数、梯度、优化器状态和中间结果等。
首先需要知道单位换算:1 Byte = 8 bit,1 KB = 1024 Byte,1 MB=1024 KB。其中位(bit)是二进制数的最小单位。下面是常见数据类型的字节占用:
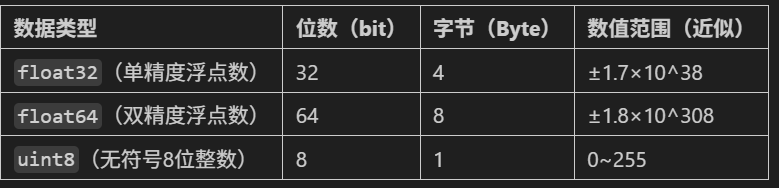
以Mnist手写数据集为例,计算显存占用。
3.1 模型参数与梯度参数
由于PyTorch的transforms.ToTensor()会将数据归一化到[0, 1]范围,并转换为 float32类型(浮点型更适合神经网络计算),因此:
- 模型参数:计算公式:参数数量
× 4字节(float32) - 梯度:损失函数对模型参数的导数,用于指示参数更新的方向和幅度,大小与模型参数相同
- 总计:(101770 * 4 + 101770 * 4 )/ 1024 = 795 KB
3.2 优化器参数
部分优化器(如 Adam)会为每个参数存储动量(Momentum)和平方梯度(Square Gradient),进一步增加显存占用:
- 动量(m):每个参数对应一个动量值,数据类型与参数相同(float32)。
- 梯度平方(v):每个参数对应一个梯度平方值,数据类型与参数相同(float32)。
- 每个参数存储 m 和 v ,占用约 101,770 × 4 × 2 / 1024 = 795 KB
3.3 数据批量
数据批量(batch_size)大小对显存的占用影响较大。
- 单张图像尺寸显存占用:1 * 28 *28 * 4 = 3136 Byte = 3.06 KB
- 批量数据占用:batach_size * 单张图像占用,如 1024*3136 / (1024*1024) = 3.06 MB
3.4 中间变量
当MLP层数较少时,中间变量的占用较少:
- batch_size×128维向量:batch_size×128×4 Byte = batch_size×512 Byte
- 例如batch_size=1024时,中间变量约 512 KB
四、总结
(1)介绍了黑白图像和彩色图像,关于它们的形状、模型定义等有了了解。
(2)batch_size的说明
首先,batch_size与模型定义无关,因为batch_size在数据加载阶段(dataloader)定义。

此外,batch_size 对于训练的影响。batch_size在显存支持的情况下,要尽量大,因为:
-
并行计算能力最大化,减小训练时间;且大幅减少更新次数
-
梯度方向更准确:单样本训练的梯度仅基于单个数据点,可能包含大量噪声(尤其是数据分布不均或存在异常值时)。大 batch_size 的梯度是多个样本的平均值,能抵消单个样本的随机性,梯度方向更接近真实分布的 “全局最优方向”,让训练过程更稳定
(3)关于显存大小设置:
一是对于大规模数据,通常从batch_size=16开始测试,然后逐渐增加,确保代码运行正常且不报错,直到出现内存不足(OOM)报错或训练效果下降,此时选择略小于该值的 batch_size。
二是训练时候搭配 nvidia-smi 监控显存占用,合适的 batch_size = 硬件显存允许的最大值 × 0.8(预留安全空间),并通过训练效果验证调整。

















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









