







数学建模学习-奇异值分解(Singular Value Decomposition)教程(21)
写在最前
注意本文的相关代码及例子为同学们提供参考,借鉴相关结构,在这里举一些通俗易懂的例子,方便同学们根据实际情况修改代码,很多同学私信反映能否添加一些可视化,这里每篇教程都尽可能增加一些可视化方便同学理解,但具体使用时,同学们要根据实际情况选择是否在论文中添加可视化图片。
系列教程计划持续更新,同学们可以免费订阅专栏,内容充足后专栏可能付费,提前订阅的同学可以免费阅读,同时相关代码获取可以关注博主评论或私信。
目录
算法简介
奇异值分解(Singular Value Decomposition,简称SVD)是线性代数中最重要的矩阵分解方法之一。它可以将任意矩阵分解为三个特殊矩阵的乘积:一个正交矩阵U、一个对角矩阵Σ和另一个正交矩阵V的转置。SVD在数据压缩、降维、推荐系统等领域有着广泛的应用。
算法特点
- 普适性:SVD可以应用于任意大小和任意类型的矩阵,包括非方阵。
- 稳定性:SVD分解是数值稳定的,对于接近奇异的矩阵也能得到合理的结果。
- 最优性:在许多应用中,SVD能够提供最优的低秩近似。
- 可解释性:奇异值的大小直接反映了对应特征的重要性。
- 计算复杂度:对于m×n的矩阵,SVD的计算复杂度为O(mn·min(m,n))。
数学原理
对于任意m×n矩阵A,其SVD分解可以表示为:
A = UΣV^T
其中:
- U是m×m正交矩阵,其列向量称为左奇异向量
- Σ是m×n对角矩阵,对角线上的元素称为奇异值,按从大到小排列
- V^T是n×n正交矩阵的转置,V的列向量称为右奇异向量
奇异值的重要性质:
- 奇异值都是非负实数
- 奇异值的平方等于A^T·A的特征值
- 奇异值的数量等于矩阵的秩
- 奇异值的大小反映了对应特征的重要程度
代码实现
环境准备
首先需要安装必要的Python库:
# requirements.txt
numpy>=1.21.0
matplotlib>=3.4.0
scikit-learn>=0.24.0
pillow>=8.0.0
图像压缩示例
下面是一个使用SVD进行图像压缩的示例代码:
def compress_image(k):
"""使用SVD进行图像压缩"""
# 创建示例图像数据
x = np.linspace(0, 4*np.pi, 100)
y = np.linspace(0, 4*np.pi, 100)
X, Y = np.meshgrid(x, y)
image = np.sin(X) + np.cos(Y)
# 进行SVD分解
U, s, Vt = np.linalg.svd(image)
# 使用前k个奇异值重构图像
reconstructed = np.zeros_like(image)
for i in range(k):
reconstructed += s[i] * np.outer(U[:, i], Vt[i, :])
# 绘制原始图像和重构图像的对比
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
im1 = ax1.imshow(image, cmap='viridis')
ax1.set_title('原始图像')
plt.colorbar(im1, ax=ax1)
im2 = ax2.imshow(reconstructed, cmap='viridis')
ax2.set_title(f'使用前{k}个奇异值重构的图像')
plt.colorbar(im2, ax=ax2)
plt.savefig(os.path.join('images', f'compression_k{k}.png'))
plt.close()
return s
数据降维分析
使用SVD进行数据降维分析的示例代码:
def analyze_digits():
"""使用SVD分析手写数字数据集"""
# 加载手写数字数据集
digits = load_digits()
X = digits.data
# 进行SVD分解
U, s, Vt = np.linalg.svd(X)
# 计算累积解释方差比
explained_variance_ratio = np.cumsum(s**2) / np.sum(s**2)
# 绘制累积解释方差比
plt.figure(figsize=(10, 5))
plt.plot(range(1, len(explained_variance_ratio) + 1),
explained_variance_ratio, 'b-', marker='o')
plt.axhline(y=0.9, color='r', linestyle='--', label='90% 阈值')
plt.title('SVD累积解释方差比')
plt.xlabel('奇异值数量')
plt.ylabel('累积解释方差比')
plt.grid(True)
plt.legend()
plt.savefig(os.path.join('images', 'explained_variance.png'))
plt.close()
return explained_variance_ratio
运行结果分析
图像压缩结果

从上图可以看出,使用前10个奇异值就能较好地重构原始图像。这说明SVD能够有效地捕捉图像中的主要特征。
奇异值分布
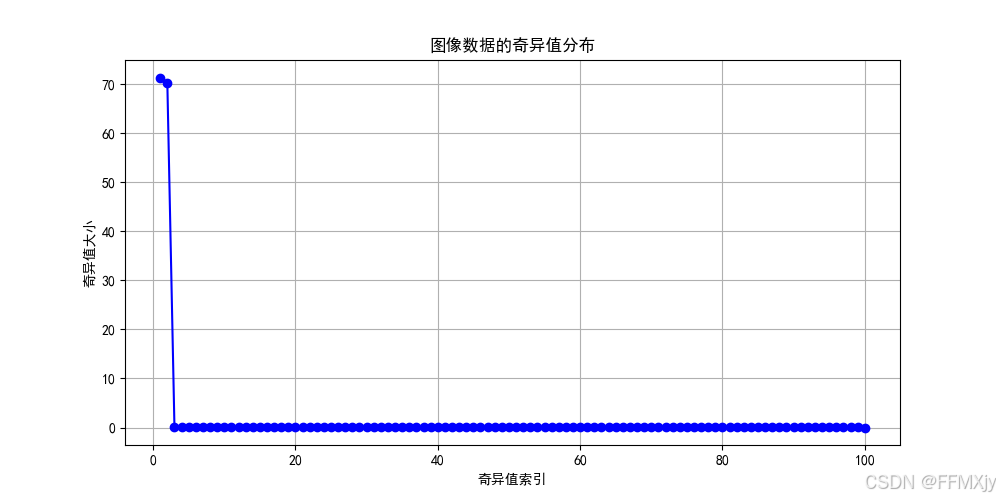
奇异值的分布呈现明显的衰减趋势,这表明数据中存在明显的主成分结构。
累积解释方差

从累积解释方差图可以看出:
- 使用前9个奇异值就能解释90%的数据方差
- 方差解释率的增长呈现边际递减的趋势
- 这表明我们可以通过保留少量重要的奇异值来实现有效的降维
实际应用场景
-
图像压缩
- 通过保留主要奇异值来压缩图像
- 可以显著减少存储空间
- 在可接受的失真度下实现数据压缩
-
推荐系统
- 用户-物品评分矩阵的降维
- 发现潜在特征
- 预测用户偏好
-
数据降维
- 降低数据维度
- 消除噪声
- 提取主要特征
-
信号处理
- 信号去噪
- 特征提取
- 模式识别
-
文本分析
- 潜在语义分析(LSA)
- 文档聚类
- 信息检索
注意事项
-
计算复杂度
- 对于大型矩阵,SVD的计算可能较为耗时
- 需要根据实际情况选择合适的降维程度
- 考虑使用随机化SVD等近似算法
-
奇异值选择
- 奇异值数量的选择需要权衡精度和效率
- 可以通过累积解释方差比来确定
- 需要考虑具体应用场景的要求
-
数据预处理
- 进行SVD之前需要对数据进行适当的预处理
- 考虑数据的中心化和标准化
- 处理缺失值和异常值
-
数值稳定性
- 对于接近奇异的矩阵要特别注意
- 考虑使用数值稳定的SVD算法
- 可能需要进行数值调整
-
内存消耗
- 对于大型矩阵需要注意内存使用
- 考虑使用增量式或在线SVD算法
- 可能需要进行数据分块处理
同学们如果有疑问可以私信答疑,如果有讲的不好的地方或可以改善的地方可以一起交流,谢谢大家。


















 5249
5249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









