




 本文详细描述了在英伟达Jetson平台上使用YOLOv8系列(n、m版本)进行目标检测的过程,包括模型训练时间、处理图片耗时、效果对比以及在视频中的应用。重点讨论了不同规模模型的性能差异和速度指标。
本文详细描述了在英伟达Jetson平台上使用YOLOv8系列(n、m版本)进行目标检测的过程,包括模型训练时间、处理图片耗时、效果对比以及在视频中的应用。重点讨论了不同规模模型的性能差异和速度指标。
接上篇英伟达Jetson搭建Yolov8环境过程中遇到的各种报错解决(涉及numpy、scipy、torchvision等)以及直观体验使用Yolov8目标检测的过程(CLI命令行操作、无需代码)-优快云博客的进一步测试,只是好奇,建议浏览一下就行,不需要浪费时间走一遍这个流程。
主要内容:
- yolov8n.pt和yolov8m.pt的训练时间;
- yolov8n.pt和yolov8m.pt处理一张图片的耗时;
- yolov8n.pt和yolov8m.pt目标检测的效果对比;
- 尝试对视频.mp4文件进行目标检测;
1、YOLOv8提供的各种模型
YOLOv8 - Ultralytics YOLOv8 文档
YOLOv8提供了基于目标检测、实例分割、姿态检测、分类等不同类型,不同规格的模型,后缀n、s、m、l、x代表模型的规模逐渐增大。
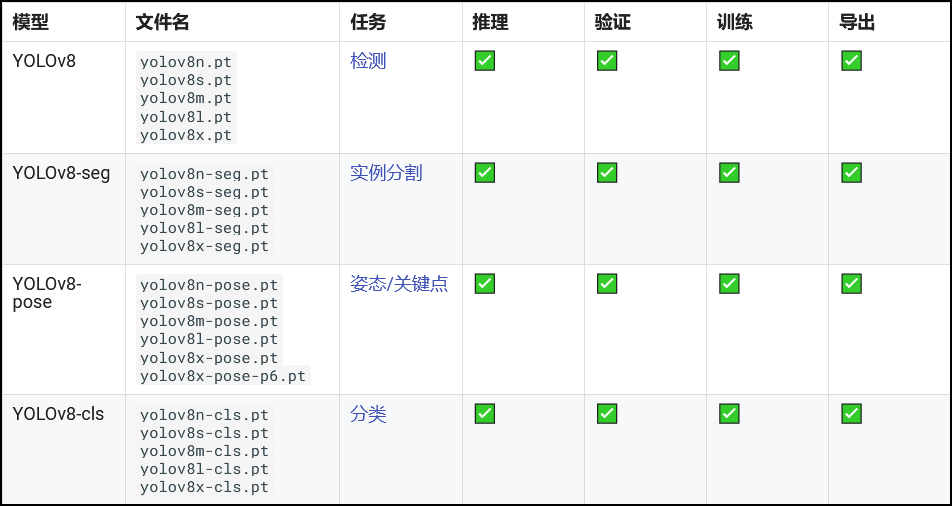
不同的模型的性能见下表:
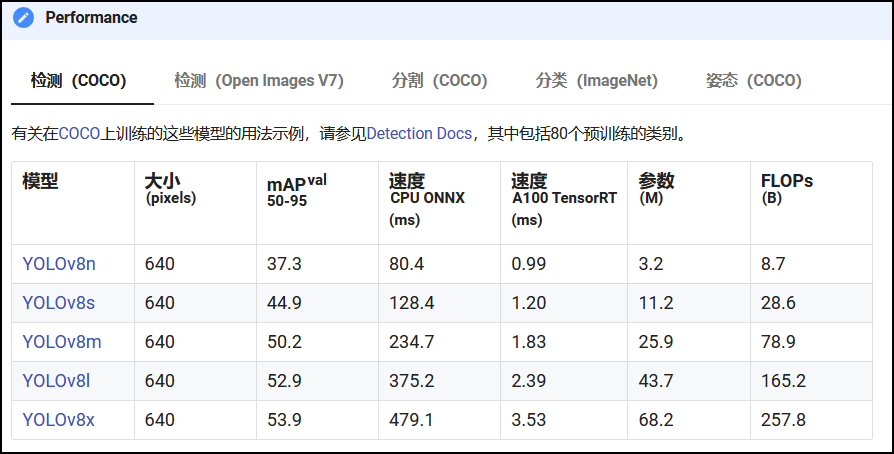
关于mAPval 50-95:
- Precision,精确度,代表预测为正的样本中有多少正确;
- Recall,召回率,代表真正为正的样本中有多少被预测为正;
- AP(Average Precision),平均精度,综合考虑精确度Precision和召回率Recall;
- mAP(mean Average Precision),多个类别下,平均精度AP的均值。
- mAPval (mean Average Precision on the validation set),在验证集上的mAP。
- IOU(Intersection overUnion),交并比,“预测的边框”和“真实的边框”的交集/并集,为1代表完全重叠;
- mAPval 50-95,代表在验证集上IOU=50~95之间的mAP;
关于速度:
- CPU ONNX指的是在CPU下,使用ONNX这个模型格式推理的速度;
- A100 TensorRT指的是在英伟达A100显卡GPU下,使用TensorRT推理的速度;
所以总结下就是,模型越大,效果越好,但推理的时间也越久;
2、yolov8n.pt和yolov8m.pt的训练时间
2.1、yolov8n.pt的训练时间
yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.01训练10次耗时0.376小时≈22分钟。

2.2、yolov8m.pt的训练时间
yolo train data=coco128.yaml model=yolov8m.pt epochs=10 lr0=0.01如果只是把yolov8n.pt改成yolov8m.pt,且运行设备的内存不够大(我用的是8G内存),就会出现刚开始训练就终止Killed的问题,像这样:
![]()
减小batch可以解决这个问题,默认是batch=16,我修改成batch=4之后可以正常训练,batch=-1是可以自动适配硬件这个还没有尝试。
yolo train data=coco128.yaml model=yolov8m.pt epochs=10 lr0=0.01 batch=4训练的过程中打开jtop,关于安装jtop及可能遇到的问题在这里Jetson Orin Nano_安装jtop指令(遇到循环提示重启服务的问题)、查看系统运行情况及基本信息-优快云博客。
可以从下图看到,即便是batch=4,6个CPU基本满负荷,内存占用大概是5.5/7.4≈74%.
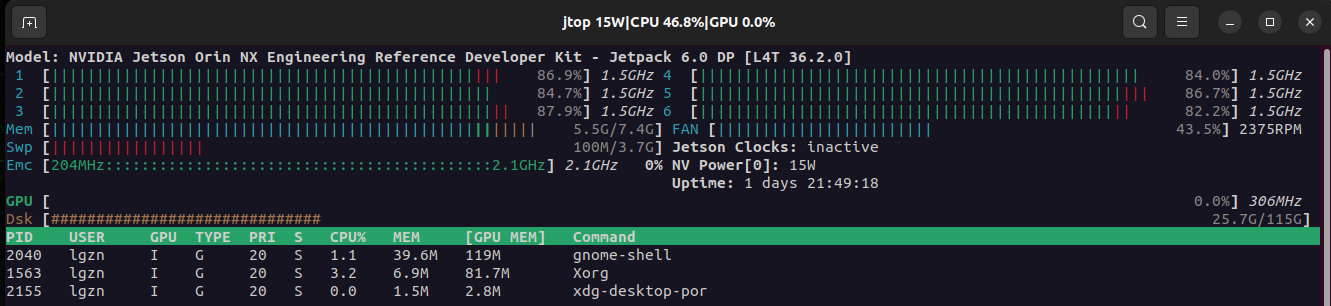
最终跑完,一共耗时1.9个小时。

3、yolov8n.pt和yolov8m.pt处理一张图片的耗时
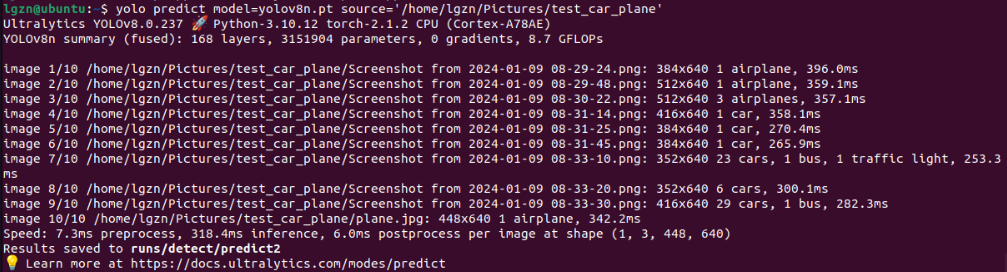
3.1、yolov8n.pt处理一张图片的耗时
一共有10张图片,平均预处理preprocess=7.3ms,推理interence=318.4ms,后处理postprocess=6ms,总计331.7ms;
3.2、yolov8m.pt处理一张图片的耗时
同样的这10张图片,平均预处理preprocess=5.6ms,推理interence=1135.1ms,后处理postprocess=3.4ms,总计1144.1ms,差不多是yolov8n.pt的3.5倍。
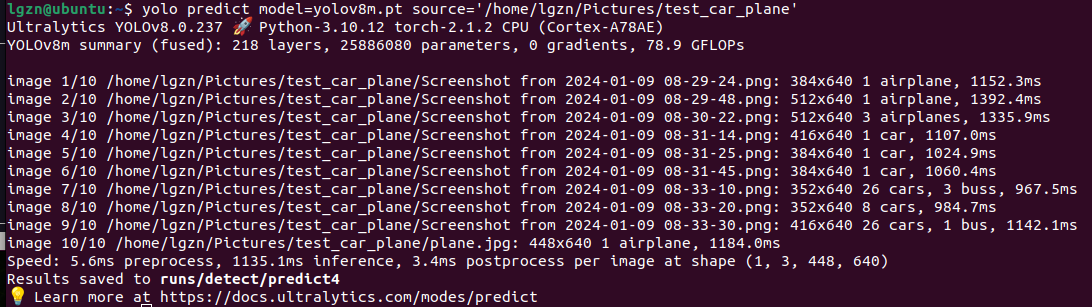
4、yolov8n.pt和yolov8m.pt目标检测的效果对比
yolo predict model=yolov8n.pt source='/home/lgzn/Pictures/test_car_plane'yolo predict model=yolov8m.pt source='/home/lgzn/Pictures/test_car_plane'对比来说yolov8m.pt效果确实明显要好,比如下图识别出car的置信度变高了,还多识别出2个bus,错误识别的traffic light也没有了。


5、尝试对视频.mp4文件进行目标检测
对图片、视频的检测并没有很大的不同,只是修改个识别的来源source:
yolo predict model=yolov8m.pt source='/home/lgzn/Pictures/video_test/ollie.mp4'因为看到训练的日志class里面有person和skateboard这两个类别,所以试试看这个video,skateboard识别出来了并且置信度是0.9,满意。
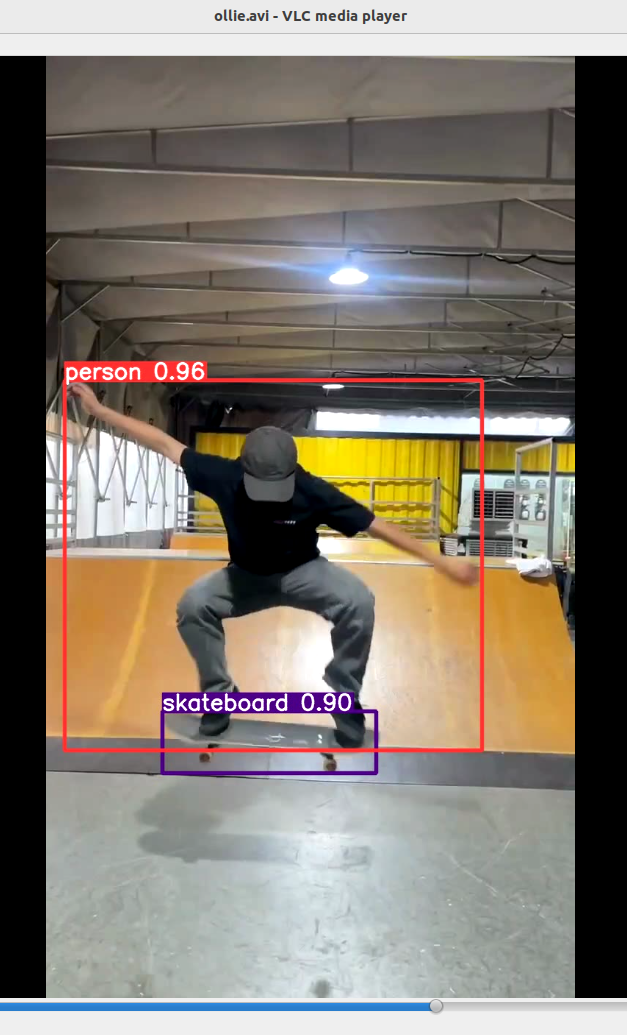
总有一天,我的ollie会过障碍,然后一立、两立;

















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









