



Datawhale分享
作者:冰冰,知乎
作者:冰冰,一个着迷于数学的软件工程研究僧
来源:https://zhuanlan.zhihu.com/p/1941384271051854082
昨天睡前和朋友聊天,他讲到自己接到老板的一个需求,让他根据不同的数据集和 tokenizer 作为输入,去估计训练时长要多久。
看到这个问题,我激情输出了十来分钟,经过了大概两轮的输出,最终确定了该怎么去做这件事情。
下面就简单说说想法吧,顺便把自己的想法给完善一下,这边主要说的是 SFT,RL 的情形太复杂了,主包算不明白。
训练时长这件事情,可以抽象成一个非常简单的公式:

如果能够把分子分母的两个量全都计算出来,就可以把训练时长给估计出来。那问题就变成了怎么把这两个量给求出来。
此处就不去考虑各种诸如 TP,PP,DP,EP,CP 这些模型并行的策略了,我只是大概了解基于 All-Reduce、All-Scatter 和 All-Gather 的通信/并行概念,但并不知道这些并行方式底层的通信方式和所需的通信量。
而且,如果要考虑这些因素的话,可能还需要考虑单机内和多机之间的通信模式,完全在我的能力范围之外了。
把上面的那个数算出来,就已经能估计出训练时长的下界,将将够用。最后无非就是基于 PCIE 来做卡间通信会更慢点,用 NVLINK 连的话就会更快点。
一、显卡算力计算
首先看分母上的那个量,这个其实很简单,每秒的总算力就是:
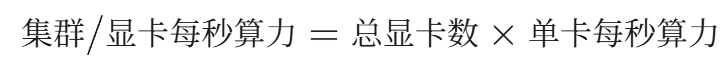
这个东西还是很好算的,以单机 8 卡为例,在 FP16 的精度下,各种卡的 TFLOPS 大概是长这样的:
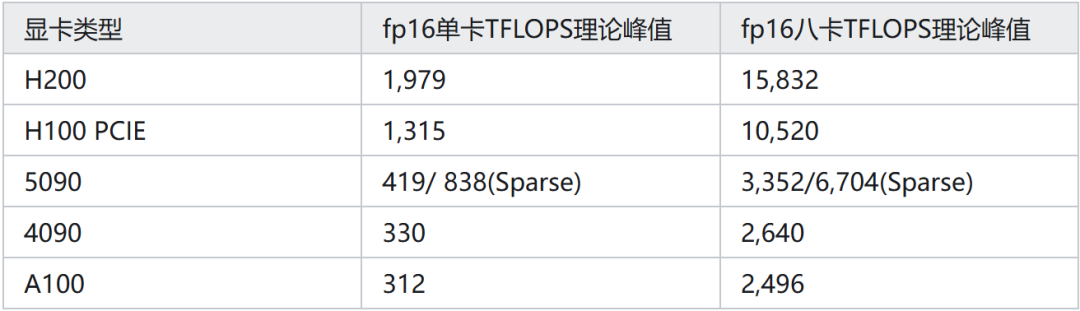
上面大概覆盖了主流的一些卡的 fp16 算力,查表就可以用。
另外,因为现在训练的时候通常使用混合精度训练(Mixed Precision),前向传播/反向传播的时候用 fp16,在用 Optimizer 做 gradient accumulation 的时候,通常要用 FP32 做累加。
为了考虑进这个因素,我问了下 GPT5,他给我的回复是:专业的计算卡做过优化,算 fp32 的时候,速度不会掉点;
但是像 5090 这样的消费级显卡,做 fp32 的 accumulation 时会掉一半的性能。【若 GPT5 回答的有闪失,谢谢大佬指正】这个在计算时要注意一下。
二、训练所需的总计算量
接着就要来计算训练所需的总计算量了,这个东西我琢磨了一下,大概会和以下几个东西有关系:Epoch 数,模型大小,数据集的 token 数还有 tokenizer 效率。
Epoch 数应该是当中最简单的因素,一个 Epoch 要多少的计算量,有了多个 Epoch 之后,直接乘以 Epoch 数就行了:

这个时候再对每 Epoch 的计算量做计算,在模型训练阶段所需要考虑的两个因素:
数据集有多少 token;
模型前向传播+反向传播所需计算量。
数据集有多少 token 这很好统计,主要还是要考虑第二个问题,对于这个问题,在 OpenAI 2020 年的文章 Scaling Law 里早有记载:
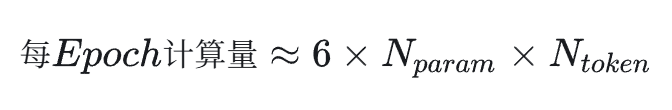
其中,6 这个系数可以拆成两个部分,前向传播占用了其中的 2 份,反向传播因为要两倍的计算量,所以占用了其中的 4 份。
用这个公式的话,就不用再考虑很多零碎的细节,像 hidden_size、head_nums 和 dim_head 统统不用考虑,拿来就用,非常开心。
GPT5 告诉我,GPT3 和 Chinchilla 等工作都是用这个来估算的。
这个东西算完以后,就要考虑一个问题,怎么根据数据集来确认总 token 数呢?
这个数据完全是跟着 tokenzier 来的,但又不可能为了算一个数据集就去对着数据集 tokenize 一遍,这个太费劲了。
所以,根据上面的套路,这个地方适合用某种方法预处理出来一个量,我打算管这个玩意叫 tokenizer 效率,衡量了 tokenizer 的压缩率;可以是 token per 每个字,也可以是 token per byte。
总之把这个数据给估算出来,就可以拿这个值直接去算一个数据集可能会分成多少个 token 了。
因为每家的用自己的语料做出来的 tokenizer 不太一样,所以需要预处理一下每个 tokenizer 的效率。
这里呢,我大概想到了两种做法:
第一种,这种就比较粗暴,直接用一批数据去做 tokenize,把 tokenize 完得到的 token 数去除以字符串长度/byte 数,就可以得到 tokenizer 的效率;
第二种,如果希望估计得更加精细的话,可以用线性回归去拟合一个值出来,其中 y 是句子的 token 数量,x 是句子长度/byte 数。
至于为啥我在这边要老提 byte 数,因为不同的字符对应的 byte 数是不一样的,英文字符的话使用 ASCII 码,一般就 1 个字节,但是像中文单字的话,一般会使用 3-4 个字节来表示。
基于 BPE 的 tokenizer,是预处理了在一批语料中最常见的 Byte Pair 作为词表去做 tokenize 的。
这也就导致了像中文这样的单字,有时可能会被拆成好几个 token,看过词表的 uu 们应该都知道,在那个表里面是找不到中文单字的,而且经常能看到一些长相非常奇怪的字符串。
我觉得,从 byte 层面进行估算,会更精确些(大概)。至于用来算 tokenizer 效率的这样一个数据集,多样性要强一点,尽量把整个词表都覆盖一下。
不过,你也可以完全当我前面是在放 X,直接用经验法则去估计:1个英文字母差不多等于 3/4 个 token,一个中文字约等于 1 个 token。
到这边,整个估算流程就差不多齐活了,整个过程可以浓缩成下面这样一个公式:

反正挨个把数据套进去,训练时长的下界就可以被估算出来了。很方便啊,很方便。估算过程就到这边为止了。
三、幺蛾子想法x1
然后,在思考这个问题问题的时候,我回想起前天在看 Kimi K2 技术报告时突发奇想到的一个幺蛾子问题:
是否可以通过这份开源的技术报告里公布的训练细节去反推出厂商能够多少张卡?
这个问题我觉得还是非常有意思的,当时想搁置一下慢慢研究的;我当时的思路就是,可能需要根据开源报告里提出的各种并行策略,参数设置去推断。
但是,当我昨天把上面那个问题琢磨出来以后,就发现一个更加简单的估算方法:报告里通常会把 Epoch 数,模型参数,还有训练的 token 总量放出来。
如果他还大发慈悲地把训练时长也公布出来,那直接除一除不就可以得到集群的算力了嘛。
至于在 PP 之间可能会产生气泡,我看他们都在尽量压缩气泡的大小,那直接当作没气泡的状况去估计得了,糙一点也不是什么坏事。
至于这个东西有啥用,我刚想到一个比较有意思的用途。可以去看一个大厂里不同的组做出来的模型都用到了多少张卡,也可以间接估计这个组在公司里的地位怎么样,对于找工作的各位可能有一定的参考价值罢(x
这边就先写到这里,之后可能会密集更新很多自己的幺蛾子想法和学习心得,我发现和评论区的网友 battle 能够帮助我去思考一些平时没有思考到的问题,在 battle 的过程中还是能学到很多的东西的,输出为王!
感谢你看到这儿 ^^

一起“点赞”三连↓


















 6694
6694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









