



Datawhale干货
作者:王大鹏,Datawhale成员
当你与 DeepSeek 对话,它能够理解问题并给出恰当回答时,你是否想过这种"理解"是如何实现的?
这背后源于一个经典问题:如何让机器将一个序列转换为另一个序列?,也就是 Seq2Seq(Sequence-to-Sequence)问题,以及解决这个问题的经典架构——Transformer。
Seq2Seq 本质上是一类问题的抽象描述,而不是特定的模型架构,就像"分类问题"描述的是从输入到类别标签的映射,"Seq2Seq 问题"描述的是从一个序列到另一个序列的转换。
机器翻译中将 Hello 翻译为你好,文本摘要将长文章压缩为核心要点,对话系统理解问题并给出回答,代码生成将自然语言描述转化为程序代码,都是 Seq2Seq 问题的应用。
在 Transformer 出现之前,业界主要使用基于 RNN 的 Encoder-Decoder 架构:
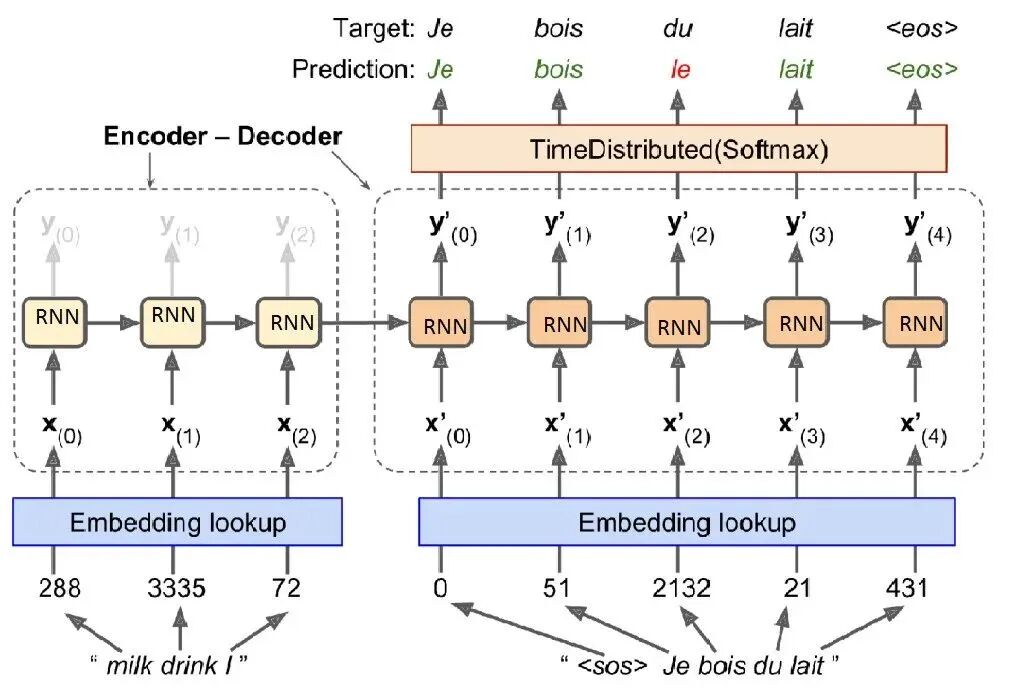
以翻译任务举例,这种方法的思路很直观:从一个起始状态开始,每一步基于当前的理解状态(隐状态)和已生成的内容,预测并生成下一个词,然后更新理解状态,如此循环直到生成完整的文本。
但 RNN 方案存在根本性问题:Encoder 阶段需要把所有信息都要压缩到固定长度的向量中,由于串行处理的梯度消失问题,RNN 无法捕捉到长距离的依赖关系。
2017 年,《Attention Is All You Need》提出了完全基于注意力机制的 Transformer 架构,Transformer 沿用了经典的 Encoder-Decoder 结构,但不再是时间步长的依赖。
Encoder 的任务是理解输入序列,将其转换为富含语义信息的表示。每个 Encoder 层包含两个核心组件:多头自注意力+前馈神经网络。

自注意力机制让每个位置都能"看到"序列中的所有其他位置。以句子"The cat sat on the mat"为例:理解"cat"时,模型会关注"The"(确定是哪只猫),理解"sat"时,模型关注"cat"(谁在坐)和"on the mat"(坐在哪里)。
多头注意力进一步扩展了这种能力:每个头都有自己独立的参数矩阵,用来关注不同类型的关系,所有头并行计算,最终将多个头的结果合并。以句子"大鹏在北京的工作是计算机"为例,句子中会包含多种关系,"大鹏"和"工作"是主谓关系,"北京"和"工作"是地点关系,"工作"和"计算机"是性质关系,每个头关注不同的关系,最终合并。
数学表达式为:Attention(Q,K,V) = softmax(QK^T/√d_k)V,QK^T 来计算查询和键的相似度,除以 √d_k 用于缩放,避免梯度消失。softmax 转化为概率分布,最终乘以V根据注意力权重加权求和。
在每个注意力层之后,都有一个前馈神经网络(FFN)。这个组件流程很简单:放大->筛选->压缩。在 GPT3 中,FFN将 12288 维向量放大 4 倍至 49152 维,应用 ReLU 激活函数进行非线性变换,重新压缩回 12288 维。通过在放大过程中提取丰富特征,在压缩过程中保留有用信息。这里有个 trick 点是:当我们知道需要完成某种复杂的信息变换来做提取,但不知道具体的数学公式时,可以使用神经网络来学习这种变换。
残差连接是为了解决深层网络训练中的梯度消失问题,表达式为:output = LayerNorm(x + SubLayer(x)),在梯度计算时:∂output/∂x = ∂(x + SubLayer(x))/∂x = 1 + ∂SubLayer(x)/∂x,即使 ∂SubLayer(x)/∂x 变得很小(接近 0),总梯度也不会完全消失,因为至少还有 1 存在。
层归一化在残差连接之后执行,层归一化会先将输入标准化为均值 0、标准差 1,然后通过可学习参数调整到最适合的分布,避免梯度消失或爆炸。层归一化的公式为:LN(x) = γ * (x - μ) / σ + β,反向传播的梯度计算时:∂LN/∂x = γ/σ * (1 - 1/d - (x-μ)²/(d*σ²)),1 确保了梯度不会完全消失,-1/d 防止梯度因为均值计算被过度缩放,-(x-μ)²/(d*σ²) 用来减小梯度,防止输入值偏离均值大。
Decoder 的结构相比 Encoder 更加复杂,因为它不仅要理解,还要生成,它主要有三个核心组件:掩码多头注意力+多头交叉注意力+前馈神经网络。

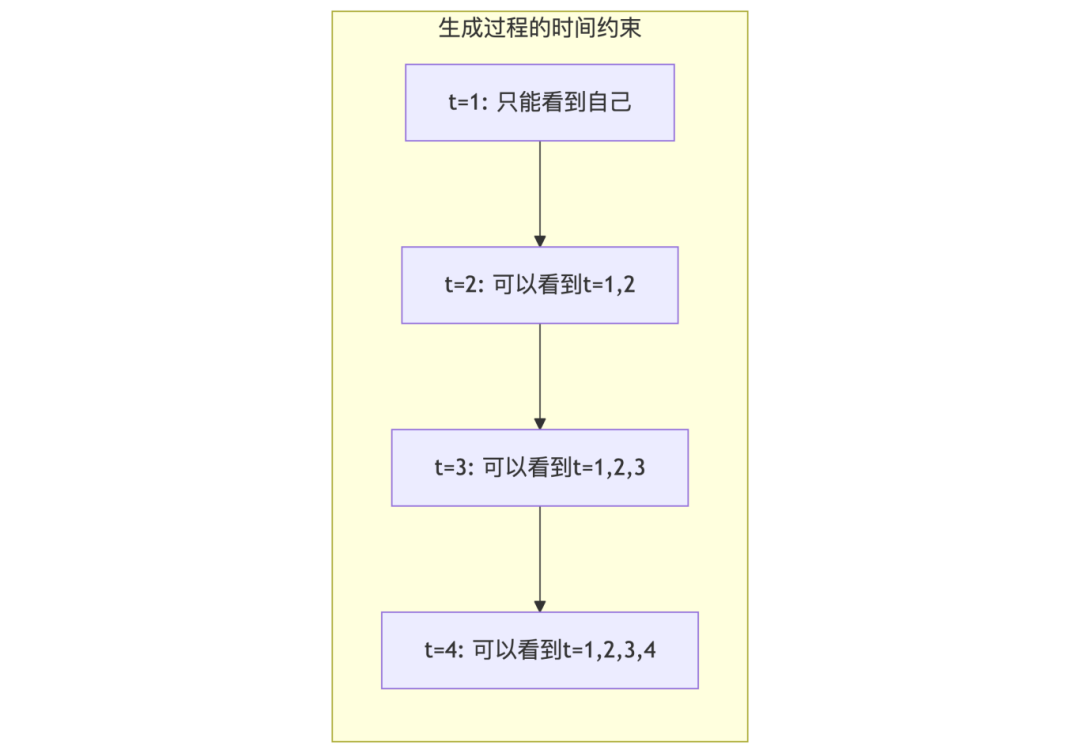
在生成任务中,模型不能"偷看"未来的信息。掩码机制确保每个位置只能关注当前及之前的位置,这使得 Decoder 特别适合生成任务。掩码注意力在标准的自注意力实现中加上了掩码:MaskedAttention(Q,K,V) = softmax((QK^T + Mask)/√d_k)V,掩码矩阵会用负无穷来填充,这样经过softmax函数,掩码位置在注意力中的权重就为 0,不会对结果造成影响。通过掩码模拟了真实的生成过程,即使训练时有完整的目标序列,也要模拟逐步生成的过程,位置 i 只能关注位置 i 前面的。推理时本就逐步生成,天然满足掩码的约束。
交叉注意力让 Decoder 能够关注 Encoder 的输出,实现了理解到生成的信息传递:
CrossAttention(Q_decoder,K_encoder,V_encoder)=softmax(Q_decoder × K_encoder^T/√d_k) × V_encoder,但要注意交叉注意力存在于早期的 Encoder-Decoder 架构,现代的 Decoder-Only 模型(GPT3)舍弃了交叉注意力的模块,只使用掩码机制。
在 GPT3 中,Decoder 就堆叠了 96 层,每层完整的结构是:多头自注意力->残差连接 + 归一化->前馈神经网络->残差连接 + 归一化。
参考:
1. Datawhale Happly-LLM
地址:https://datawhalechina.github.io/happy-llm/#/./chapter2/%E7%AC%AC%E4%BA%8C%E7%AB%A0%20Transformer%E6%9E%B6%E6%9E%84?id=_22-encoder-decoder

一起“点赞”三连↓


















 7031
7031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









