




FROM
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
我的环境
- 语言环境:Python 3.11.9
- 开发工具:Jupyter Lab
- 深度学习环境:
- torch==2.3.1+cu121
- torchvision==0.18.1+cu121
一、导入数据
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
from torchvision import datasets
import torchvision.models as models
import torch.nn.functional as F
import torch.nn as nn
import torch,torchvision
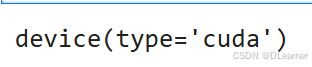
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
输出:
1. 获取类别名
import os,PIL,random,pathlib
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
data_dir = './015_licence_plate/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
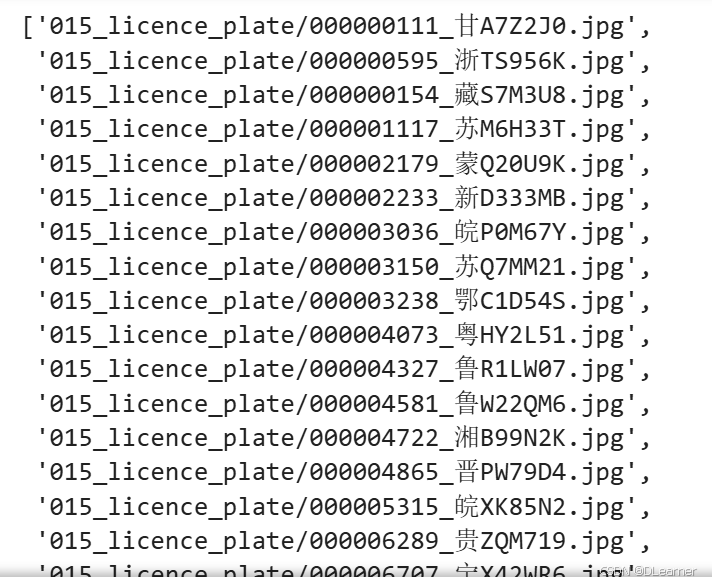
classeNames = [str(path).split("/")[1].split("_")[1].split(".")[0] for path in data_paths]
print(classeNames)
输出:

data_paths = list(data_dir.glob('*'))
data_paths_str = [str(path) for path in data_paths]
data_paths_str
输出:
2.数据可视化
plt.figure(figsize=(14,5))
plt.suptitle("数据示例(K同学啊)",fontsize=15)
for i in range(18):
plt.subplot(3,6,i+1)
# plt.xticks([])
# plt.yticks([])
# plt.grid(False)
# 显示图片
images = plt.imread(data_paths_str[i])
plt.imshow(images)
plt.show()
输出:

3. 标签数字化
import numpy as np
char_enum = ["京","沪","津","渝","冀","晋","蒙","辽","吉","黑","苏","浙","皖","闽","赣","鲁",\
"豫","鄂","湘","粤","桂","琼","川","贵","云","藏","陕","甘","青","宁","新","军","使"]
number = [str(i) for i in range(0, 10)] # 0 到 9 的数字
alphabet = [chr(i) for i in range(65, 91)] # A 到 Z 的字母
char_set = char_enum + number + alphabet
char_set_len = len(char_set)
label_name_len = len(classeNames[0])
# 将字符串数字化
def text2vec(text):
vector = np.zeros([label_name_len, char_set_len])
for i, c in enumerate(text):
idx = char_set.index(c)
vector[i][idx] = 1.0
return vector
all_labels = [text2vec(i) for i in classeNames]
4. 加载数据文件
import os
import pandas as pd
from torchvision.io import read_image
from torch.utils.data import Dataset
import torch.utils.data as data
from PIL import Image
class MyDataset(data.Dataset):
def __init__(self, all_labels, data_paths_str, transform):
self.img_labels = all_labels # 获取标签信息
self.img_dir = data_paths_str # 图像目录路径
self.transform = transform # 目标转换函数
def __len__(self):
return len(self.img_labels)
def __getitem__(self, index):
image = Image.open(self.img_dir[index]).convert('RGB')#plt.imread(self.img_dir[index]) # 使用 torchvision.io.read_image 读取图像
label = self.img_labels[index] # 获取图像对应的标签
if self.transform:
image = self.transform(image)
return image, label # 返回图像和标签
total_datadir = './03_traffic_sign/'
# 关于transforms.Compose的更多介绍可以参考:https://blog.youkuaiyun.com/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std =[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = MyDataset(all_labels, data_paths_str, train_transforms)
total_data
5.划分数据
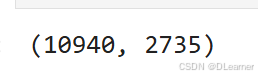
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_size,test_size
输出:
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=16,
shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset,
batch_size=16,
shuffle=True)
print("The number of images in a training set is: ", len(train_loader)*16)
print("The number of images in a test set is: ", len(test_loader)*16)
print("The number of batches per epoch is: ", len(train_loader))
输出:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









