



今天是2025年12月5日,星期五,珠海,天气晴
继续看技术进展,看RAG进展,看一个组合式多模态RAG总结性梳理,看看这块有哪些思路。
另一个是知识图谱构建进展,看看一个分割+抽取+验证做知识图谱构建思路-OntoMetric
多总结,多归纳,**多从底层实现分析逻辑,**会有收获。
一、组合式多模态RAG总结性梳理
RAG作为一种范式,可以灵活扩展,可以来个暴力组合,写综述。变成从文本RAG到多模态输入-文本输出,再到多模态输入-多模态输出的一个演进。
看几个点。
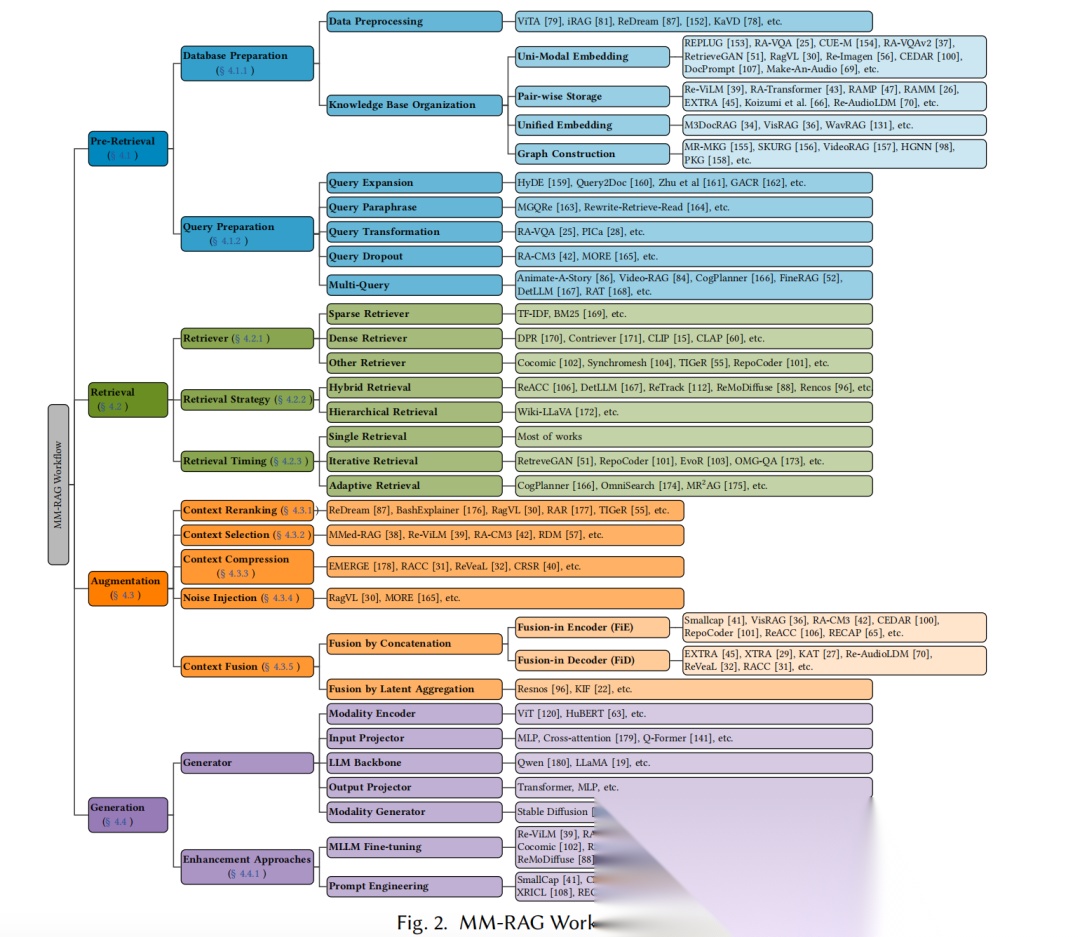
1、看不同输入输出组合的代表方案

2、看核心流程
如下所示,看看几个核心流程:
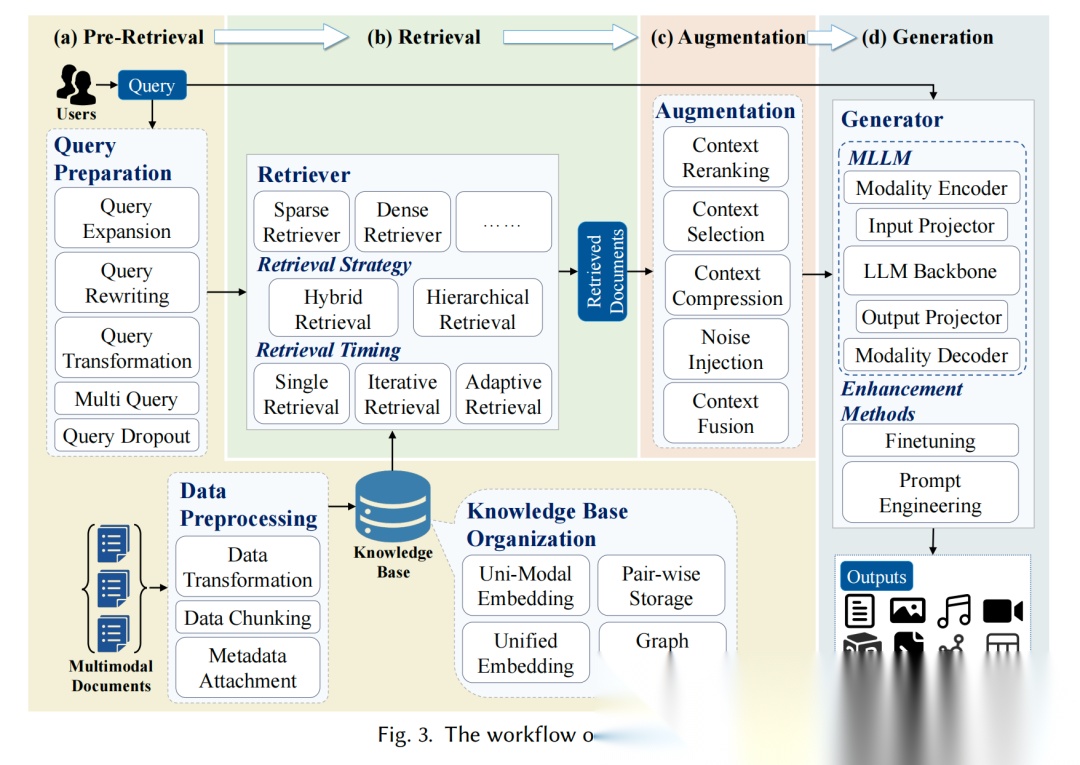
预检索阶段,关键操作是知识库准备(4种组织方式:单模态嵌入、成对存储、统一嵌入、图构建)和查询准备(5种优化技术:扩展、改写、转换、dropout、多查询);
检索阶段,关键操作是检索器选择(稀疏、密集、其他3类)、策略制定(混合、分层等)和时机控制(单次、迭代、自适应3种),常用方法包括BM25、CLIP、混合检索;
增强阶段,关键操作是上下文处理(重排序、选择、压缩)和优化(噪声注入、融合),常用方法有FiE(编码器内融合)、FiD(解码器内融合);
生成阶段,关键操作是生成器构建(5大组件)和增强(提示工程、MLLM微调),常用方法包括StableDiffusion(图像生成)、LoRA微调。
3、看训练策略
训练策略分为两类。
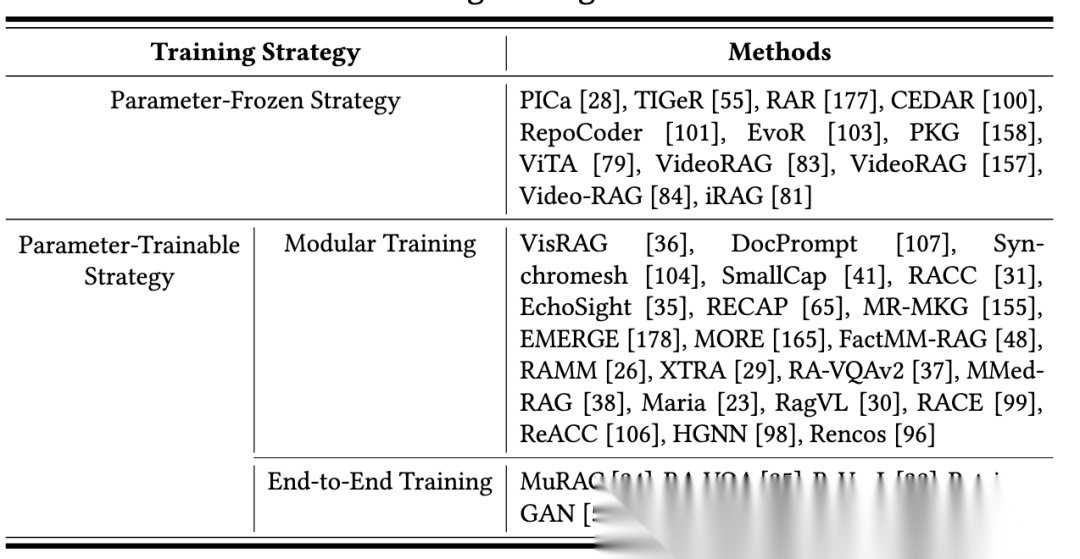
一类是参数冻结策略:直接复用现成模块,无参数更新,适用场景为快速部署、数据标注不足或低计算资源环境,代表研究有PICa、VideoRAG,优势是训练成本低、组件复用性强,劣势是任务适配性有限;
一类是参数可训练策略:包含模块化训练(独立优化各组件,适用场景为需针对性提升特定组件性能的场景,代表研究有VisRAG、RACC,优势是灵活度高、易维护,劣势是组件协同性不足)和端到端训练(联合优化检索器与生成器,适用场景为追求最优系统性能的场景,代表研究有RA-VQA、ReVeaL,优势是性能最优,劣势是计算成本高、部署灵活度差)。
二、分割+抽取+验证做知识图谱构建思路-OntoMetric
继续看一个知识图谱构建的思路,背景是SASB、TCFD、IFRSS2等框架要求企业报告大量ESG指标,相关规则嵌入长文本、非结构化PDF,包含定义、公式、单位等复杂信息,但是人工提取耗时、易错、难以应对框架更新。传统自动化关键词匹配/手工规则缺乏语义覆盖,无法处理复杂依赖。
无约束LLM提取容易出现实体不一致、关系幻觉、缺失溯源,验证失败率高,现有ESG本体又仅含形式化schema,缺乏自然语言描述。
所以,可以细分下实现,拆成多步。
具体的看这个工作《OntoMetric: An Ontology-Guided Framework for Automated ESG Knowledge Graph Construction》(https://arxiv.org/pdf/2512.01289),搞了一套“自动把ESG政策文档变成规整可用的知识图谱”的流程,核心是用“先拆分、再提取、后校验”的思路解决“文档乱、提取不准、没法审计”的问题。
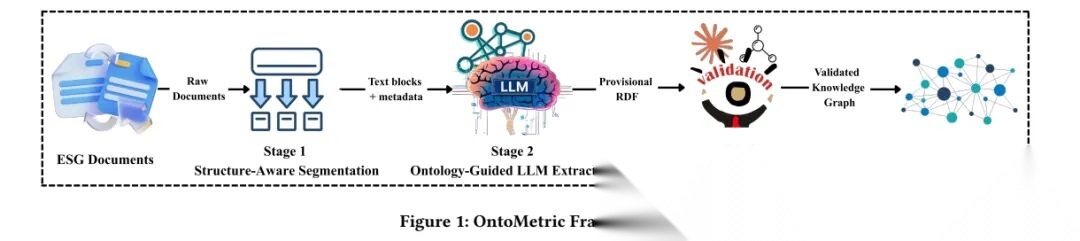
1、结构感知分割,基于目录(TOC)边界划分文档
ESG政策文档(比如SASB、TCFD)都是几百页的PDF,直接扔给AI提取容易乱。
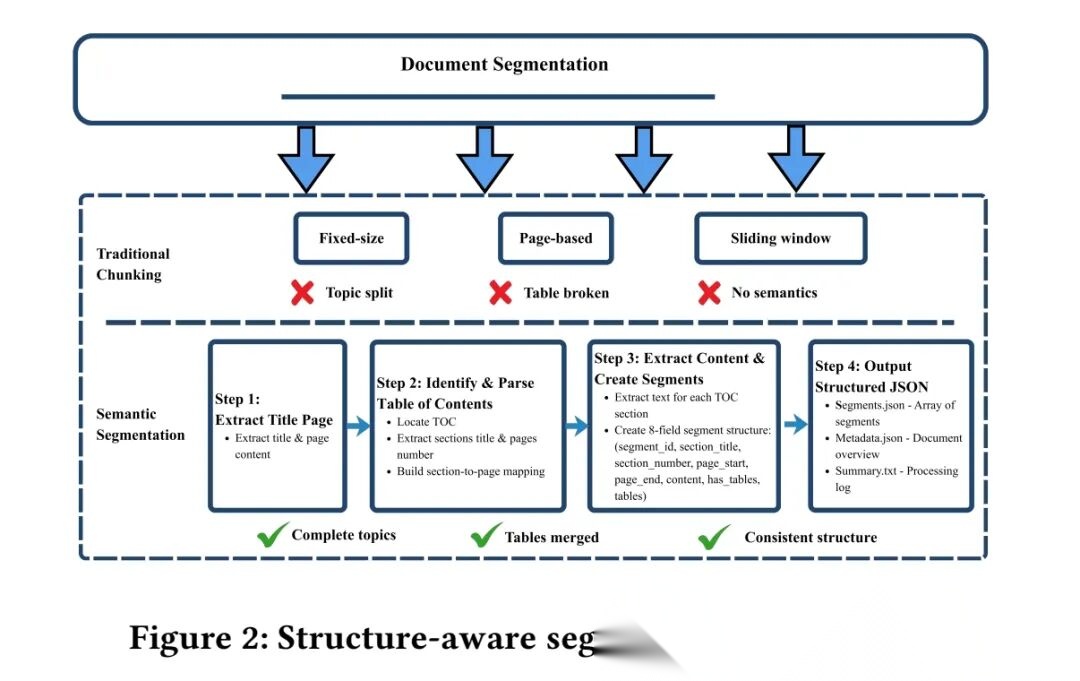
所以先按文档自带的“目录”拆分,比如“绿色气体排放”“数据安全”这些章节,each章节作为一个“小块”。每个小块都记着自己来自文档的哪几页、原来的标题,方便后续追溯来源。

具体实现上,步骤为:step1.识别目录页面与标题,确定自然分割边界;->step2.合并跨页表格,清理布局冗余;->step3.保留片段标题、页面范围、sectionID等元数据;->step4.确保片段为完整概念单元(如指标定义、公式)
2、本体引导LLM提取
抽取上,如下:
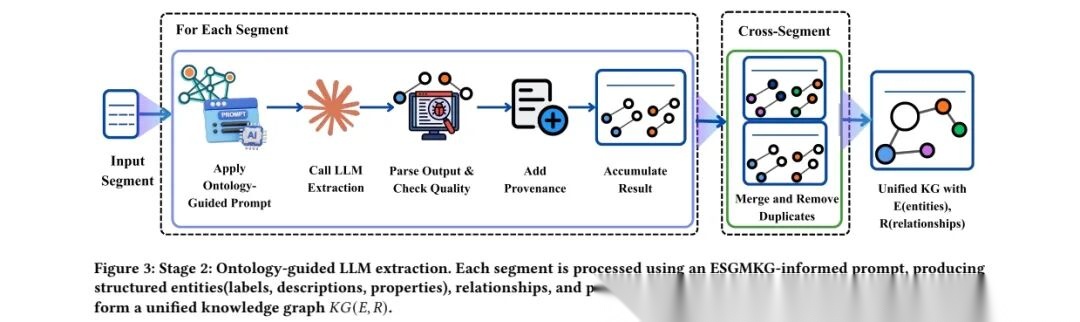
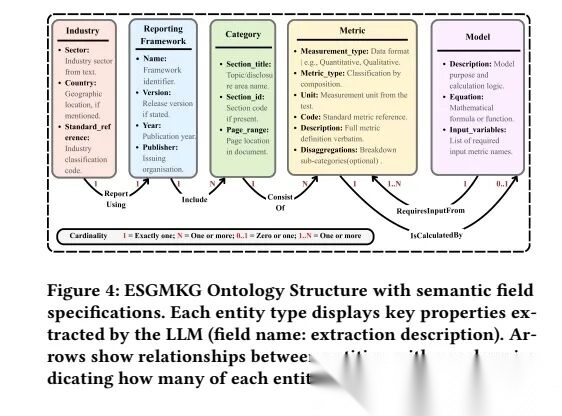
先告诉AI要提取5类信息(实体):行业(比如银行业)、披露框架(比如SASB)、分类(比如环境类指标)、具体指标(比如碳排放强度)、计算模型(比如碳排放怎么算);也就是一个是ESGMKGschema,包括5类实体(Industry、ReportingFramework、Category、Metric、Model)、5类关系谓词、7条结构规则;再定好这些信息之间的关系(比如“银行业”用“SASB框架”,“SASB框架”包含“环境类指标”);

给一个固定模板,让它把提取的信息填成结构化的JSON(比如指标名称、单位、描述都按固定字段填),一个是提示词设计,含系统上下文、本体连接图、实体定义等9个组件;
提取时记着每个信息来自哪个小块、哪一页,避免后续找不到源头。
最后把所有小块的提取结果合并,去掉重复的信息,解析JSON、添加溯源元数据、跨片段整合(ID解析+实体/关系去重)。
3、两阶段验证
为了解决实体不一致、关系幻觉、缺失溯源、验证失败率高的问题,缓解思路是语义验证+规则化schema验证来实现。
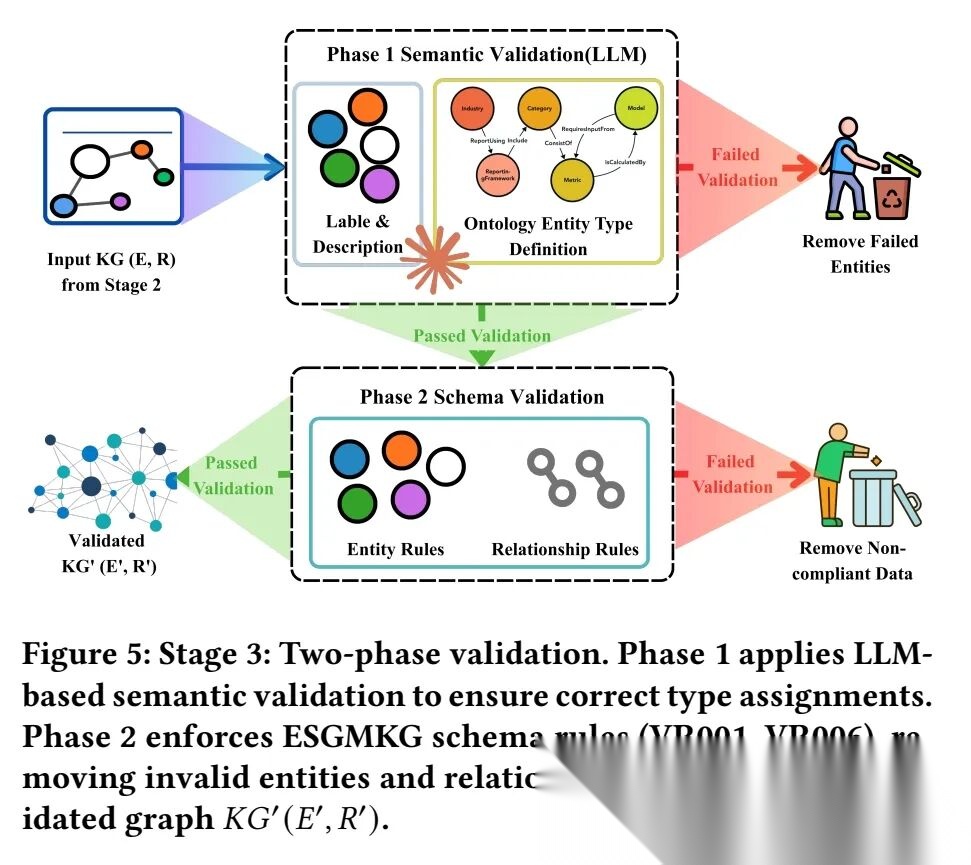
两阶段验证层:先通过LLM校验实体类型匹配度,再用6条规则检查结构合规性,剔除幻觉内容;同时全程保留片段/页面级溯源,解决溯源缺失问题。
拆开来看这个验证问题:
两阶段验证分为语义验证(Phase1)和schema验证(Phase2),两阶段结合使验证后的知识图谱同时满足语义正确性与结构有效性。
一个是语义验证,由LLM执行,核心作用是校验每个实体的标签和描述是否与其分配的ESGMKG类型匹配,直接剔除类型错误的实体及依赖关系,解决“实体类型幻觉”问题,减少后续无效校验,例如确认提取的“碳排放强度”确实是ESG指标,而不是财务指标(比如净利润),防止类型认错;
一个是schema验证,基于6条预定义规则执行,核心作用是保障结构合规性,具体包括:

1)实体验证,实体ID必须全局唯一;
2)实体验证,实体需包含类型特定的必填字段;
3)属性验证,指标的代码(code)和单位(unit)不可为空;
4)属性验证,模型(Model)需至少包含一个有效输入变量;
5)关系验证,仅允许ESGMKG定义的5类关系谓词
6)关系验证,每个计算型指标(CalculatedMetric)需精确关联一个模型(Model)
如下:
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

















 963
963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









