



一、问题背景:高分辨率视觉理解的“效率困境”
多模态大语言模型(MLLMs)如 LLaVA、Qwen-VL、InternVL 等,让 AI 能“看图说话”,但在高分辨率场景下,视觉输入的处理效率成为瓶颈。
要看清楚,就得处理更多像素;要运行快,就得降低分辨率。
这是“高精度”与“高效率”间的矛盾。
传统视觉编码主要有两种方式:
- Slice-based Encoding (SBE):把图像切块后分别编码,再拼接输出。
⚠️ 问题:破坏全局一致性(global semantic consistency)。 - Naive-resolution Encoding (GNE):整幅图像直接输入模型,保持语义完整。
⚠️ 问题:计算量爆炸,显存和延迟都极高。
因此,一个关键问题被提出:
如何在不牺牲全局语义的前提下,让高分辨率视觉编码“轻量又高效”?
二、方法创新:Progressive Visual Compression (PVC) 框架 🧠
LLaVA-UHD v3 提出了 Progressive Visual Compression (PVC) 框架,
首次在不降分辨率的前提下,实现了渐进式视觉压缩。
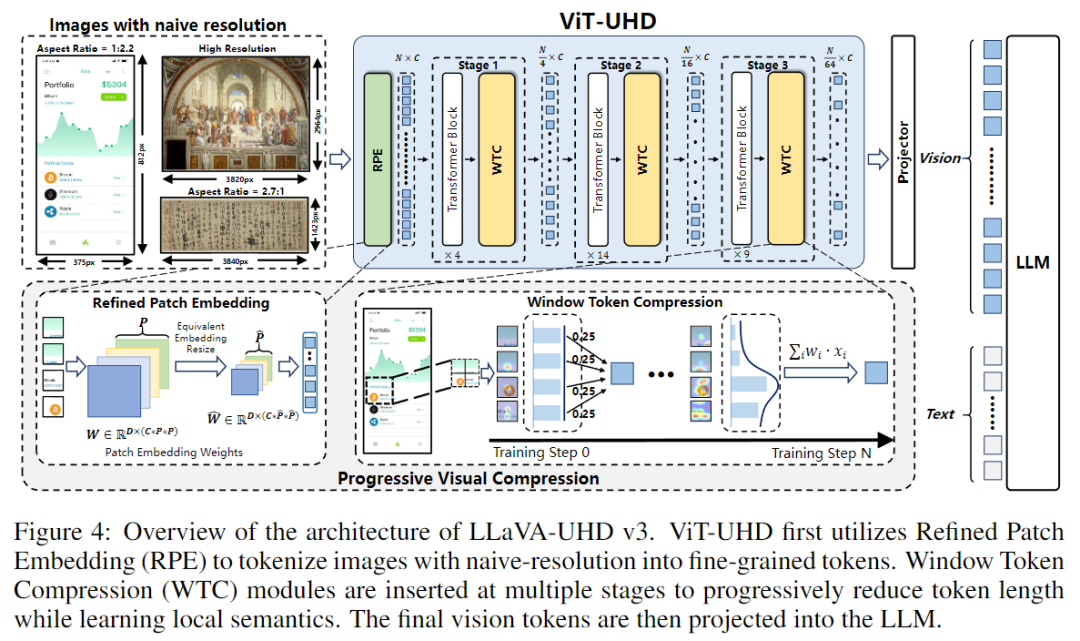
🧩 (1) Refined Patch Embedding (RPE)
RPE 改进了传统 Vision Transformer(ViT)的输入层,通过缩小 patch 尺寸(如 14×14 → 10×10)并重新线性映射,提升视觉细粒度(fine-grained detail),同时兼容预训练权重。
RPE 相当于“放大镜”,让模型看到更多细节而不增加训练成本。
⚙️ (2) Windowed Token Compression (WTC)
WTC 是 PVC 的核心模块,它在编码过程中逐步合并局部 token。采用 2×2 窗口的 content-adaptive pooling,让模型学会在保证语义的同时“压缩不重要的信息”。这种压缩是渐进的(progressive),在多层 Transformer 之间动态进行,
既减少了 token 数量,又保留了全局结构。
🧠 (3) 端到端优化 + 模型对齐
PVC 被应用于 ViT 视觉主干后,形成新的视觉编码器 ViT-UHD。它与语言模型(如 Qwen2-7B)通过轻量 MLP Projector 对齐,在整个多模态训练过程中实现了高效协同。三阶段训练策略:
- 视觉-语言对齐 (Alignment)
- 多模态联合预训练 (Joint Pretraining)
- 监督微调 (SFT)
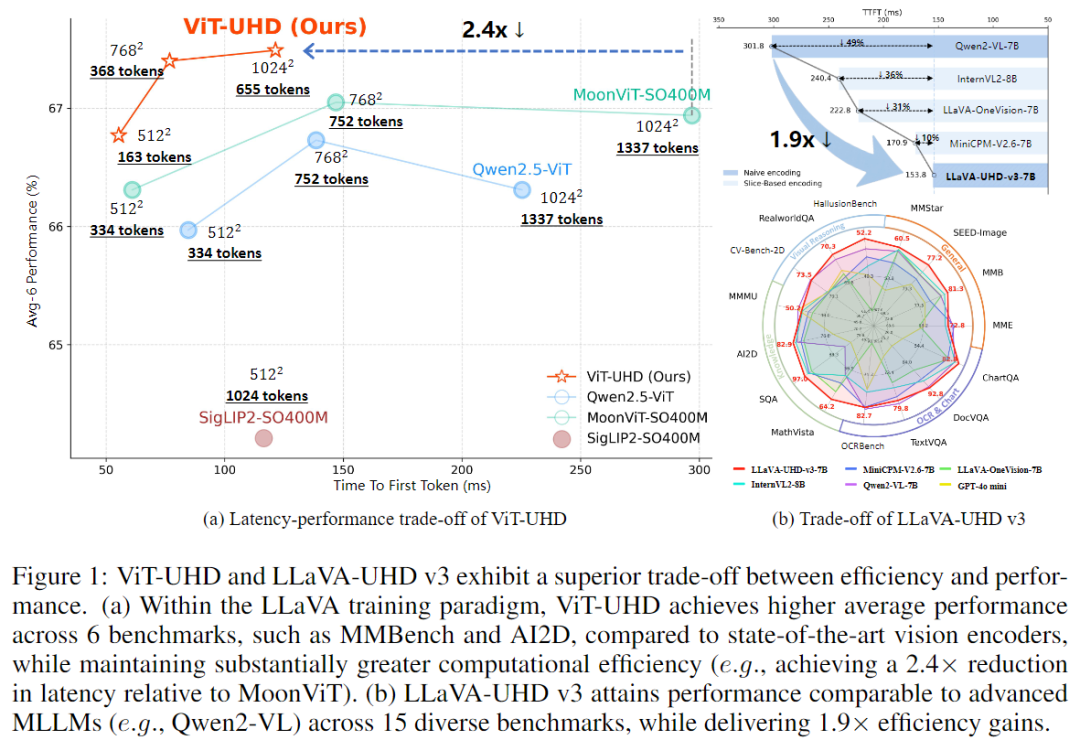
三、实验结果:既快又准的视觉大模型 🚀
LLaVA-UHD v3 在 15 个多模态基准上进行了全面测试,结果令人惊喜。
| 任务类型 | 基准 | 对比模型 | LLaVA-UHD v3 优势 |
|---|---|---|---|
| 通用理解 | MMBench / SEED | Qwen2-VL / MoonViT | 性能相当但延迟降低 2× |
| 空间推理 | HallusionBench / CV-Bench | MiniCPM-V2.6 / InternVL2 | 提升空间理解准确率 |
| 文档与图表 | DocVQA / ChartQA | Qwen2-VL | 在相同压缩比下保持精度 |
尽管 LLaVA-UHD v3 的训练数据量仅为 Qwen2-VL 的 1/35(20M vs 700M),
其综合性能依然能与主流开源模型持平甚至超越。
📉 效率指标
- TTFT(Time-To-First-Token) 降低 2.4×;
- 显存占用 减少 **70%~80%**;
- 吞吐率(Throughput) 提升 2×。
换句话说:
LLaVA-UHD v3 在“看得更清楚”的同时,也“说得更快”。
四、优势与局限 ⚖️
✅ 优势
- 🧩 高分辨率友好:保留全局语义结构;
- ⚙️ 渐进式压缩:兼顾精度与效率;
- 🧠 无需重新训练:可复用现有 ViT 权重;
- 💡 通用性强:可嵌入任意 MLLM 框架(如 LLaVA、Qwen、InternVL)。
⚠️ 局限
- 在极端长图或超高分辨率(>4K)下仍有延迟瓶颈;
- content-adaptive pooling 的聚合质量受训练数据影响;
- 暂未支持视频或时间序列建模。
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

















 1916
1916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









