






目录
使用包含填充像素的输入图像对抗性攻击 LLaVA-1.5 的实验
研究动机
- 现有LLMs通常采用固定的宽高比(如1:1)和低分辨率(如224×224)进行图像处理,这导致图像内容的严重形状失真和模糊,进而影响模型的细粒度能力
- 视觉编码策略的系统性问题:强大的LMMs如GPT-4V和LLaVA-1.5,在处理高分辨率图像时也存在系统性问题,例如在基本能力(如物体数量识别)上表现不佳。这些问题部分归因于其视觉编码策略,特别是在处理高分辨率图像时的不当策略。
- 对抗攻击的潜在风险:现有LMMs的视觉编码策略存在系统性问题,可能导致模型对对抗攻击的脆弱性增加。
主要贡献
- LLaVA-UHD模型的提出:本文提出了LLaVA-UHD,这是一种能够高效感知任意宽高比和高分辨率图像的大型多模态模型。该模型通过以下三个关键组件解决了现有LMMs的局限性:
- 图像模块化策略:将原生分辨率的图像分割成更小的可变尺寸切片,以实现高效和可扩展的编码。
- 压缩模块:进一步压缩视觉编码器生成的图像令牌,减少LLMs的计算量。
- 空间模式组织:将压缩后的切片令牌按空间模式组织,以告知LLMs切片在图像中的位置。
探究实验
GPT-4V 很容易错误计算图像中的对象数量,但其原因仍然很大程度上未知。从视觉编码策略的角度对 GPT-4V 缺陷进行了首次机制研究。我们的实验结果表明,GPT-4V 的一些系统缺陷很可能源于其视觉编码策略,该策略可能被用于对抗性攻击。
GPT-4V识别物体数量实验
图像中的位置如何影响 GPT-4V 的行为?
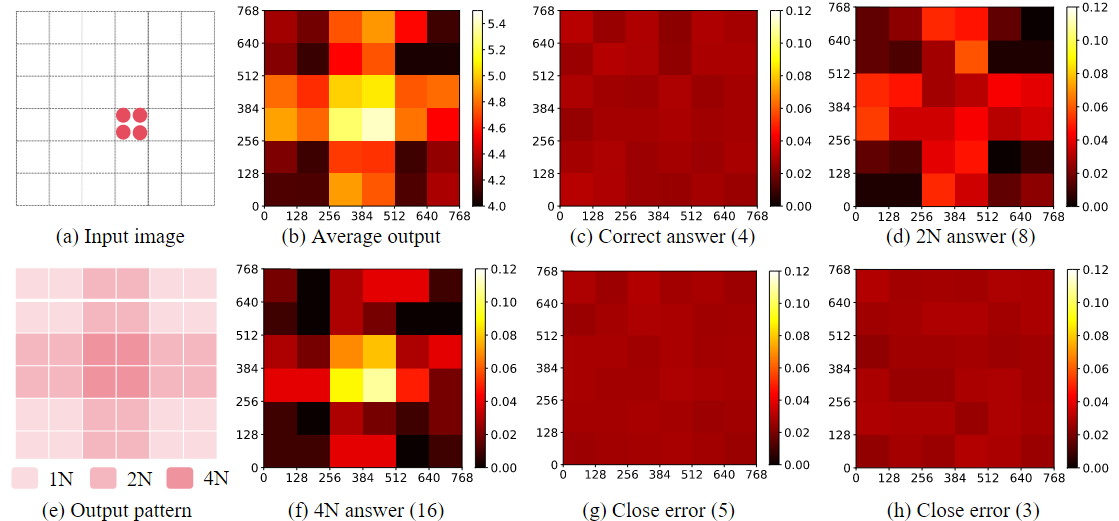
我们的实验从一个简单的实例开始:给定如图1(a) 所示的图像,我们询问 GPT-4V:"图像中有多少个圆圈?"我们通过以下方式合成一系列图像变体:改变图像中圆圈的位置,并保持文字提示不变。为了获得更好的可靠性,我们还使用其他颜色和形状({红色、绿色、白色} – {圆形、三角形、正方形})来合成图像。对于每个实例,我们查询 15 次以更好地近似真实的响应分布。
我们计算 GPT-4V 对图像中每个位置回答的平均数量,并在图 1(b)中报告热图。我们可以观察到结果与图像中的物体位置高度相关。具体来说,图案被分割为方格,可以识别出三个有趣的现象:(1) 中心方格显示最高的响应数,(2) 中间边缘显示较低的数字,(3) 角点最接近真实情况。
为了调查原因,我们进一步按数字分离模型响应,并报告图 1(c)、(d)、(f)、(g) 和 (h)中每个响应的位置分布。有趣的是,除了正确答案(4:66.1%)和接近答案(5:16.6%,3:10.2%)之外,事实证明,剩下的两个异常答案(8:5.2%,16:1.9%),解释图 1(b) 中的错误模式。结合 OpenAI 的公开信息,我们假设最可能的原因是,当图像分辨率不能被 512 整除时,GPT-4V 的切片存在重叠。如图 1(e) 所示,两个切片之间的重叠区域将使数量增加一倍,四个切片之间的重叠区域将使数量增加四倍。
图像分辨率如何影响 GPT-4V 的行为?
为了验证这一假设,我们通过不断变化的图像分辨率进一步探测 GPT-4V。具体来说,我们将图2(a)中的图像按比例调整为不同的分辨率,并以相同的方式查询对象数量。对于每个解决方案,我们重复查询 30 次以获得更好的可靠性。
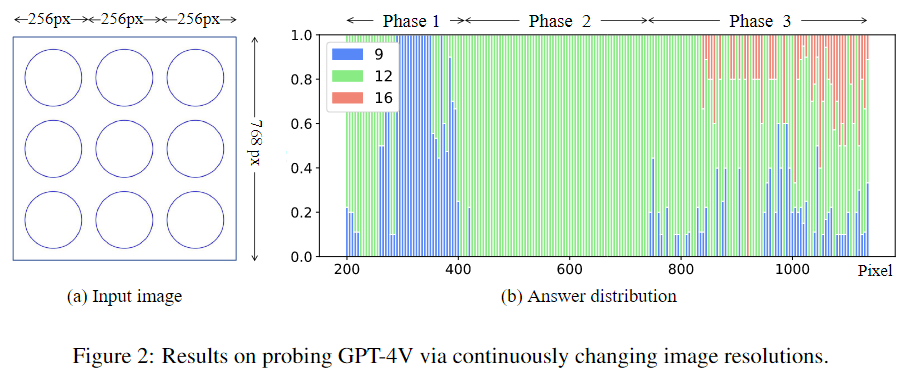
我们在图2(b)中报告了实验结果。我们观察到模型响应随图像分辨率显示出显着的相位变化:(1)在第 1 阶段,由于没有图像切片,因此大多数答案都是正确的; (2) 在第 2 阶段,答案 12 主导了响应,这可能是由于每个切片中的圆圈不完整所致。 (3) 第 3 阶段显示了 9、12 和 16 的混合答案。请注意,16 可以通过图 1(e) 中的错误模式很好地解释。我们建议读者参阅 A 部分,以获取每个阶段的更详细说明。此外,我们还注意到图2(b)中的许多异常现象还无法完美解释,我们将其留待将来的工作。
使用包含填充像素的输入图像对抗性攻击 LLaVA-1.5 的实验

为了处理具有不同长宽比的图像,LLaVA-1.5 将输入图像填充为正方形,然后将其输入视觉编码器。这种编码方法会导致非方形图像的计算浪费。我们通过使用 2D 插值将 ViT 位置嵌入拟合到输入图像的长宽比来训练 LLaVA-1.5 的未填充版本。与 LLaVA-1.5 中一样,最终的图像标记不超过 576 个(参见第 3.1 节)。从表 2 的实验结果中,我们观察到无填充的自适应宽高比编码持续提高了 LLaVA-1.5 的性能。
填充的另一个问题是,模型本质上无法知道类似填充的像素是来自图像预处理还是原始输入图像的实际部分。为了演示这个问题,我们合成了一系列输入图像,如图 3(右)所示,其中各种长宽比的蓝色/绿色/红色矩形被灰色包围(即 LLaVA-1.5 的填充颜色) RGB值)。给定输入图像,我们提示:"左/右/上/下最区域的颜色是什么?"
从图 3(左)的结果中,我们观察到 LLaVA-1.5 忽略了灰色输入区域(将其视为填充),并忠实地响应中心矩形的颜色。
方法
处理高分辨率且具有不同宽高比的图像时,一种朴素的方法是对ViT的位置嵌入进行插值以适应目标形状,然后整体直接编码。然而,这种方法由于计算成本呈二次增长以及因超出训练分布而导致的性能下降问题而不够理想。为了解决这一挑战,论文提出了模块化视觉编码策略。基本思路是将原生分辨率的图像分割成多个大小可变的小块切片,确保每个切片的形状与ViT预训练的标准设置相差不大。通过使用大小可变的切片,LLaVA-UHD能够在无需填充或形状扭曲调整的情况下,实现对原生分辨率图像的完全适应性。
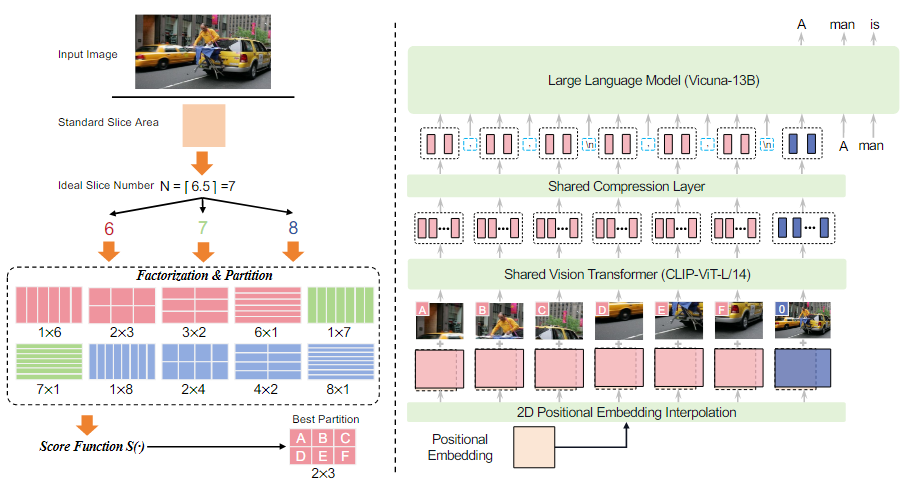

模块化视觉编码
- 高分辨率图像分区策略

视觉Token压缩
如果直接采用ViT的输出作为图像的token,图像部分 embedding 就会很长。论文使用类似于Q-Former的 resampler,用一个可学习的 Query与图像特征计算 cross attention,这样就能保证无论多长的图片,输出图片特征长度都可以保持一致。
图像切片的空间模式
由于图像分区在不同图像之间是动态的,因此有必要告知LLM图像切片的空间组织。我们设计了一个空间模式,使用两个特殊的标记来告知图像切片的相对位置。具体来说,我们使用 -, - 分隔行中的切片表示,并使用 -\n- 分隔不同的行。在我们的实验中,我们发现简单的模式可以有效地通知动态分区以产生良好的性能。


















 433
433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









