



为什么在 Model Context Protocol(MCP)体系下,引入 code execution(代码执行) 能显著减少 token 消耗、降低延迟,并让代理更稳更强。
MCP 是连接智能体与外部系统的开放标准。随着社区沉淀出成千上万的 MCP servers(工具与数据接入点),一个现实问题逐渐显现:工具越多,上下文越重,代理越慢也越贵。本文从工程视角解释根因,并给出一条简单有效的路线:把“直接工具调用”转化为“写代码调用 API”,让模型在执行环境中按需加载工具、在本地处理数据,再将必要的信息回传给模型。对于擅长写代码和策划多步流程的 Claude 系列模型,这条路线尤其合拍。
一、问题:工具越多,Token 越贵
识别两类最常见的 token 浪费来源,并理解其对时延与稳定性的影响。
现象 1:工具定义挤爆上下文。
常见做法是把所有 MCP 工具定义一次性塞进上下文,让模型通过“直接工具调用”语法使用它们。工具定义往往包含名称、描述、输入/输出 schema 等,当连接上百上千个工具时,仅“读完工具清单”就可能消耗数十万 tokens。这会带来两类问题:响应慢、费用高。
现象 2:中间结果反复经过模型。
在直接工具调用模式中,每一步工具返回结果(哪怕是超长文档或大型表格)都会回流到模型,再由模型发起下一步调用。结果就是:
- 中间数据二次甚至多次进出上下文,token 开销飙升;
- 超长内容可能超过上下文上限,流程直接失败;
- 大结构在多次复制/粘贴中更容易引入格式或字段错误。
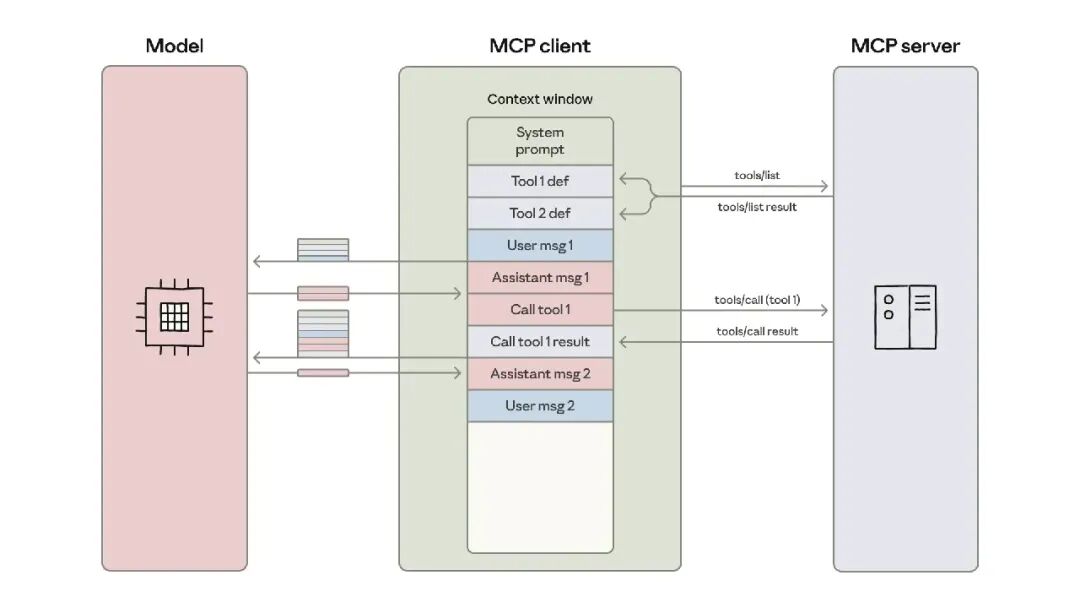
相当于把所有工具说明书都摊在桌上(上下文),且每做一步都把全部原始材料端上来给大家过目,自然慢、累、易出错。
二、思路:把 MCP 工具“变成代码 API”
学会在代码执行环境(执行沙箱)里把 MCP 暴露为可编程的 API,由模型写代码调用,而非把所有定义塞进上下文。
关键转变是:让模型写代码,与 MCP server 对话。做法可以很朴素——把每个 server 的工具映射成文件系统中的“代码文件”,模型通过读文件来“认识工具”,通过写代码来“调用工具”。
一个简单的目录映射示意:
./servers/ google-drive/ getDocument.ts # 工具定义与薄封装 searchFiles.ts salesforce/ updateRecord.ts findLead.ts
调用流程的“最小闭环”伪代码(TypeScript):
// 读取所需工具的签名(仅按需读取)// import { getDocument } from "./servers/google-drive/getDocument";// import { updateRecord } from "./servers/salesforce/updateRecord";async function attachTranscriptToLead(docId: string, leadId: string) { const text = await googleDrive.getDocument({ id: docId }); // 在沙箱中执行 const summary = summarize(text, { maxTokens: 1024 }); // 本地先处理 await salesforce.updateRecord({ id: leadId, note: summary }); return "done";}
要点:
- 按需加载:模型只会打开/读取“当下需要的工具文件”,而不是整套工具百科全书。
- 本地处理:先在执行环境里做过滤、聚合、抽取,再把精简结果回传模型。
- Token 降维:实践中常见从十几万 tokens 降到几千,量级节省。
对于擅长写函数、组织多步流程的 Claude,这种“写代码驱动工具”的方式能更稳定地完成复杂任务,而不是在多轮工具调用里来回搬运大块上下文。
三、渐进披露:让模型只看“当下需要”的工具定义
用文件系统探索或搜索接口实现progressive disclosure(渐进披露),避免一次性加载全部工具描述。
文件系统探索:让模型先 ls ./servers,再进入 google-drive/ 或 salesforce/,只在需要时打开 getDocument.ts 或 updateRecord.ts。这就像翻工具箱:先看抽屉标签,再取对应扳手,而不是把所有工具摆满地。
搜索式发现(可选):提供一个 search_tools 工具,支持关键词检索,并带有 detailLevel 参数:
name:只返回工具名(最低负载)name+desc:返回名与简短描述full:返回完整定义(含 schema)
模型可先粗筛,再精看;按需精读的代价更低。
四、上下文高效的数据处理与控制流
在沙箱中先算后说,用熟悉的编程结构替代“多轮工具-模型回路”,显著降低 token 与延迟。
1)先过滤后回传
当需要拉取一份 10,000 行的表格时,不要把全表送进上下文。让模型写代码在沙箱中做预处理:
const sheet = await sheets.getRange({ id, range: "A:E" }); // 10000 行const top5 = sheet.rows.slice(0, 5); // 仅示例行log.table(top5); // 回传可视摘要
模型只看到必要的 5 行概览,而不是整张表。同理,聚合、join 多源数据、字段抽取都先在本地完成。
2)用代码写明控制流
轮询部署状态、重试、异常处理,用普通语言结构就能清楚表达:
for (let i=0; i<20; i++) { const status = await deploy.check({ id }); if (status === "success") { await slack.post({ channel, text: "✅ Deploy succeeded" }); break; } await sleep(15000);}
对比“模型-工具”来回交替与 sleep,代码一次跑完更高效,也能显著缩短 “time to first token”(不必等模型逐步判定 if/else)。
五、隐私与安全:把敏感数据留在沙箱里
学习在执行环境中通过数据最小化与自动脱敏来降低泄露风险,同时维持端到端自动化。
在“代码执行 + MCP”模式下,中间结果默认留在沙箱。只有显式 log() 或返回的内容才会进入模型上下文。对于含 PII 的流程(如从 Google Sheets 导入客户信息到 Salesforce),可以在 MCP 客户端侧自动做tokenization(令牌化):
- 写代码时仍使用真实字段;
- MCP 客户端拦截并将姓名、邮箱、电话替换为令牌(如
{{pii.email:42}})传给模型; - 当把数据传给下游 MCP 工具(如 Salesforce)时,再由客户端反向解码为真值;
这样真实隐私数据从未进入模型上下文,既避免无意日志泄漏,也便于落地确定性的数据流规则(何处可读、何处不可读)。
让模型拿着“钥匙编号”办事,真正的钥匙只在门口(MCP 客户端)管理,从不交到模型手里。
六、状态与技能:让代理越用越能打(
掌握 持久化状态与可复用技能(Skills),并评估落地成本与收益。
1)持久化状态
执行环境有文件系统时,代理可将中间结果、游标进度写入磁盘:
writeFile("./state/progress.json", { lastProcessedId: 12345 });
断点续跑、失败恢复都更简单可靠。
2)沉淀“可复用函数”即技能
当某个任务的实现验证有效后,把这段代码存为复用函数,并配一份 SKILL.md(说明输入输出、前置条件、边界情况)。在 Claude 的 Skills(技能) 体系中,这些文件夹化的脚本与文档能被模型识别与复用,逐步形成更高层的抽象工具箱。下一次遇到相似任务,模型无需从零思考,直接调用“技能”。
3)落地权衡
- 收益:显著降低 token 与延迟;减少多轮粘贴式错误;提升复杂流程的可组装性;更好地做隐私隔离与数据最小化。
- 成本:需要一个安全的沙箱执行环境(严格的资源限制、文件/网络隔离、调用审计与监控)。这部分是系统工程投入,但其复杂度是可控且成熟可借鉴的。
- 建议路径:
- 从只读型工具切换为代码模式(如搜索、读取文档),先把“按需加载 + 本地过滤”做起来;
- 再把长链路多步流程迁移到代码执行,统一在沙箱中组织控制流;
- 最后引入自动脱敏与技能沉淀,完成隐私与可复用体系闭环。
总结:
MCP 让代理能连通海量外部系统,但“上下文承载工具与中间结果”的老路会在规模化时失速。把 MCP 当作代码 API,让模型写代码调用工具、在本地处理数据、只回传必要信息,既沿用了软件工程里行之有效的模式,也最大限度发挥了 Claude 在代码合成与多步推理上的强项。实践表明,这种模式常能将上下文开销从数十万 tokens 降到几千,同时带来更稳定的复杂流程执行力。如果你正在推进大规模的工具编排或企业级自动化,这是一条性价比极高、工程上务实可落地的路径。
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

















 830
830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









