






在全球人工智能领域蓬勃发展的当下,开源模型正以前所未有的活力与创新,不断刷新着行业的认知与标准。其中,DeepSeek-V3和Qwen2.5系列的惊艳亮相,无疑是开源领域中极具里程碑意义的事件。这两大模型凭借其卓越的技术创新与高效优化,不仅成功将训练成本和资源消耗降至极低水平,更在性能上实现了与闭源顶级模型的并驾齐驱,为开源模型的未来发展开辟了崭新的道路。
DeepSeek-V3:开源领域的璀璨新星
DeepSeek-V3,开源的大型语言模型(LLM),在众多基准测试中力压GPT 4o和Claude 3.5 Sonnet等强大对手,彰显出其非凡的实力。其背后是强大的混合专家(MoE)架构支撑,拥有671B的庞大总参数量,而每个token则激活了37B参数,如此精细的架构设计为模型的高效运行奠定了坚实基础。
在DeepSeek-V3的架构中,每个token配备1个共享专家和256个路由专家,其中8个活跃路由专家协同工作,搭配多头潜在注意力机制,借助低等级联合压缩巧妙关注键和值,同时引入多token预测功能,不仅助力投机解码,更实现了对训练数据的深度挖掘与高效利用。
在训练环节,DeepSeek-V3展现出惊人的成本效益。借助14.8万亿个token的海量训练数据,以及2788K H800 GPU小时的强大算力支持,其训练成本仅为560万美元。这一成本优势得益于精细的MoE架构设计,在训练中巧妙运用FP8混合精度,以及灵活调整和扩展上下文长度的策略。
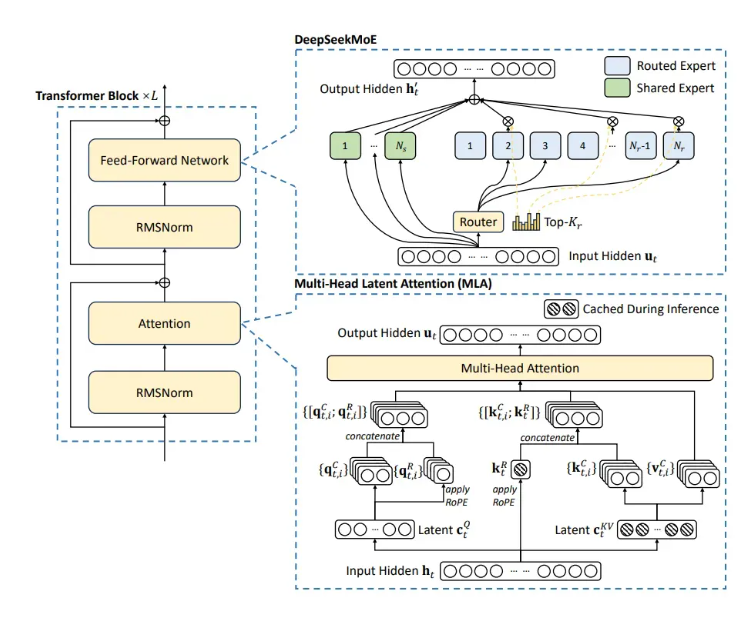
通过算法、框架与硬件的深度协同设计,DeepSeek团队成功攻克了大型MoE模型训练中的通信瓶颈难题,实现了计算资源的高效利用。两阶段的上下文长度扩展策略,先将上下文从4k令牌拓展至32k令牌,再进一步延伸至128k令牌,与Llama、Claude等同类模型相比,综合优化成果显著,训练效率大幅提升,成本更是降低了10倍之多。
训练完成后,DeepSeek-V3通过监督微调(SFT)和强化学习(RL)与人类偏好精准对接,进一步锤炼了其推理模型DeepSeek-R1的推理与数学能力。多令牌预测(MTP)功能的加持,不仅增强了模型性能,更实现了推理加速的投机解码,使其在实际应用中如虎添翼。
在基准测试中,DeepSeek-V3的表现令人瞩目,仅以37B个活动参数便在MMLU上取得88.5的高分,在GPQA上斩获59.1,在MMLU-Pro上达到75.9,在MATH上更是高达90.2,在CodeForces上也有51.6的出色成绩。凭借如此卓越的性能,DeepSeek-V3毫无争议地成为当前最强的开源模型,与GPT-4o、Claude-3.5-Sonnet等顶尖闭源模型平分秋色,为开源领域赢得了极高的荣誉。
Qwen2.5系列:多元拓展的开源力量
自9月首次发布以来,阿里巴巴旗下的Qwen 2.5系列LLM便不断推陈出新,凭借一系列实用的更新与升级,迅速跻身领先LLM家族之列。从Qwen-2.5编码器32B模型的推出,到100万个令牌上下文支持的拓展,再到基于Qwen 32B的推理人工智能模型Qwen QwQ的发布,以及本周基于Qwen2-VL-72B的视觉推理模型QvQ的惊艳亮相,Qwen系列以多元化的版本矩阵,满足了编码、推理和本地使用等多场景需求,成为开源领域中备受瞩目的明星。
阿里巴巴Qwen团队精心编撰的Qwen2.5技术报告,为外界揭开了这一开放式权重系列LLM的神秘面纱。Qwen2.5系列涵盖了多个开放式权重基础和指令调整模型,参数规模从0.5B跨越至72B,更有Qwen2.5-Turbo和Qwen2.5-Plus两款专有的混合专家(MoE)型号。其中,开放式Qwen2.5-72B-Instruct的性能与Llama-3-405B-Instruct旗鼓相当,彰显出其卓越的实力。
在架构设计上,Qwen2.5 LLMs坚守基于变压器的解码器架构,巧妙融合了分组查询注意力(GQA)、SwiGLU激活、旋转位置嵌入(RoPE)、QKV偏置和RMSNorm等前沿技术。令牌化环节采用字节级字节对编码(BBPE),并配备扩展的控制令牌集,为模型的高效运行与精准表达提供了有力保障。
为了进一步提升模型性能,Qwen团队将训练前数据集扩充至18万亿个代币,精心筛选并纳入更多样化、高质量的数据源。预培训过程中,复杂的数据过滤、聚焦知识、代码和数学的战略数据混合以及长上下文培训等策略的运用,为模型筑牢了坚实的知识根基。
在训练后的优化环节,Qwen团队采用了超过100万个样本的复杂监督微调(SFT),并结合多阶段强化学习(DPO,随后是GRPO)的先进策略。两阶段强化学习巧妙地将复杂推理的离线学习与细微差别输出质量的在线学习有机结合,全方位提升了模型的性能与适应性。
借助YARN和Dual Chunk Attention(DCA)技术,Qwen2.5系列成功延长了上下文长度,其中Qwen2.5-Turbo更是达到了惊人的100万个代币,为长文本生成与结构化数据分析等任务提供了强大的支持。
在评估测试中,Qwen2.5系列在语言理解、数学、编码和人类偏好调整等多个关键领域均展现出顶级表现,其长上下文能力更是令人瞩目。例如,Qwen2.5-Turbo在1M令牌密码检索任务中实现了100%的准确率,这一成绩充分印证了其卓越的性能与可靠性。基于此,Qwen2.5系列进一步衍生出了Qwen2.5-Math、Qwen2.5-Coder、QwQ和QvQ等多模态专业模型,不断拓展着开源模型的应用边界与潜力。
开源力量的崛起与展望
在当下的人工智能领域,大多数专有人工智能模型供应商都对技术细节守口如瓶,而Qwen团队和DeepSeek团队却以开放的姿态,通过各自详尽的技术报告,毫无保留地向外界展示了他们的模型架构、训练策略与性能表现等关键信息。这种开放精神不仅为开源技术的持续进步注入了强大动力,更凸显了开放性在推动整个行业前行中的关键引领作用。
随着这些领先团队的不懈努力与持续创新,开源模型正以惊人的速度缩小与闭源顶级模型之间的差距。从DeepSeek-V3的高效架构与卓越性能,到Qwen2.5系列的多元拓展与全面优化,开源领域正迎来前所未有的发展机遇。未来,随着更多开源模型的涌现与成长,全球人工智能的发展必将迎来更加广阔、多元与繁荣的新局面,为人类社会的各个领域带来更加深远的变革与影响。
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】

















 108
108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









