



作者 | 周舒畅 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/1938635096618939242
点击下方卡片,关注“自动驾驶之心”公众号

>>自动驾驶前沿信息获取→自动驾驶之心知识星球
本文只做学术分享,如有侵权,联系删文
剧名: 《从感知到决策:VLA模型的黎明》
场景: 一个布置简洁的虚拟会议室。屏幕中央是本次论坛的标题。
人物:
主持人:Dr. Alex Kendall - 英国自动驾驶公司Wayve的创始人兼CEO,端到端学习路线的积极倡导者。
嘉宾:Prof. Andreas Geiger - 德国图宾根大学教授,马克斯·普朗克智能系统研究所研究员,KITTI、nuScenes等权威数据集的重要贡献者。
嘉宾:Dr. Chelsea Finn - 斯坦福大学助理教授,机器人学、强化学习和元学习领域的杰出青年学者。
(论坛开始)
Dr. Alex Kendall: (面带微笑) 各位早上好,欢迎来到我们的圆桌论坛。近年来,大语言模型的崛起为自动驾驶开辟了一个激人心的新前沿。今天,我们齐聚一堂,旨在深入剖析两篇正在推动技术边界的杰出论文:“OpenDriveVLA”和“AutoVLA”。它们都致力于构建视觉-语言-动作(VLA)模型,但其设计哲学和方法论却各有千秋,非常值得探讨。Geiger教授,我们先从您对OpenDriveVLA的看法开始吧。这篇论文的第一作者来自慕尼黑的大学,离您很近。
Prof. Andreas Geiger: (扶了扶眼镜,表情严谨) 谢谢你,Alex。的确如此。在我看来,OpenDriveVLA是一项非常稳健且务实的工程杰作。它的核心优势在于其解决根本性“模态鸿沟”的方式。传统的VLM在2D图像和文本上训练,它们天生缺乏驾驶任务所必需的三维空间和时间理解能力。OpenDriveVLA直面了这一挑战。
(屏幕上显示OpenDriveVLA的图1)
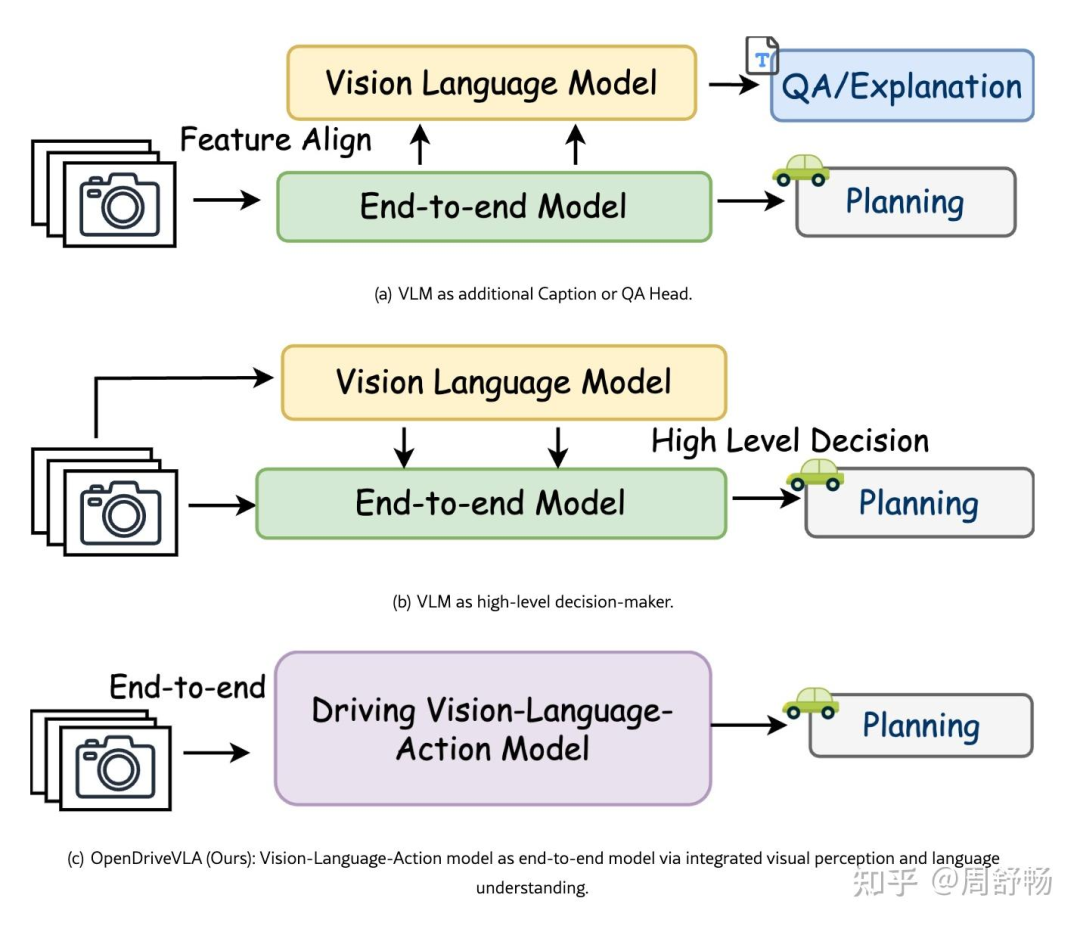
Prof. Andreas Geiger: 请看图1中的架构。他们没有简单地将原始的BEV特征直接输入语言模型,而是首先将3D世界结构化为有意义的、Token化的概念:用于静态元素的Map Token,用于全局上下文的Scene Token,以及用于动态角色的Agent Token。这是通过专门的QFormer实现的。这种分层化的Tokenization为LLM提供了一种高质量、经过预消化的三维环境理解。这相当于在教VLM像一个经验丰富的老司机一样去‘看’世界,而不仅仅是一个被动的观察者。
Dr. Chelsea Finn: 我发现这种方法非常巧妙。这是降低“空间幻 giác”风险的一个聪明策略,而空间幻 giác 是将大语言模型应用于物理世界时的一个主要安全隐患。通过将模型锚定在这些结构化的3D Token上,他们本质上是为模型注入了关于物理世界的强大先验知识。他们在图3中展示的多阶段训练过程,进一步强化了这一点。
(屏幕上显示OpenDriveVLA的图3)

Dr. Chelsea Finn: 他们首先进行征对齐,然后进行指令微调,接着是交互建模,最后才是轨迹规划微调。这是一个设计得非常精妙的训练流程。它确保了模型在尝试决定‘做什么’之前,已经学会了‘是什么’和‘在哪里’。
Prof. Andreas Geiger: 完全正确。而且结果本身就很有说服力。我们来看他们的表2,OpenDriveVLA在nuScenes开环规划基准测试上取得了SOTA(state-of-the-art)的性能。
(屏幕上显示OpenDriveVLA的表2)
Method | L2 (m)↓ | Collision (%)↓ | LLM | Input |
|---|---|---|---|---|
... | ... | ... | ... | ... |
OpenDriveVLA-7B (Ours) | 0.15 0.31 0.55 0.33 | 0.01 0.08 0.21 0.10 | Qwen2.5-7B | Visual |
Prof. Andreas Geiger: 对于一个自回归模型来说,0.33米的平均L2误差是极具竞争力的。这证明了他们以感知为基础的锚定策略是行之有效的。
Dr. Alex Kendall: 确实是坚实的基础。现在,让我们把焦点转向AutoVLA。Finn博士,您的研究大量涉及学习和强化。AutoVLA采用的动作Token化和强化学习微调方法,想必一定吸引了您的注意。
Dr. Chelsea Finn: (眼中闪烁着兴奋) 当然,Alex!如果说OpenDriveVLA致力于为VLM构建一个更好的感知基础,那么AutoVLA就是致力于将VLM转变为一个真正的决策智能体。对我而言,这篇论文中最优雅的设计就是“物理动作Token化”。
(屏幕上显示AutoVLA的图1)
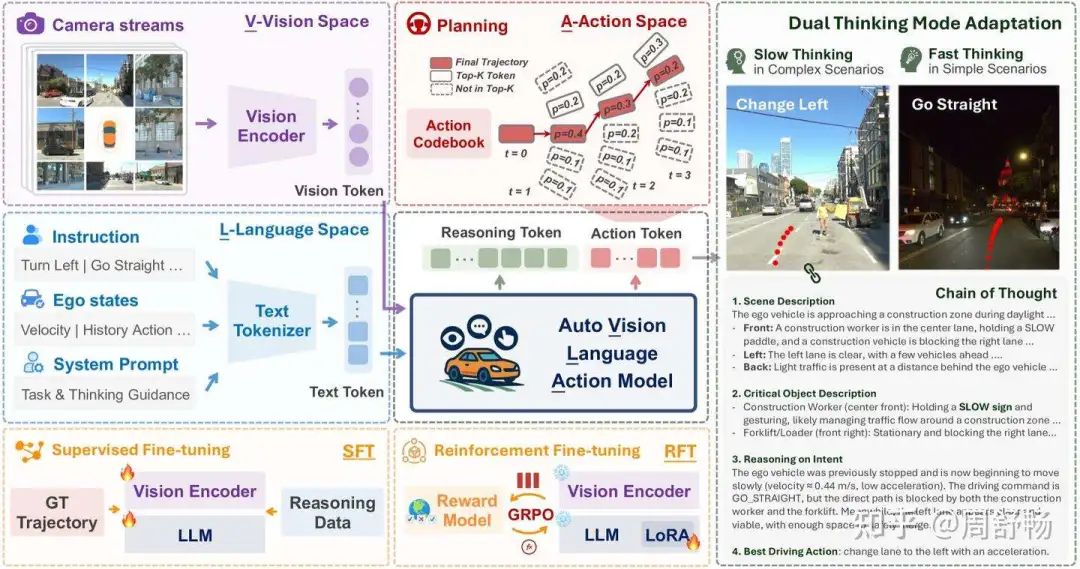
Dr. Chelsea Finn: 他们没有让模型以文本形式输出连续的、且常常在物理上不合理的航点坐标,而是创建了一个离散的动作代码本。这太妙了。他们将连续控制问题转化为了一个下一Token预测问题,而这正是LLM的原生语言。模型不再仅仅是描述要做什么,而是在从它的词汇表中选择一串经过物理验证的动作序列。
Prof. Andreas Geiger: 这是一个集成度高得多的方法。它在一个统一的框架内,弥合了高层推理和底层运动控制之间的最后一道鸿沟。
Dr. Chelsea Finn: 完全正确。更妙的是,他们引入了“双模式思维”。......但真正的神来之笔是强化学习微调(RFT)阶段。
(屏幕上显示AutoVLA的图3)
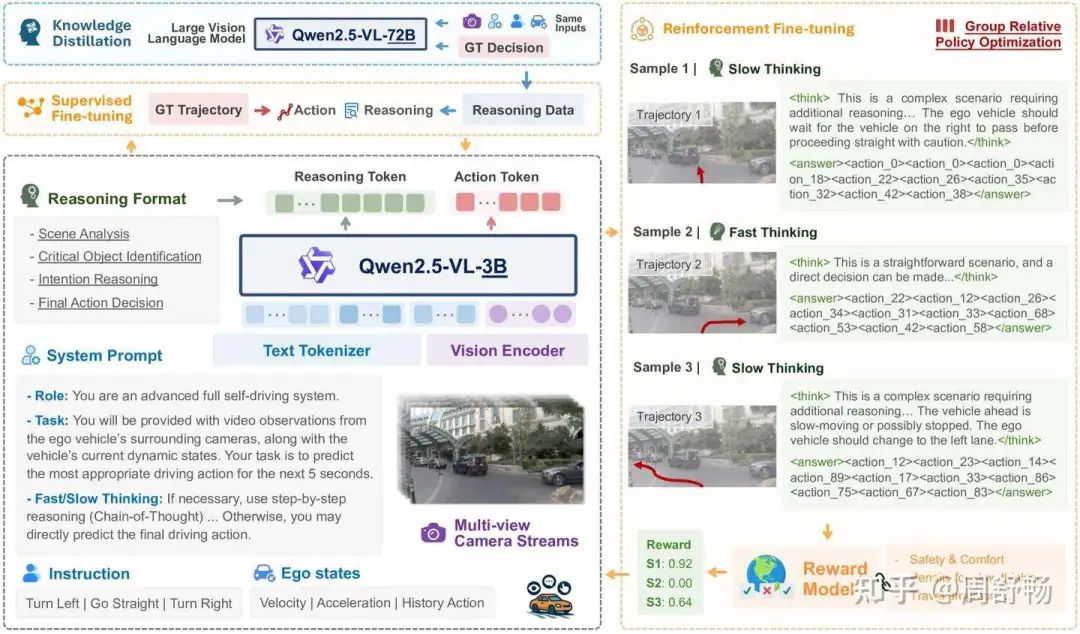
Dr. Chelsea Finn: 他们使用组相对策略优化(GRPO)算法,直接针对驾驶相关的奖励函数来微调模型的策略,......这是超越纯粹模仿学习的关键一步。模型不再仅仅是试图模仿人类驾驶,而是在主动优化其行为,以成为一个更好的驾驶员。他们甚至会对不必要的长推理链进行惩罚以提高效率。看看他们在图5中展示的RFT之后的性能跃升——无论是在PDMS得分还是在运行时间上,提升都非常显著。
Dr. Alex Kendall: 所以,总结一下两者的区别:OpenDriveVLA专注于为VLM提供高保真、结构化的三维视觉输入,使其成为一个更的世界诠释者。而AutoVLA则专注于重塑VLM的输出空间并优化其策略,使其成为一个更好的世界行动者。
Prof. Andreas Geiger: 非常精辟的总结。这正是优化‘输入管道’和优化‘决策引擎’本身的区别。OpenDriveVLA的优势在于其结构化的感知,这使其在前端可能更稳健、更具可解释性。而AutoVLA的RFT方法则赋予了它更高的性能天花板和更强的适应性,这一点从它在nuPlan、Waymo和CARLA等多样化且富有挑战性的基准测试上的优异结果中可见一斑。
Dr. Chelsea Finn: 我同意。它们就像一枚硬币的两面。OpenDriveVLA回答的是这样一个问题:“我们如何确保VLM能正确理解3D世界?”而AutoVLA回答的是:“我们如何让VLM生成有效、安全且高效的动作?”他们各自提到的局限性也反映了这一点。OpenDriveVLA担心其自回归特性对实时性能的影响。AutoVLA则关注其对GPU的依赖,这是大型模型和强学习训练的普遍问题。
Dr. Alex Kendall: 看来,未来理想的模型将是两者的集大成者。想象一下,一个系统拥有OpenDriveVLA的分层3D Tokenization来提供丰富且有根有据的输入,同时又由一个采用AutoVLA的动作Token化和强化学习微调训练出的智能体来决策。这可能成为端到端自动驾驶领域一个真正强大的范式。今天是一场非常精彩的讨论。感谢两位贡献的真知灼见。
(论坛结束)
<回答>
这两篇论文,OpenDriveVLA 和 AutoVLA,都致力于将大型视觉语言模型(VLM)应用于端到端自动驾驶,但它们的技术路径、核心哲学和创新点有显著的区别。下面将对两篇论文进行深入、长篇的专业讨论。
1. OpenDriveVLA: 聚焦于“感知-语言”对齐的结构化方法
OpenDriveVLA的核心目标是解决标准VLM在处理动态、三维驾驶环境时存在的“模态鸿沟”问题。它认为,若要让VLM做出可靠的驾驶决策,首先必须让它以一种结构化的方式“理解”3D世界。
方法论详解
其方法论可以分解为以下几个关键步骤,其整体架构如图1所示:
3D视觉环境感知: 模型从多视角摄像头图像出发,利用主干网络(如ResNet)和BEV(鸟瞰图)编码器,将2D图像特征提升到统一的3D BEV空间,形成场景的初步表征 f_bev。
分层化的视觉Token提取: 这是OpenDriveVLA最核心的创新。它不直接使用庞杂的BEV特征,而是设了三个并行的查询-转换器(Query Transformer)模块,将BEV特征提炼为三种结构化的视觉Token:
Agent Token (智能体Token): 通过
TrackQFormer模块,检测和跟踪场景中的动态物体(车辆、行人等),每个Token代表一个具体的智能体。Map Token (地图Token): 通过
MapQFormer模块,提取静态的道路结构信息,如车道线、可行驶区域边界等。Scene Token (场景Token): 通过
Scene Sampler模块,从多视角2D特征中直接编码全局的环境上下文信息。 这些TokenV_env = {v_scene, v_agent, v_map}共同构成了一个对驾驶环境的精炼、多方面的结构化描述。
视觉-语言分层对齐: 为了将这些结构化的视觉Token送入LLM,模型为每种Token设计了专属的投影器(Projector),即一个小型MLP。在训练的第一阶段,这些投影器负责将视觉Token映射到LLM的词嵌入空间。对齐过程通过预测与视Token对应的文本描述(Caption)来监督。例如,一个agent Token需要能被LLM解码为其对应车辆的2D外观和3D空间位置的描述。 对齐公式如下:
其中
是投影器,v 是视觉Token,X 是对应的文本描述。
多阶段训练范式: 模型的训练过程循序渐进,如其图3和表1所示,确保能力逐步构建:
阶段1 (特征对齐): 冻结视觉编码器和LLM,只训练投影器,完成视觉与语言的初步对齐。
阶段2 (指令微调): 训练投影器和LLM,使用大量的驾驶场景问答(QA)数据,向模型注入驾驶知识和推理能力。
阶段2.5 (交互建模): 引入一个代理任务——预测场景中其他智能体的未来轨迹,以增强模型对多智能动态交互的理解。
阶段3 (轨迹规划微调): 联合优化整个模型(视觉编码器可选冻结),使其在给定视觉输入、Ego状态和驾驶指令(如“请右转”)的情况下,自回归地生成Ego车辆的未来轨迹点。
主要贡献与优势
结构化视觉输入: 通过将复杂的驾驶场景分解为Agent、Map、Scene三种核心元素,极大地降低了LLM的理解负担,有效抑制了在复杂空间关系上的“幻觉”。
强大的3D空间接地能力: 模型的设计使其决策牢固地建立在对3D空间布局的精确感知之上。
卓越的开环规划与场景理解性能: 如表2所示,在nuScenes基准测试上,无论是在L2误差还是碰撞率方面,都达到了业界领先水平。同时,在VQA任务上也表现出色。
局限性
缺乏显式CoT推理: 模型通过指令微调隐式学习推理,但在推理时并未生成显式的思维链(Chain-of-Thought),这可能在面对极端复杂的长尾场景时削弱其可解释性和推理的鲁棒性。
自回归生成的效率问题: 作为一种自回归模型,逐点生成轨迹的方式在需要高速实时决策的驾驶场景中可能面临延迟挑战。
2. AutoVLA: 聚焦于“语言-决策”一体化的智能体方法
与OpenDriveVLA不同,AutoVLA的核心哲学是将驾驶任务完全融入VLM的原生工作方式——即序列生成。它致力于将VLM从一个“场景解说员”转变为一个真正的“驾驶决策者”。
方法论详解
AutoVLA的创新主要体现在以下几个方面,其架构如图1和图3所示:
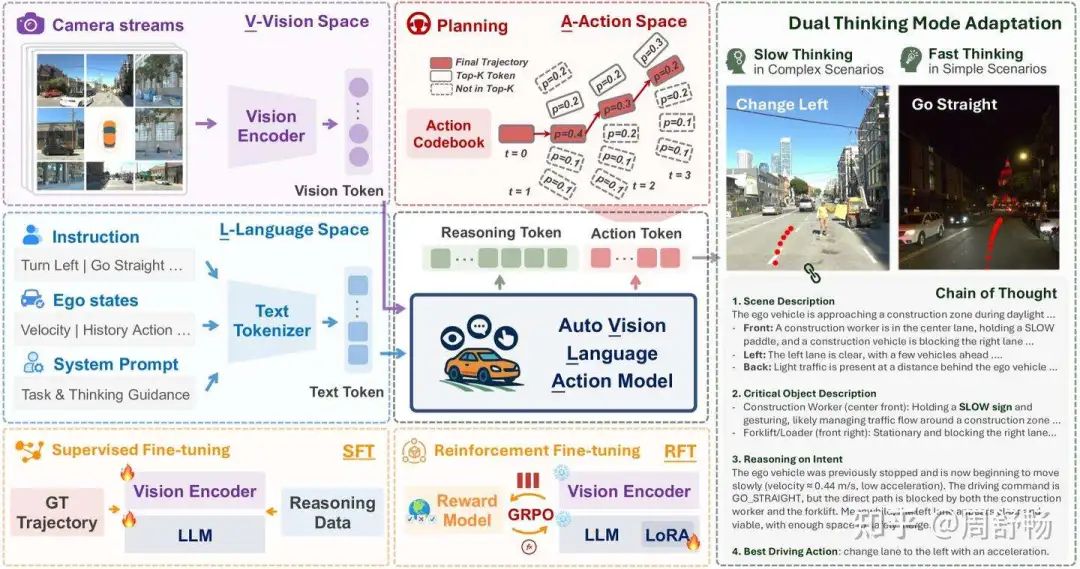
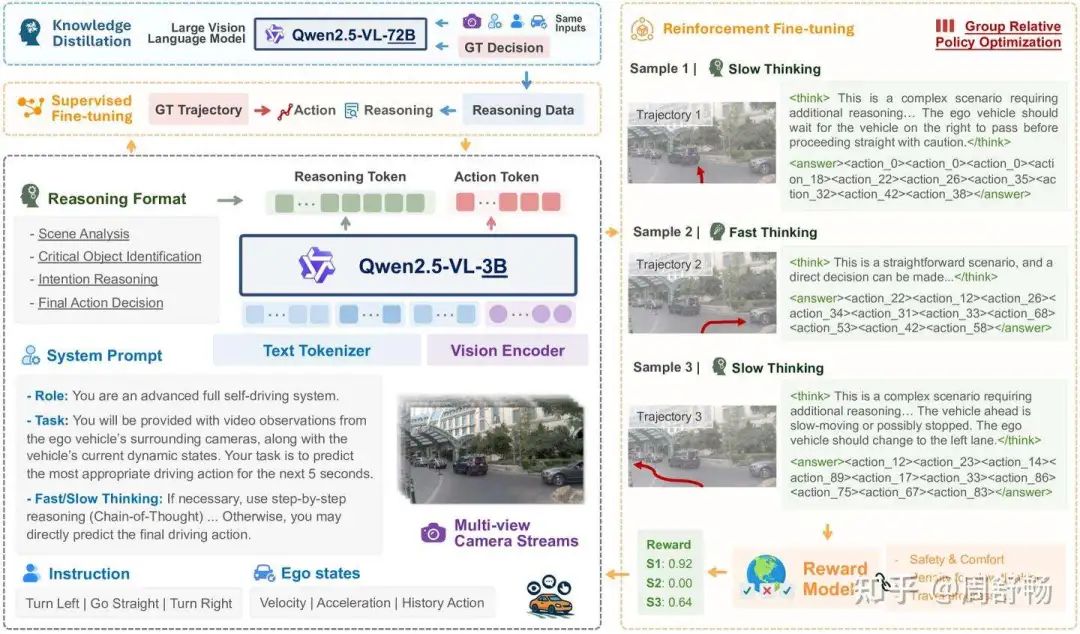
物理动作Token化 (Physical Action Tokenization): 这是AutoVLA最具变革性的思想。它没有让模型输出文本形式的坐标点,而是:
首先,从大规模真实驾驶数据(如Waymo Open Motion Dataset)中,通过K-Disk聚类算法,构建一个包含2048个离散“动作基元”的动作代码本 (Action Codebook)。 每个动作基元代表一个短时(如0.5秒)的、物理可行的车辆运动(位移+姿态变化)。
然后,将连续的驾驶轨迹离散化为一连串的动作Token序列
a = [a_1, ..., a_T]。最后,将这些动作Token(如
<action_0>,<action_1>, ...)作为新的词汇加入到VLM的词表中。 通过这种方式,轨迹规划任务被完美地转化为了一个标准的下一Token预测任务,这正是LLM的强项。
双模式思维与监督微调 (SFT): 模型通过监督微调学习两种决策模式:快速思维: 对于简单的场景,训练数据只包含最终的动作Token序列。模型学习直接输出动作。慢速思维: 对于复杂的场景,训练数据包含结构化的思维链(CoT)文本,后面再跟着动作Token序列。模型学习先进行显式推理,再做出决策。 这使得模型能够根据场景的复杂性自适应地调整其推理深度,兼顾了效率和效果。其SFT损失函数结合了标准的语言模型损失和针对动作Token的辅助损失:
其中 w_i 是一个权重因子,用于激励模型学习带有CoT的样本。
基于强化学习的策略优化 (RFT): 这是AutoVLA的另一个核心优势。在SFT之后,模型会进入RFT阶段,进一步提升其驾驶策略:
奖励函数设计: 使用经过验证的、复杂的驾驶评估指标作为奖励信号,例如nuPlan的PDMS (Predictive Driver Model Score), 它综合了安全性、舒适性和行车效率。此外,还引入了对过长CoT的惩罚项 r_CoT,鼓励模型进行高效推理。GRPO算法: 采用Group Relative Policy Optimization算法进行微调。该方法通过从旧策中采样一组候选轨迹,并根据奖励函数计算其相对优势,来稳定地优化当前策略。 其优化目标为:
RFT使模型摆脱了对人类专家数据的纯粹模仿,转而直接为“成为一个好司机”这一最终目标进行优化。
主要贡献与优势
优雅的决策与控制统一: 动作Token化巧妙地将连续控制问题转化为VLM的舒适区,实现了端到端的高度整合。
自适应推理能力: 双模式思维让模型在效率和深度之间取得了动态平衡。
超越模仿学习的性能上限: RFT使模型能够学习到比示教数据更优的驾驶策略,在nuPlan、Waymo、CARLA等多个极具挑战性的真实和仿真 benchmarks 上都取得了顶级性能。
高效推理: RFT阶段对不必要推理的惩罚,显著降低了模型在简单场景下的平均推理时间。
局限性
对计算资源的高度依赖: SFT尤其是RFT阶段需要大量的GPU资源和时间,这使得模型的训练成本较高。
实时部署挑战: 尽管推理效率有所优化,但模型本身的规模和自回归解码过程仍然对车载硬件的实时部署构成挑战。
3. 深度比较与总结
为了更清晰地展示两者的异同,我们可以用一个表格来总结:
特征 | OpenDriveVLA | AutoVLA |
|---|---|---|
核心哲学 | 感知-语言对齐 (Perception-to-Language):让VLM更好地理解3D世界。 | 语言-决策一体化 (Language-to-Action):让VLM成为更好的决策智能体。 |
视觉信息处理 | 结构化、分层Token (Agent, Map, Scene),通过专用QFormer提取。 | 直接使用标准的VLM视觉编码器处理多帧图像,依赖模型自身注意力。 |
动作生成方式 | 自回归生成文本形式的坐标点,然后解码为轨迹。 | 自回归生成离散的动作Token,通过代码本解码为轨迹。 |
训练范式 | 多阶段监督学习 (对齐 -> 指令微调 -> 交互 -> 规划)。 | 两阶段学习 (监督微调SFT -> 强化学习微调RFT)。 |
主要创新点 | 1. 分层视觉Token化。 | 1. 物理动作Token化。 |
优势 | 3D空间接地能力强,可解释性好(在感知层面),有效抑制空间幻觉。 | 端到端整合度极高,决策策略可通过RL持续优化,性能上限高,推理模式自适应。 |
局限性 | 缺乏显式CoT,性能依赖监督数据质量,实时性有待优化。 | 训练成本高,对算力要求苛刻,动作代码本的完备性影响泛化能力。 |
总结性评述:
OpenDriveVLA 和 AutoVLA 代表了VLA在自驾驶领域发展的两个重要且互补的方向。
OpenDriveVLA 像是在为建造摩天大楼打下坚实的地基。它专注于解决最根本的3D感知理解问题,通过结构化的方式为VLM提供干净、准确、高信息量的输入。这种方法在当前阶段可能更稳定、更易于调试,因为它将复杂的感知问题在输入端就进行了有效约束。
AutoVLA 则是在坚实地基之上构建摩天大楼本身。它假设VLM已经具备了一定的视觉理解能力,然后着力于打通从“思考”到“行动”的最后一公里。其动作Token化和RFT范式极具前瞻性,它将模型的角色从一个“旁观者”彻底变为了“驾驶员”,使其能够通过与环境(或其奖励模型)的交互来不断完善自身,这为实现超越人类水平的驾驶策略提供了清晰的路径。
未来的终极模型很可能是两者的结合体:采用OpenDriveVLA的结构化感知前端,为模型提供高质量的3D界表征;同时,采用AutoVLA的动作Token化和强化学习后端,来训练一个真正懂得思考、决策和演进的驾驶智能体。 这两篇论文共同为我们描绘了通往更智能、更可靠的端到端自动驾驶系统的光明前景。
自动驾驶之心
论文辅导来啦

自驾交流群来啦!
自动驾驶之心创建了近百个技术交流群,涉及大模型、VLA、端到端、数据闭环、自动标注、BEV、Occupancy、多模态融合感知、传感器标定、3DGS、世界模型、在线地图、轨迹预测、规划控制等方向!欢迎添加小助理微信邀请进群。

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 235
235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









