





点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享阿里巴巴和昆士兰大学等团队最新的工作 — AutoDrive-R²!全新自反思思维链数据集,结合基于物理奖励的GRPO取得自动驾驶VLA最新SOTA。如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群加入,也欢迎添加小助理微信AIDriver005做进一步咨询
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | Zhenlong Yuan等
编辑 | 自动驾驶之心
近期自动驾驶VLA通过融合多模态感知与决策能力,已经展现出下一代智能驾驶量产方案的潜力。然而,决策过程的可解释性、连贯性以及动作序列的合理性仍未得到充分研究。为解决这些问题,阿里巴巴和昆士兰大学的团队提出AutoDrive-R²——一种新型VLA框架,该框架通过思维链处理与强化学习,同时增强自动驾驶系统的推理与自反思能力。具体而言:
首先构建了一个用于监督微调SFT的全新CoT数据集,命名为nuScenesR²-6K;该数据集通过包含自反思验证的四步逻辑链,有效搭建了输入信息与输出轨迹之间的认知桥梁。
其次为在RL阶段最大化模型的推理与自反思能力,本文进一步在基于物理的奖励框架内采用GRPO算法;该奖励框架整合了空间对齐、车辆动力学与时间平滑性准则,以确保轨迹规划的可靠性与真实性。
在nuScenes和Waymo两个数据集上的大量评估结果表明,所提方法具备SOTA的性能与强大的泛化能力。

论文链接:https://arxiv.org/abs/2509.01944
引言
近年来,自动驾驶技术取得了快速发展。这类系统通常以传感器数据为输入,以规划轨迹为输出。传统流水线方法大多采用“感知-建图-预测-规划”模块化的架构,该设计存在两个关键局限性:一是误差累积,二是各组件间缺乏联合优化,最终导致性能下降。与之相比,现代方法将这些复杂系统统一为单一的端到端范式,天然具备三大优势:系统简化、鲁棒性增强与误差累积减轻。
然而,这些端到端方法的核心聚焦于轨迹规划,缺乏复杂驾驶场景所需的情景推理能力。为解决这一局限,近期研究将视觉-语言模型(Vision-Language Models, VLMs)集成到自动驾驶系统中,借助VLM的预训练推理能力,提升复杂场景下的决策性能。与传统“从零开始训练感知-策略模块”的方法不同,基于VLM的方法通过在数百万图像-文本对上预训练,对预训练模型进行微调,使车辆能够理解动态交通场景并制定复杂的导航策略。尽管已取得良好效果,现有系统在持续生成准确规划输出方面仍存在不足。
在VLM的基础上,视觉-语言-动作(VLA)模型进一步将推理能力扩展到最终动作预测,使机器人与自动驾驶车辆能够从视觉输入和文本指令中生成精确动作。这一进展推动自动驾驶领域采用类似的动作生成机制,例如π0提出了“action tokenizers”,用于预测精确轨迹。
但当前自动驾驶领域的VLA方法仍面临两个阻碍实际部署的关键局限:
轨迹生成框架常产生物理不可行输出:现有通过VLM直接生成文本指令或路径点的方法,频繁出现物理不可行输出与模型坍缩问题。尽管有研究提出“元动作”或“潜在动作token”等中间表示以缓解这些问题,但此类设计违背了端到端优化原则,且大幅增加模型复杂度开销。
复杂场景下推理能力不足:多数方法采用简单推理策略,无法同时兼顾复杂道路状况与车辆运动学约束,导致预测轨迹严重偏离现实需求。
这些局限凸显了研发新型VLA框架的迫切性——该框架需平衡架构简洁性、强大的情境理解能力与严格的物理约束。
为克服上述挑战,本文提出AutoDrive-R²,一种新型VLA框架,通过两阶段训练方法同时提升推理质量与物理可行性。核心思路在于:有效的自动驾驶需要可系统验证与优化的结构化推理过程。具体而言,为解决复杂场景下情境推理不足的问题,本文首先构建了用于监督微调的思维链(CoT)数据集nuScenesR²-6K。nuScenesR²-6K是自动驾驶领域首个同时激发VLA模型推理与自反思能力的数据集;与以往自动驾驶数据集不同,该数据集不仅提供真值轨迹,还包含推理与自反思步骤,确保驾驶行为的正确性与因果合理性。
此外,为解决物理不可行轨迹生成的难题,本文进一步针对自动驾驶任务的组相对策略优化(GRPO),设计了基于物理的奖励框架。该框架通过明确纳入空间对齐、车辆动力学与时间平滑性约束,使强化学习能够适应不同驾驶场景与车辆动力学特性,同时保证轨迹的物理可行性与行驶舒适性。在nuScenes和Waymo数据集上的全面实验表明,AutoDrive-R²实现了最先进的性能。本文的主要贡献如下:
提出AutoDrive-R²——一种新型VLA框架,能够基于视觉信息与语言指令,实现带自反思步骤的语义推理与轨迹规划。
构建nuScenesR²-6K数据集:该创新性CoT数据集采用含自反思的四步逻辑链,助力模型在监督微调后建立基础感知能力。
提出基于GRPO的RL后续训练方法:该方法将基于物理的奖励作为约束,优化不同场景下的规划轨迹。
相关工作回顾
自动驾驶
近年来,自动驾驶技术已从传统的“感知-在线建图-预测-规划”模块化流水线,逐步向端到端基于学习的方法演进。UniAD首次将所有子任务集成到一个级联模型中,相比传统模块化方法实现了显著性能提升。部分方法通过提取BEV特征,并通过多阶段交互建模预测规划轨迹。
随着视觉-语言模型的兴起,研究人员越来越多地将大语言模型与VLMs集成到自动驾驶系统中,以提升整体系统性能。已有多种方法引入预训练LLM,生成驾驶动作及可解释的文本说明。此外,DriveVLM通过集成专用推理模块提升场景理解能力;DriveMM处理多视图视频与图像输入,以增强车辆控制的泛化性;DriveMLM则引入行为规划模块,生成带合理依据的最优驾驶决策。
此外,视觉-语言-动作(Vision-Language-Action, VLA)模型在机器人领域的近期成功,为自动驾驶提供了新的研究视角。DriveMoE基于具身AI框架π0构建,通过训练路由网络激活针对不同驾驶行为的专家模块,引入了动作专家混合(Action-MoE)机制。此外,OpenDriveVLA提出“智能体-环境-自车”交互模型,用于精确轨迹规划;AutoVLA则直接从视觉输入与语言提示中预测语义推理结果与轨迹规划方案。
通用视觉-语言模型
近年来,大型语言模型(LLMs)的成功推动研究人员将其扩展为视觉-语言模型(VLMs)——这类模型融合文本与视觉数据,实现更丰富的多模态表示。开创性工作CLIP(对比语言-图像预训练)通过图像编码器与文本编码器结合,采用零样本学习策略,预测图像-文本样本对的正确匹配关系。类似地,BLIP与BLIP-2通过图像-文本对比(image-text contrastive, ITC)损失实现视觉与语言表示的对齐,并借助图像-文本匹配(image-text matching, ITM)损失区分正负图像-文本对,从而增强基于文本上下文的视觉表示能力。
受这些方法启发,许多VLMs(如LLaVA与Qwen2.5-VL)通过将大型语言模型作为文本编码器(如LLaMA),进一步提升了预训练视觉编码器的鲁棒性与表示能力。OmniGen2是另一类典型VLMs,其为文本与图像模态设计了两条独立的解码路径,采用非共享参数与解耦图像token化器。值得注意的是,DeepSeekV3引入了鲁棒的专家混合(Mixture-of-Experts, MoE)语言模型,采用无辅助损失策略实现负载均衡,在推理效率与成本效益上均有优势。
用于后续训练的强化学习
强化学习(Reinforcement Learning, RL)已被广泛应用于大型语言模型,研究人员发现,基于人类反馈的强化学习 - RLHF能显著提升模型的推理能力。在这些方法中,PPO最初用于模拟机器人运动与Atari游戏环境,随后被OpenAI用于微调GPT,在文本生成任务中实现了大幅性能提升。
与传统RLHF方法不同,DPO提出了一种新的奖励模型参数化方式,无需在微调过程中进行采样。奖励微调(Reward Fine-Tuning, RFT)是另一种基于RL的方法,在数学推理任务中表现出优异性能。此外,GRPO无需依赖外部工具包或投票机制,即可有效提升LLMs的推理能力。例如,DeepSeek-R1利用GRPO对模型进行微调,性能优于现有方法。组策略梯度(Group Policy Gradient, GPG)是一种极简RL方法,无需监督微调或复杂技巧即可提升大型语言模型的推理能力,且在多种任务中表现出强性能。受这些方法启发,近期有研究采用类似微调策略,以提升多模态模型的推理能力。
AutoDrive-R²算法详解
概述
本节将对AutoDrive-R²进行概述。轨迹规划任务的目标是让模型基于车辆的历史传感器数据与上下文信息,预测其未来运动状态。形式化定义为:给定车辆历史状态序列 (包含位置、加速度、速度、转向角等信息)与相机图像 ,模型 输出未来3秒内、以0.5秒为时间间隔的BEV轨迹坐标 ,其数学表达式为 。
如图2所示,我们的训练过程分为两个阶段。第一阶段,构建高质量冷启动数据集nuScenesR²-6K,通过包含自反思验证的四步逻辑链,搭建输入信息与输出轨迹之间的认知桥梁;第二阶段,采用基于物理的强化学习框架,该框架整合了空间对齐、车辆动力学与时间平滑性准则,以确保生成物理可行且安全的轨迹。
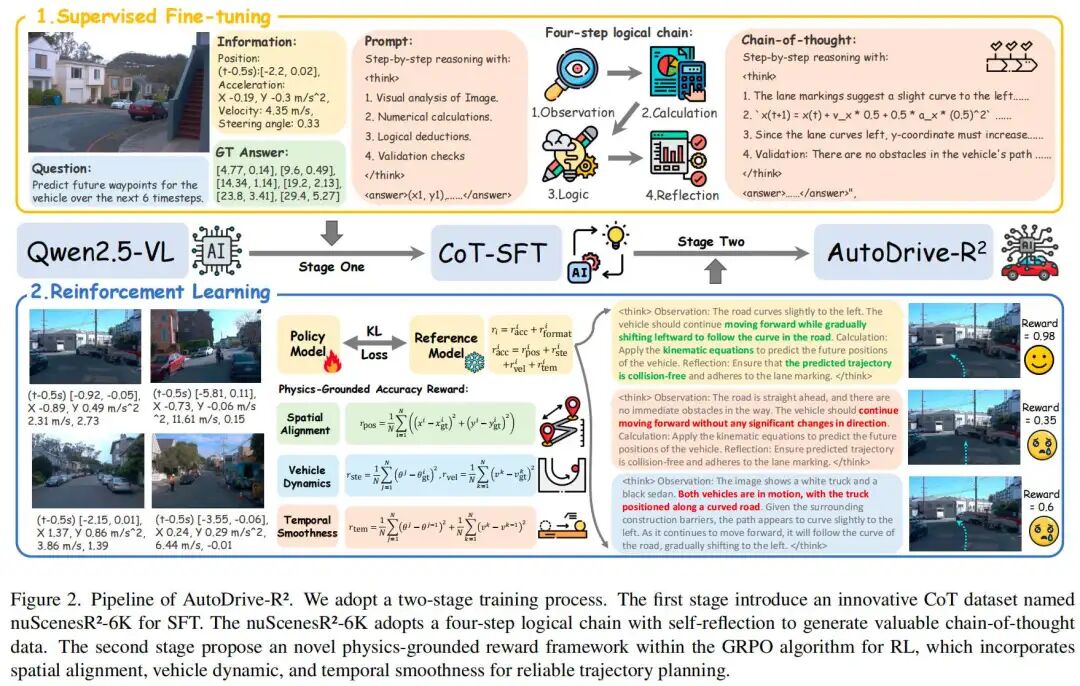
含自反思的逻辑思维链(CoT)数据集
视觉-语言-动作(VLA)模型在自动驾驶领域的成功,关键在于其能否同时生成可解释的推理过程与物理可行的动作。然而,现有训练方法往往难以满足这一双重需求,导致模型要么缺乏可解释的决策过程,要么生成不切实际的轨迹。为探究这一问题,我们最初借鉴基于推理的强化学习(RL)最新进展,尝试直接通过强化学习优化轨迹规划,但初步实验表明,仅通过强化学习训练的模型,其轨迹规划性能显著低于先经过监督微调(SFT)再进行强化学习的模型。因此,我们提前构建了高质量冷启动数据集nuScenesR²-6K,以训练模型在轨迹规划方面的基础理解能力。
具体而言,我们从nuScenes训练集中手动标注了6000个“图像-轨迹”样本对,随后利用先进的Qwen2.5-VL-72B模型合成思维链(CoT)推理序列。如图2(a)所示,给定前视图图像、车辆历史状态(作为输入)与对应的真值轨迹(作为输出),我们预先定义了特定的CoT提示词,引导模型按照以下格式构建推理序列:“推理过程在此处((x₁, y₁), ..., (xₙ, yₙ))”。
此外,我们观察到,现有许多方法依赖通用提示词实现“问题-答案”的推理,缺乏用于理性分析的结构化引导。这种策略在简单任务中虽有效果,但在面对复杂数学或逻辑问题时往往失效。为解决这一局限,我们的CoT提示词设计将轨迹规划系统地分解为三个相互关联的推理阶段:
图像驱动分析:建立基础场景理解(如障碍物与车道定位、交通标志检测),为后续推理奠定基础。
基于物理的计算:利用运动学方程(如角动量守恒)将抽象观测转化为可量化的预测结果。
上下文逻辑综合:整合领域特定知识(如交叉路口交通规则),确保预测结果符合真实世界的驾驶规范。
为进一步提升模型的鲁棒性与答案正确性,我们借鉴数学推理框架中“通过反向验证结论”的思路,明确引入“自反思”作为第四步。这一步骤使模型能够验证自身推理的连贯性,并修正潜在矛盾。因此,我们的提示词实现了四步逻辑链:
可视化 → 计算 → 逻辑 → 反思
该逻辑链可实现系统性且抗误差的推理,详细内容见补充材料。
最终,nuScenesR²-6K数据集用于Qwen2-VL-7B模型的监督微调,从而得到第一阶段模型。该预训练模型能够通过“结构化、分步式且包含自反思”的推理机制,有效实现轨迹规划。
GRPO
我们遵循GRPO算法对模型进行训练。与依赖评论家网络(critic networks)估计价值函数的传统方法不同,GRPO引入了候选响应间的成对比较(pairwise comparison)机制。这种设计不仅简化了架构,还降低了训练过程中的计算开销。该方法的流程为:对于给定的输入问题 ,通过策略采样生成
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









