





点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享麦吉尔大学、清华大学、小米公司和威斯康辛麦迪逊的研究团队最新的工作!面向自动驾驶的视觉-语言-动作模型综述!如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
>>自动驾驶前沿信息获取→自动驾驶之心知识星球
论文作者 | Sicong Jiang等
编辑 | 自动驾驶之心
“自动驾驶未来已来?”
当视觉(Vision)、语言(Language)和行动(Action)三大能力在一个模型中融合,自动驾驶的未来将走向何方?
近日,来自麦吉尔大学、清华大学、小米公司和威斯康辛麦迪逊的研究团队联合发布了全球首篇针对自动驾驶领域的视觉-语言-行动(Vision-Language-Action, VLA)模型的全面综述。这篇题为《A Survey on Vision-Language-Action Models for Autonomous Driving》的论文,系统性地梳理了VLA在自动驾驶(VLA4AD)领域的前沿进展,深入剖析了其架构演进、核心技术与未来挑战。
论文GitHub仓库已同步上线,收录了超过20个代表性模型和相关数据集。
论文链接:https://arxiv.org/abs/2506.24044
GitHub链接:
https://github.com/JohnsonJiang1996/Awesome-VLA4AD
从“端到端”到“VLA”:自动驾驶范式的演进
自动驾驶技术的发展经历了从模块化到一体化的演进。该综述将最新的自动驾驶技术发展总结为三大核心范式:
端到端自动驾驶 (End-to-End AD): 这种模式将传感器输入直接映射到驾驶动作,省去了复杂的中间模块。虽然高效,但其“黑箱”特性导致可解释性差,难以处理需要高级推理的“长尾”场景。
-
架构: 环境信息输入 → 端到端网络 → 驾驶动作。
用于自动驾驶的视觉语言模型 (VLMs for AD): 随着大语言模型(LLM)的兴起,研究者开始将语言的理解和推理能力引入自动驾驶。VLM能够解释复杂的交通场景、回答相关问题,显著提升了系统的可解释性和对罕见事件的泛化能力。然而,这些模型主要停留在“感知和理解”,语言输出与车辆的实际控制脱节,存在“行动鸿沟”。
-
架构: 环境信息输入 → VLM → 推理链/多任务 → 输出(非直接控制)。
用于自动驾驶的视觉-语言-行动模型 (VLA for AD): VLA模型是当前最前沿的范式。它在一个统一的策略中融合了视觉感知、语言理解和动作执行。VLA旨在打造能够理解高级指令、推理复杂场景并自主决策的智能车辆。VLA模型不仅能遵循“让行救护车”这类自然语言指令,还能用语言解释其决策原因,实现了感知、推理和行动的闭环。
-
架构: 环境信息输入 → 多模态编码器 → LLM/VLM → 动作解码器 → 驾驶动作。
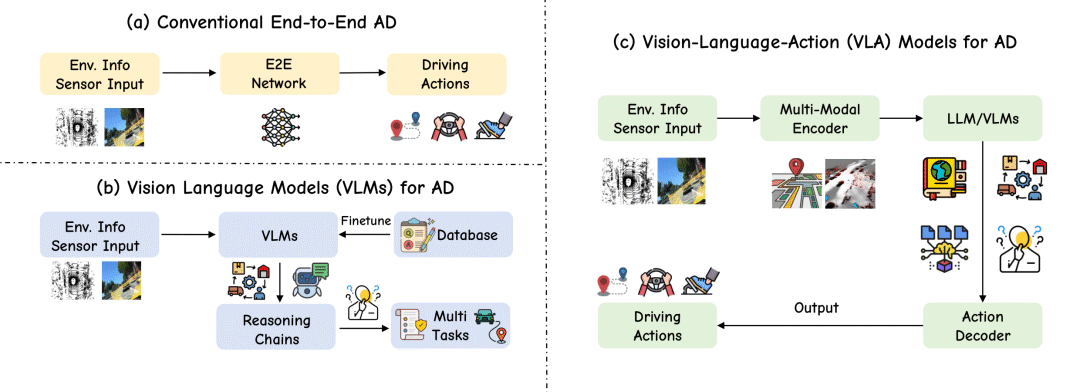
VLA4AD的架构范式
一个典型的VLA4AD模型架构由“输入-处理-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 308
308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









