





通过前面的两篇博文,大家已经可以使用LLaMA-Factory工具进行简单的推理和基于LoRA的指令监督微调(SFT),也算是对大模型有了一个大概的了解;那么这一篇博文,我就结合LLaMA-Factory工具和我的了解认知,总结一下我认识的大模型训练、微调和量化,为后续的实操建立一个理论基础;
一、大模型的训练
大模型的训练也称为预训练,其通过在一个大型的通用数据集上通过无监督学习的方式学习未被标记的文本进行预训练来学习语言的表征,初始化模型权重,学习概率分布;通常,预训练数据集从互联网上获得,因为互联网上提供了大量的不同领域的文本信息,有助于提升模型的泛化能力;在预训练结束后,模型的参数得到初始化,模型能够理解语义、语法以及识别上下文关系,在处理一般性任务时有着不错的表现。
1.1 PT (Pretrain, 预训练)
- 定义:预训练是指在大规模无标注数据上训练模型,使其学习通用的语言表示能力。
- 作用:让模型具备广泛的知识基础和语言理解能力,为后续任务提供强大的初始参数。
- 常见方法:自监督学习(如 Masked Language Modeling, Causal Language Modeling)。
1.2 数据处理
预训练的数据集在LLaMA-Factory中一般使用的是Alpaca格式,其数据集文本描述格式如下:
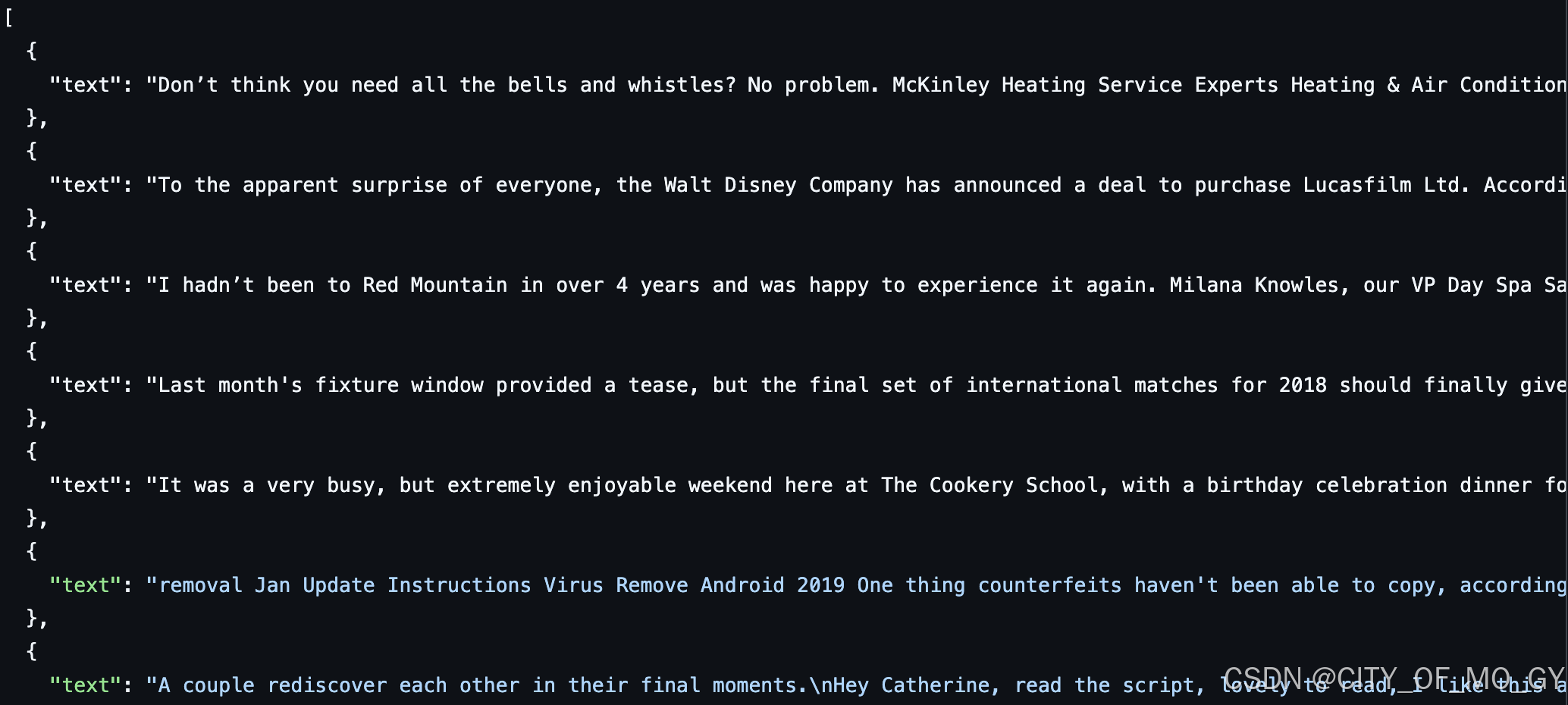
[
{"text": "document"},
{"text": "document"}
] 数据样例如下图所示,在预训练时,只有 text 列中的内容会用于模型学习,模型通过生成对下一个词的预测来完成自监督学习:
二、大模型的微调
尽管模型通过预训练涌现出了零样本学习,少样本学习的特性,使其能在一定程度上完成特定任务, 但仅通过提示(prompt)并不一定能使其表现令人满意。因此,我们需要后训练(post-training)来使得模型在特定任务上也有足够好的表现,也就是常说的Fine-Tuning;
对于大模型的微调,应该从两个方面考虑,一方面是基于不同策略的微调,另一方面是基于不同参数的微调;
2.1 基于不同策略的微调
2.1.1 SFT监督微调(Supervised Fine-Tuning)
Supervised Fine-Tuning(监督微调)是一种在预训练模型上使用小规模有标签数据集进行训练的方法。 相比于预训练一个全新的模型,对已有的预训练模型进行监督微调是更快速更节省成本的途径;
2.1.1.1 定义
- 定义:监督微调是使用高质量的人类标注数据对预训练模型进行进一步训练,使其更好地适应特定任务。
- 作用:提升模型在特定场景下的表现,减少输出与人类期望之间的偏差。
- 过程:使用输入-输出配对数据进行有监督训练。
2.1.1.2 数据处理
SFT的数据集在LLaMA-Factory中支持两种格式,分别是Alpaca格式、ShareGPT格式;
2.1.1.2.1 Alpaca格式的SFT
instruction 列对应的内容为人类指令, input 列对应的内容为人类输入, output 列对应的内容为模型回答;
[
{
"instruction": "用户指令(必填)",
"input": "用户输入(选填)",
"output": "模型回答(必填)"
}
]数据样例如下所示:
"alpaca_zh_demo.json"
{
"instruction": "计算这些物品的总费用。 ",
"input": "输入:汽车 - $3000,衣服 - $100,书 - $20。",
"output": "汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。"
}, 在进行指令监督微调时, instruction 列对应的内容会与 input 列对应的内容拼接后作为最终的人类输入,即人类输入为 instruction\ninput</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 22万+
22万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









