



训练自己的计算机视觉模型,怎么少的了数据标注工具的加持,labelme可用于目标检测、关键点检测等多种视觉任务的数据标注,是一个比较优秀的开源标注工具;接下来我就以关键点标注为例,演示一下labelme从安装到使用的全部流程。
一、安装并运行
这里我使用的是MacOS系统的电脑,其他系统也是大同小异,Windows的话直接有免安装的exe可执行文件,无需自己安装;
1、创建并激活python虚拟环境
conda create --name labelme python=3.8.0
conda activate labelme
2、 安装labelme
pip install labelme -i https://pypi.tuna.tsinghua.edu.cn/simple
3、运行Labelme
# 在虚拟环境为labelme的终端中运行
labelme
运行成功会出现如下界面:
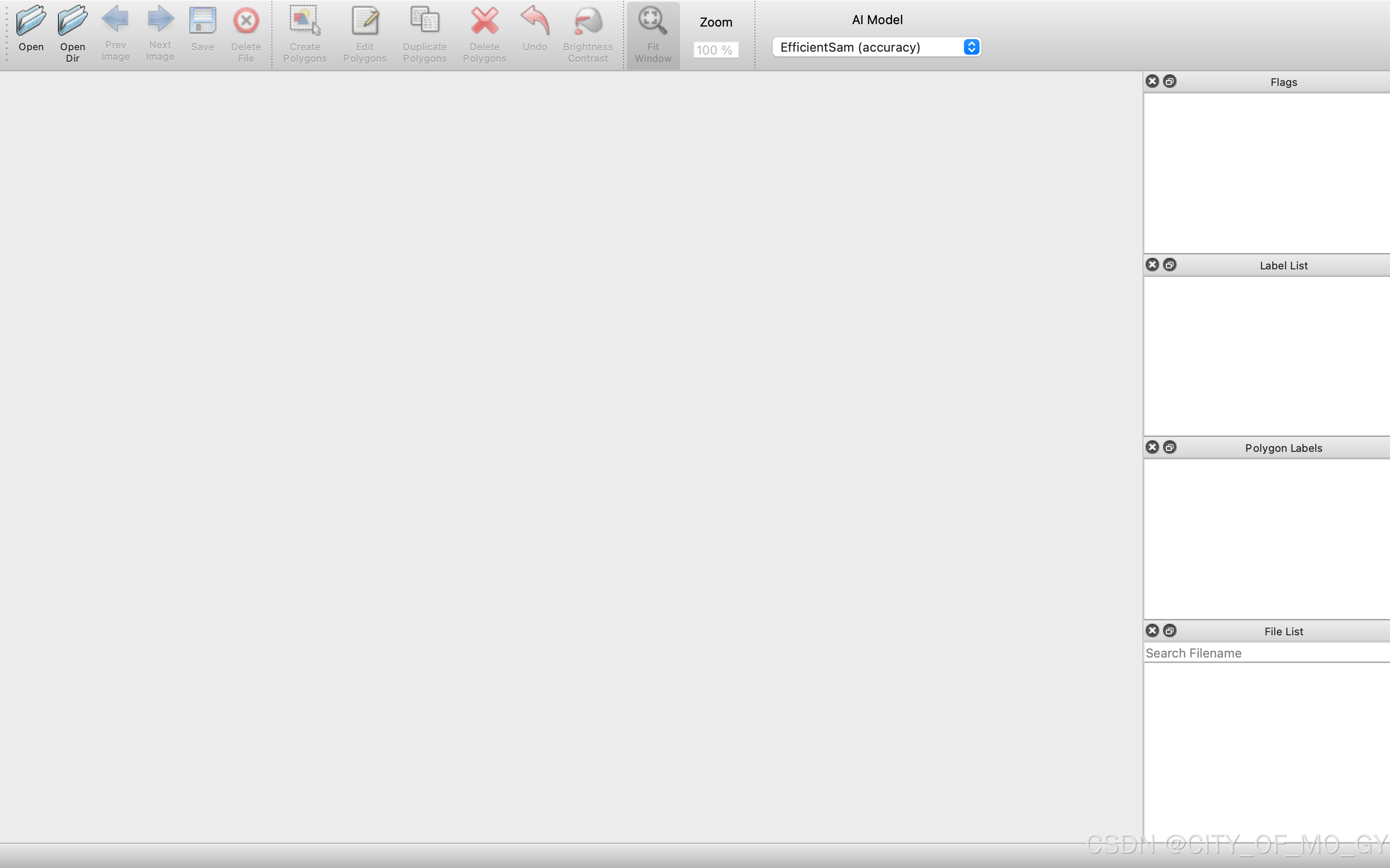
二、标注关键点
1、加载预标注图片文件夹:

2、选择Edit,Create Point:

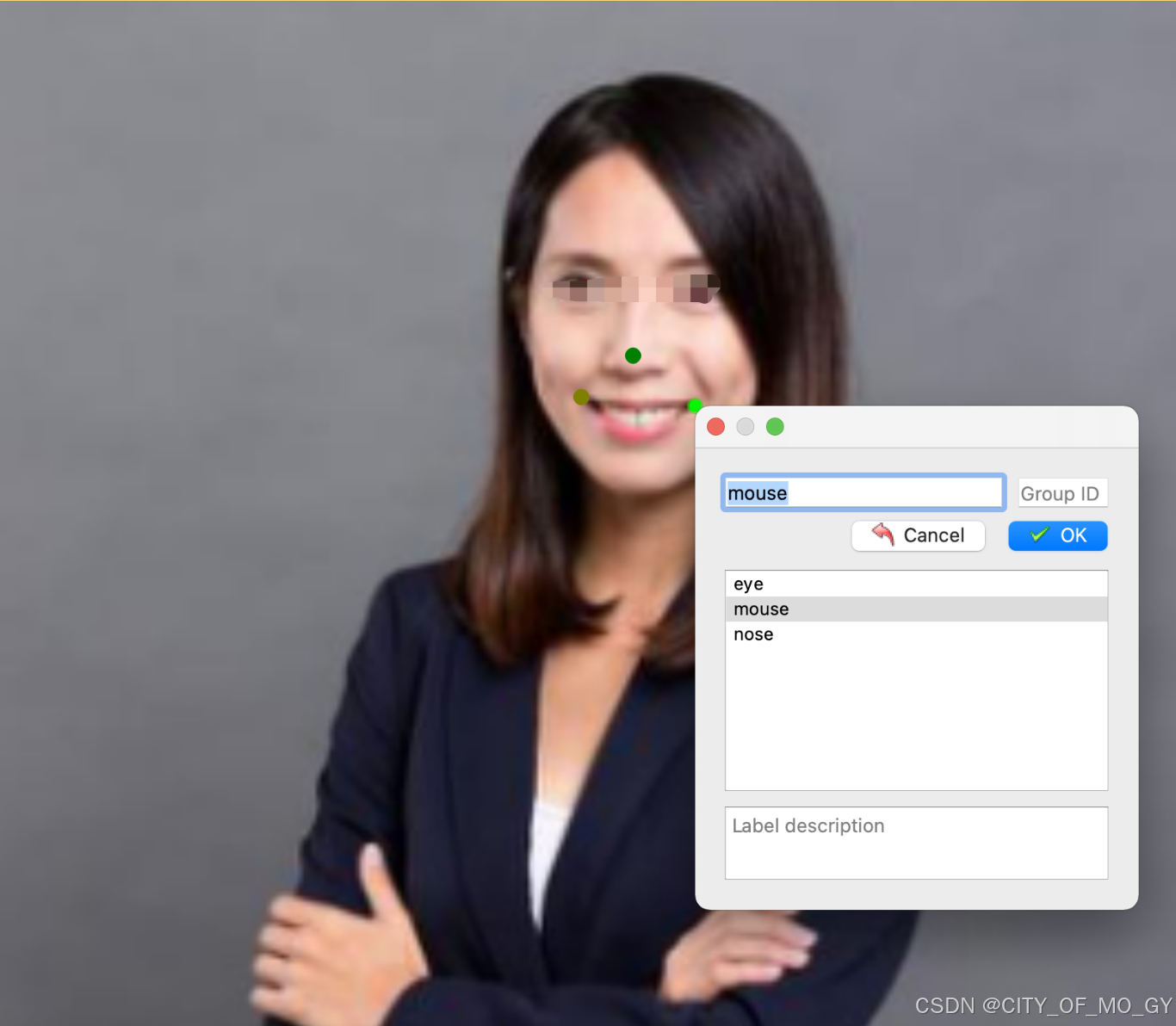 3、标注完成后点击save,会生成一个和图片名称相同的json文件,该文件就是该图片的标签,在关键点标注任务中,需要特别注意的一个点是:
3、标注完成后点击save,会生成一个和图片名称相同的json文件,该文件就是该图片的标签,在关键点标注任务中,需要特别注意的一个点是:
1)不管你的标签关键点在图片里面是否被遮挡,都要标注出来;
2)标注的关键点不需要有刻板的顺序,但同一批标注的训练数据的关键点标注顺序必须是一致的;
三、标注标签转换
在yolo系列模型的训练中,yolo模型只能识别自己特定的标签格式,这时就需要将json格式的文件转换为yolo模型可以解析的标签格式,下面就以yolov8的关键点检测格式为例,对标注的json格式标签进行格式转换;
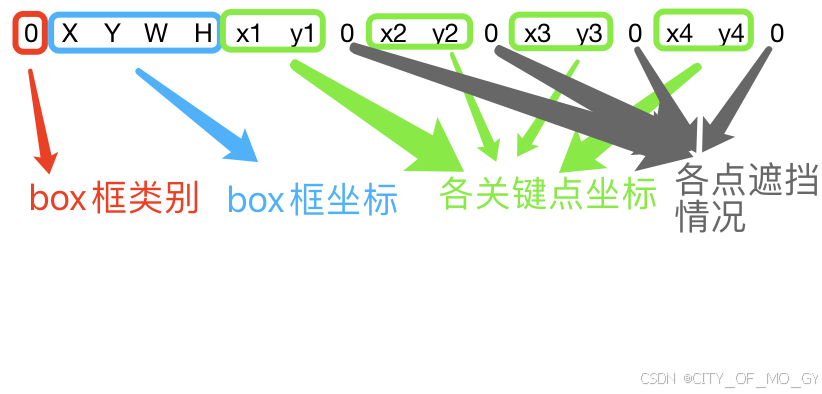
1、yolov8关键点识别模型标签格式解析:
首先,训练集中每一张图片对应一个同名的txt文件作为标签,标签中每一行代表一组标记实体,格式及含义如下:
2、json格式转为coco格式:
import os
import sys
import glob
import json
import argparse
import numpy as np
from tqdm import tqdm
from labelme import utils
class Labelme2coco_keypoints():
def __init__(self, args):
self.classname_to_id = {args.class_name: 1}
self.images = []
self.annotations = []
self.categories = []
self.ann_id = 0
self.img_id = 0
def save_coco_json(self, instance, save_path):
json.dump(instance, open(save_path, 'w', encoding='utf-8'), ensure_ascii=False, indent=1)
def read_jsonfile(self, path):
with open(path, "r", encoding='utf-8') as f:
return json.load(f)
def _get_box(self, points):
min_x = min_y = np.inf
max_x = max_y = 0
for x, y in points:
min_x = min(min_x, x)
min_y = min(min_y, y)
max_x = max(max_x, x)
max_y = max(max_y, y)
return [min_x, min_y, max_x - min_x, max_y - min_y]
def _get_keypoints(self, points, keypoints, num_keypoints):
if points[0] == 0 and points[1] == 0:
visable = 0
else:
visable = 1
num_keypoints += 1
keypoints.extend([points[0], points[1], visable])
return keypoints, num_keypoints
def _image(self, obj, path):
image = {}
img_x = utils.img_b64_to_arr(obj['imageData']) # 获得原始 labelme 标签的 imageData 属性,并通过 labelme 的工具方法转成 array
image['height'], image['width'] = img_x.shape[:-1] # 获得图片的宽高
# self.img_id = int(os.path.basename(path).split(".json")[0])
self.img_id = self.img_id + 1
image['id'] = self.img_id
image['file_name'] = os.path.basename(path).replace(".json", ".jpg")
return image
def _annotation(self, bboxes_list, keypoints_list, json_path):
"""
生成coco标注
Args:
bboxes_list: 矩形标注框
keypoints_list: 关键点
json_path:json文件路径
"""
if len(keypoints_list) != args.join_num * len(bboxes_list):
print('you loss {} keypoint(s) with file {}'.format(args.join_num * len(bboxes_list) - len(keypoints_list), json_path))
print('Please check !!!')
sys.exit()
i = 0
for object in bboxes_list:
annotation = {}
keypoints = []
num_keypoints = 0
label = object['label']
bbox = object['points']
annotation['id'] = self.ann_id
annotation['image_id'] = self.img_id
annotation['category_id'] = int(self.classname_to_id[label])
annotation['iscrowd'] = 0
annotation['area'] = 1.0
annotation['segmentation'] = [np.asarray(bbox).flatten().tolist()]
annotation['bbox'] = self._get_box(bbox)
for keypoint in keypoints_list[i * args.join_num: (i + 1) * args.join_num]:
point = keypoint['points']
annotation['keypoints'], num_keypoints = self._get_keypoints(point[0], keypoints, num_keypoints)
annotation['num_keypoints'] = num_keypoints
i += 1
self.ann_id += 1
self.annotations.append(annotation)
def _init_categories(self):
"""
初始化 COCO 的 标注类别
例如:
"categories": [
{
"supercategory": "hand",
"id": 1,
"name": "hand",
"keypoints": [
"wrist",
"thumb1",
"thumb2",
...,
],
"skeleton": [
]
}
]
"""
for name, id in self.classname_to_id.items():
category = {}
category['supercategory'] = name
category['id'] = id
category['name'] = name
# 17 个关键点数据
category['keypoint'] = [str(i + 1) for i in range(args.join_num)]
self.categories.append(category)
def to_coco(self, json_path_list):
"""
Labelme 原始标签转换成 coco 数据集格式,生成的包括标签和图像
Args:
json_path_list:原始数据集的目录
"""
self._init_categories()
for json_path in tqdm(json_path_list):
obj = self.read_jsonfile(json_path) # 解析一个标注文件
self.images.append(self._image(obj, json_path)) # 解析图片
shapes = obj['shapes'] # 读取 labelme shape 标注
bboxes_list, keypoints_list = [], []
for shape in shapes:
if shape['shape_type'] == 'rectangle': # bboxs
bboxes_list.append(shape) # keypoints
elif shape['shape_type'] == 'point':
keypoints_list.append(shape)
self._annotation(bboxes_list, keypoints_list, json_path)
keypoints = {}
keypoints['info'] = {'description': 'Lableme Dataset', 'version': 1.0, 'year': 2021}
keypoints['license'] = ['BUAA']
keypoints['images'] = self.images
keypoints['annotations'] = self.annotations
keypoints['categories'] = self.categories
return keypoints
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--class_name", default="IDBox", help="class name", type=str)
parser.add_argument("--input", default="./json_dataset", help="json file path (labelme)", type=str)
parser.add_argument("--output", default="./coco_dataset", help="output file path (coco format)", type=str)
parser.add_argument("--join_num", default=4, help="number of join", type=int)
# parser.add_argument("--ratio", help="train and test split ratio", type=float, default=0.5)
args = parser.parse_args()
labelme_path = args.input
saved_coco_path = args.output
json_list_path = glob.glob(labelme_path + "/*.json")
print('{} for json files'.format(len(json_list_path)))
print('Start transform please wait ...')
l2c_json = Labelme2coco_keypoints(args) # 构造数据集生成类
# 生成coco类型数据
keypoints = l2c_json.to_coco(json_list_path)
l2c_json.save_coco_json(keypoints, os.path.join(saved_coco_path, "keypoints.json"))
3、coco转yolo格式:
import os
import json
from tqdm import tqdm
import argparse
parser = argparse.ArgumentParser()
# 这里根据自己的json文件位置,换成自己的就行
parser.add_argument('--json_path',
default='coco/keypoints.json', type=str,
help="input: coco format(json)")
# 这里设置.txt文件保存位置
parser.add_argument('--save_path', default='txt_dataset', type=str,
help="specify where to save the output dir of labels")
arg = parser.parse_args()
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = box[0] + box[2] / 2.0
y = box[1] + box[3] / 2.0
w = box[2]
h = box[3]
x = round(x * dw, 6)
w = round(w * dw, 6)
y = round(y * dh, 6)
h = round(h * dh, 6)
return (x, y, w, h)
if __name__ == '__main__':
json_file = arg.json_path # COCO Object Instance 类型的标注
ana_txt_save_path = arg.save_path # 保存的路径
data = json.load(open(json_file, 'r'))
if not os.path.exists(ana_txt_save_path):
os.makedirs(ana_txt_save_path)
id_map = {} # coco数据集的id不连续!重新映射一下再输出!
with open(os.path.join(ana_txt_save_path, 'classes.txt'), 'w') as f:
# 写入classes.txt
for i, category in enumerate(data['categories']):
f.write(category['name']+"\n")
id_map[category['id']] = i
# print(id_map)
# 这里需要根据自己的需要,更改写入图像相对路径的文件位置。
# list_file = open(os.path.join(ana_txt_save_path, 'train2017.txt'), 'w')
for img in tqdm(data['images']):
filename = img["file_name"]
img_width = img["width"]
img_height = img["height"]
img_id = img["id"]
head, tail = os.path.splitext(filename)
ana_txt_name = head + ".txt" # 对应的txt名字,与jpg一致
f_txt = open(os.path.join(ana_txt_save_path, ana_txt_name), 'w')
for ann in data['annotations']:
if ann['image_id'] == img_id:
box = convert((img_width, img_height), ann["bbox"])
f_txt.write("%s %s %s %s %s" % (id_map[ann["category_id"]], box[0], box[1], box[2], box[3]))
counter=0
for i in range(len(ann["keypoints"])):
if ann["keypoints"][i] == 2 or ann["keypoints"][i] == 1 or ann["keypoints"][i] == 0:
f_txt.write(" %s " % format(ann["keypoints"][i] + 1,'6f'))
counter=0
else:
if counter==0:
f_txt.write(" %s " % round((ann["keypoints"][i] / img_width),6))
else:
f_txt.write(" %s " % round((ann["keypoints"][i] / img_height),6))
counter+=1
f_txt.write("\n")
f_txt.close()


















 1万+
1万+




 到【灌水乐园】发言
到【灌水乐园】发言







