




1,背景描述
在建筑物中,供暖、通风和空调系统的能源消耗占据了很大比例。根据居住情况以需求为导向优化这些系统的使用,是一种提升能效的方法。
本数据集包含了某一房间 4 天内多个异构传感器测量的数据信息,如二氧化碳、温度、照明、声音和运动数据信息。基于这些数据,可以利用机器学习模型来预测估计房间内的居住者人数。
资料来源
2,数据说明
| 字段 | 说明 |
|---|---|
| Date | 日期,格式为日-月-年(DD-MM-YYYY) |
| Time | 时间,格式为小时:分钟:秒(HH:MM:SS) |
| Temperature | 温度,单位为摄氏度(°C) |
| Light | 光照强度,单位为勒克斯(Lux) |
| Sound | 声音电压,从放大器输出读取并由ADC(模数转换器)测量,单位为伏特(V) |
| CO2 | 二氧化碳浓度,单位为ppm(每百万份) |
| CO2 Slope | 在滑动窗口中获取的CO2值的斜率 |
| PIR | 被动红外传感器的二进制值,表示是否检测到运动 |
| Room_Occupancy_Count | 房间占用计数(目标值),真实情况下的房间占用人数(Target) |
| S1-S7 代表不同的传感器序号 |
3,数据来源
https://www.semanticscholar.org/paper/Machine-Learning-Based-Occupancy-Estimation-Using-Singh-Jain/e631ea26f0fd88541f42b4e049d63d6b52d6d3ac
https://www.kaggle.com/datasets/ruchikakumbhar/room-occupancy-estimation
4,问题描述
二分类分析
回归分析
时间序列分析
特征重要性分析
5,数据读取与预处理
import pandas as pd
file_path = '/home/mw/input/02072495/room occupancy.csv'
data = pd.read_csv(file_path)
data.head()
data.shape

data.info()
data.isnull().sum()
# 查看重复值
data.duplicated().sum()
# 描述性统计
data.describe()

# 合并日期和时间为单一的时间戳列
data['Datetime'] = pd.to_datetime(data['Date'] + ' ' + data['Time'], format='%d-%m-%Y %H:%M:%S')
data.drop(['Date', 'Time'], axis=1, inplace=True)
from scipy.stats import spearmanr
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
def plot_spearmanr(data, features, title, wide, height):
# 计算Spearman相关矩阵和p值矩阵
spearman_corr_matrix = data[features].corr(method='spearman')
pvals = data[features].corr(method=lambda x, y: spearmanr(x, y)[1]) - np.eye(len(data[features].columns))
# 将p值转换为星号
def convert_pvalue_to_asterisks(pvalue):
if pvalue <= 0.001:
return "***"
elif pvalue <= 0.01:
return "**"
elif pvalue <= 0.05:
return "*"
return ""
# 应用转换函数
pval_star = pvals.applymap(convert_pvalue_to_asterisks)
# 转换为numpy类型
corr_star_annot = pval_star.to_numpy()
# 定制 labels
corr_labels = spearman_corr_matrix.to_numpy()
p_labels = corr_star_annot
shape = corr_labels.shape
# 合并 labels
labels = (np.asarray(["{0:.2f}\n{1}".format(data, p) for data, p in zip(corr_labels.flatten(), p_labels.flatten())])).reshape(shape)
# 绘制热力图
fig, ax = plt.subplots(figsize=(height, wide), dpi=100, facecolor="w")
sns.heatmap(spearman_corr_matrix, annot=labels, fmt='', cmap='coolwarm',
vmin=-1, vmax=1, annot_kws={
"size":10, "fontweight":"bold"},
linecolor="k", linewidths=.2, cbar_kws={
"aspect":13}, ax=ax)
ax.tick_params(bottom=False, labelbottom=True, labeltop=False,
left=False, pad=1, labelsize=12)
ax.yaxis.set_tick_params(labelrotation=0)
# 自定义 colorbar 标签格式
cbar = ax.collections[0].colorbar
cbar.ax.tick_params(direction="in", width=.5, labelsize=10)
cbar.set_ticks([-1, -0.5, 0, 0.5, 1])
cbar.set_ticklabels(["-1.00", "-0.50", "0.00", "0.50", "1.00"])
cbar.outline.set_visible(True)
cbar.outline.set_linewidth(.5)
plt.title(title)
plt.show()
#删除不是float的类型
features = data.drop(['Datetime'],axis=1).columns.tolist()
plot_spearmanr(data, features, 'Spearman correlation coefficient heat map between variables', 10, 13)
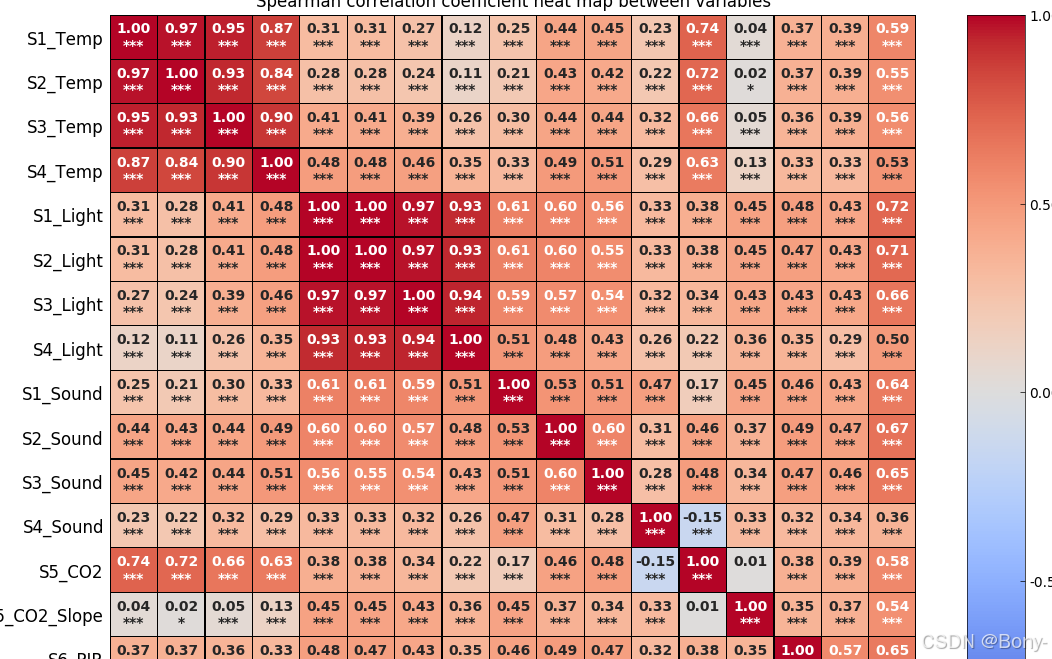
温度 (Temp) 相关性:
S1_Temp, S2_Temp, S3_Temp, S4_Temp 四个传感器的温度数据之间的相关性非常高(大部分在0.80以上),这表明这些特征之间有冗余。因此,可以考虑将它们合成一个新的特征,例如它们的均值或最大值,以减少冗余并保留有用的信息。
特别是S1_Temp和S2_Temp与目标变量(Room_Occupancy_Count)有比较强的正相关(接近0.6),所以温度可以作为一个重要特征保留。
光照强度 (Light):
光照数据(S1_Light, S2_Light, S3_Light, S4_Light)与目标变量的相关性较强(约0.7-0.8),而这些传感器的光照数据之间的相关性也很高。因此,类似温度,我们可以将它们合成一个特征,如光照的平均值或最大值。
声音电压 (Sound):
S1_Sound, S2_Sound, S3_Sound, S4_Sound 的相关性比较弱(大多数都小于0.5),它们与目标变量的相关性也较弱。你可以考虑将声音电压的均值作为一个新特征,但这可能不是最重要的特征,取决于你对声音与占用人数之间的关系是否重视。
二氧化碳浓度 (CO2) 和二氧化碳斜率 (CO2_Slope):
S5_CO2与目标变量的相关性较强(约0.65),且它和S5_C02_Slope的相关性也比较强。这两个特征很可能提供了关于房间占用人数的重要信息,建议保持这两个特征,或将S5_CO2和S5_CO2_Slope的加权平均作为一个新特征。
运动 (PIR):
S6_PIR 和 S7_PIR 的相关性较强(接近0.6),且这两个特征与目标变量有较强的正相关性(接近0.6)。运动检测器与房间占用人数的相关性表明,运动数据应该是非常重要的特征。
# 计算不同传感器的温度均值
data['Temp_Avg'] = data[['S1_Temp', 'S2_Temp', 'S3_Temp', 'S4_Temp']].mean(axis=1)
# 计算不同传感器的光照强度均值
data['Light_Avg'] = data[['S1_Light', 'S2_Light', 'S3_Light', 'S4_Light']].mean(axis=1)
# 计算不同传感器的声音电压均值
data['Sound_Avg'] = data[['S1_Sound', 'S2_Sound', 'S3_Sound', 'S4_Sound']].mean(axis=1)
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix
# 分别训练两个模型,选择效果更好的那个
X = data[['Temp_Avg', 'Light_Avg', 'Sound_Avg', 'S5_CO2', 'S5_CO2_Slope']]
# 用第一个传感器的数据
y1 = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









