




文章目录
电商产品评论数据情感分析
针对用户在电商平台上留下的评论数据,对其进行分词、词性标注和去除停用词等文本预处理。基于预处理后的数据进行情感分析,并使用LDA主题模型提取评论关键信息,以了解用户的需求、意见、购买原因及产品的优缺点等,最终提出改善产品的建议
数据预处理
评论去重
一些电商平台为了避免一些客户长时间不进行评论,往往会设置一道程序,如果用户超过规定的时间仍然没有做出评论,系统就会自动替客户做出评论,这类数据显然没有任何分析价值。由语言的特点可知,在大多数情况下,不同购买者之间的有价值的评论是不会出现完全重复的,如果不同购物者的评论完全重复,那么这些评论一般都是毫无意义的。为了存留更多的有用语料,本节针对完全重复的语料下手,仅删除完全重复部分,以确保保留有用的文本评论信息。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import re
import jieba.posseg as psg
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
path = '/home/kesci/input/emotion_analysi7147'
reviews = pd.read_csv(path+'/reviews.csv')
print(reviews.shape)
reviews.head()

# 删除数据记录中所有列值相同的记录
reviews = reviews[['content','content_type']].drop_duplicates()
content = reviews['content']
reviews.shape
reviews

数据清洗
通过人工观察数据发现,评论中夹杂着许多数字与字母,对于本案例的挖掘目标而言,这类数据本身并没有实质性帮助。另外,由于该评论文本数据主要是围绕京东商城中美的电热水器进行评价的,其中“京东”“京东商城”“美的”“热水器”“电热水器”等词出现的频数很大,但是对分析目标并没有什么作用,因此可以在分词之前将这些词去除,对数据进行清洗
# 去除英文、数字、京东、美的、电热水器等词语
strinfo = re.compile('[0-9a-zA-Z]|京东|美的|电热水器|热水器|')
content = content.apply(lambda x: strinfo.sub('',x))
分词、词性标注、去除停用词
词是文本信息处理的基础环节,是将一个单词序列切分成单个单词的过程。准确地分词可以极大地提高计算机对文本信息的识别和理解能力。相反,不准确的分词将会产生大量的噪声,严重干扰计算机的识别理解能力,并对这些信息的后续处理工作产生较大的影响。中文分词的任务就是把中文的序列切分成有意义的词,即添加合适的词串使得所形成的词串反映句子的本意,中文分词的关键问题为切分歧义的消解和未登录词的识别。
未登录词是指词典中没有登录过的人名、地名、机构名、译名及新词语等。当采用匹配的办法来切分词语时,由于词典中没有登录这些词,会引起自动切分词语的困难。
分词最常用的工作包是jieba分词包,jieba分词是Python写成的一个分词开源库,专门用于中文分词,其有3条基本原理,即实现所采用技术。
- 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)。
- 采用动态规划查找最大概率路径,找出基于词频的最大切分组合。
- 对于未登录词,采用HMM模型,使用了Viterbi算法,将中文词汇按照BEMS 4个状态来标记。
# 分词
worker = lambda s: [(x.word, x.flag) for x in psg.cut(s)] # 自定义简单分词函数
seg_word = content.apply(worker)
seg_word.head()

# 将词语转为数据框形式,一列是词,一列是词语所在的句子ID,最后一列是词语在该句子的位置
n_word = seg_word.apply(lambda x: len(x)) # 每一评论中词的个数
n_content = [[x+1]*y for x,y in zip(list(seg_word.index), list(n_word))]
# 将嵌套的列表展开,作为词所在评论的id
index_content = sum(n_content, [])
seg_word = sum(seg_word, [])
# 词
word = [x[0] for x in seg_word]
# 词性
nature = [x[1] for x in seg_word]
content_type = [[x]*y for x,y in zip(list(reviews['content_type']), list(n_word))]
# 评论类型
content_type = sum(content_type, [])
result = pd.DataFrame({
"index_content":index_content,
"word":word,
"nature":nature,
"content_type":content_type})
result.head()
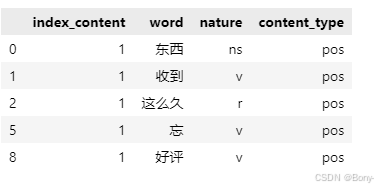
# 构造各词在对应评论的位置列
n_word = list(result.groupby(by = ['index_content'])['index_content'].count())
index_word = [list(np.arange(0, y)) for y in n_word]
# 词语在该评论的位置
index_word = sum(index_word, [])
# 合并评论id
result['index_word'] = index_word
result.head()
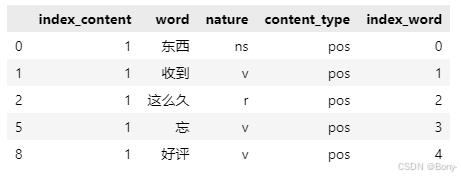
提取含名词的评论
由于本案例的目标是对产品特征的优缺点进行分析,类似“不错,很好的产品”“很不错,继续支持”等评论虽然表达了对产品的情感倾向,但是实际上无法根据这些评论提取出哪些产品特征是用户满意的。评论中只有出现明确的名词,如机构团体及其他专有名词时,才有意义,因此需要对分词后的词语进行词性标注。之后再根据词性将含有名词类的评论提取出来。
# 提取含有名词类的评论,即词性含有“n”的评论
ind = result[['n' in x for x in result['nature']]]['index_content'].unique()
result = result[[x in ind for x in result['index_content']]]
result.head()
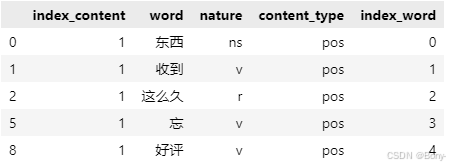
绘制词云
绘制词云查看分词效果,词云会将文本中出现频率较高的“关键词”予以视觉上的突出。首先需要对词语进行词频统计,将词频按照降序排序,选择前100个词,使用wordcloud模块中的WordCloud绘制词云,查看分词效果
import matplotlib.pyplot as plt
from wordcloud import WordCloud
frequencies = result.groupby('word')['word'].count()
frequencies = frequencies.sort_values(ascending = False)
backgroud_Image=plt.imread(path+'/pl.jpg' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









