




我们已经得到了一个使用前七天的数据预测下一天收盘价数据的模型, 由于模型预测精度较高, 这里我们将使用较为简单的量化策略:
- 使用今天加上前六天的开盘与收盘价数据预测下一天的收盘价
- 如果下一天的收盘价高于今天的收盘价, 就买入全部资产90%的股票
- 如果下一天的收盘价低于今天的收盘价, 就卖出全部股票
该方法将于量化中最为常见的金叉死叉策略进行比较
总资产假定为100000元, 手续费为0.03%, 回测框架使用backtrader
一. 数据与模型导入
! pip install -i https://mirrors.aliyun.com/pypi/simple/ backtrader
! pip install -i https://mirrors.aliyun.com/pypi/simple/ EMD-signal

!pip install -i https://mirrors.aliyun.com/pypi/simple/ git+https://github.com/quantopian/pyfolio
#导入各种库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pylab import mpl
from PyEMD import EEMD
import datetime
import backtrader as bt
import pickle
import torch
import torch.nn as nn
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
# 超参数
input_size = 14
hidden_size = 50
num_layers = 2
output_size = 1
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 定义LSTM模型
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
out, _ = self.lstm(x, (h0, c0))
out = self.fc(out[:, -1, :])
return out
# 创建一个空列表,用于存储加载的模型
loaded_models = []
# 加载六个模型
for i in range(1, 7):
model_path = f'lstm_model{i}.pth'
loaded_model = LSTMModel(input_size, hidden_size, num_layers, output_size).to(device)
loaded_model.load_state_dict(torch.load(model_path))
loaded_model.eval()
loaded_models.append(loaded_model)
df = pd.read_csv("/home/mw/input/stock9243/data_00300.csv")
df['date'] = pd.to_datetime(df['date'],format='%Y-%m-%d %H:%M:%S%z')
df['date'] = df['date'].dt.date
df['date'] = pd.to_datetime(df['date'])
df = df.set_index('date')
df = df[['open', 'high', 'low', 'close', 'volume']]
df.index[2917]
二. 金叉死叉策略
最经典的量化策略
- 金叉:短期均线上穿长期均线, 这时买入总资产90%的股票
- 死叉:短期均线下穿长期均线, 这时卖出所有股票
此处短期均线为5日均线, 长期均线为20均线
class SMA(bt.Strategy):
def log(self, txt, dt=None):
'''此策略的日志记录功能'''
dt = dt or self.datas[0].datetime.date(0)
print('%s, %s' % (dt.isoformat(), txt))
def __init__(self):
self.dataclose = self.datas[0].close
self.order = None
self.buyprice = None
self.buycomm = None
self.sma_short = bt.indicators.SimpleMovingAverage(self.data0, period=5) # 短期均线
self.sma_long = bt.indicators.SimpleMovingAverage(self.data0, period=20) # 长期均线
def notify_order(self, order):
if order.status in [order.Submitted, order.Accepted]:
# 做多/做空 订单 已提交/已执行 到/被代理 - 无事可做
return
# 检查订单是否已经完成
# 注意:如果没有足够资金,代理可能拒绝订单
if order.status in [order.Completed]:
if order.isbuy():
self.log(
'BUY EXECUTED, Price: %.2f, Cost: %.2f, Comm %.2f' %
(order.executed.price,
order.executed.value,
order.executed.comm))
self.buyprice = order.executed.price
self.buycomm = order.executed.comm
else: # 做空
self.log('SELL EXECUTED, Price: %.2f, Cost: %.2f, Comm %.2f' %
(order.executed.price,
order.executed.value,
order.executed.comm))
self.bar_executed = len(self)
elif order.status in [order.Canceled, order.Margin, order.Rejected]:
self.log('Order Canceled/Margin/Rejected')
self.order = None
def notify_trade(self, trade):
if not trade.isclosed:
return
self.log('OPERATION PROFIT, GROSS %.2f, NET %.2f' %
(trade.pnl, trade.pnlcomm))
def next(self):
if self.order:
return
if not self.position:
# 金叉:短期均线上穿长期均线
if self.sma_short[0] > self.sma_long[0] and self.sma_short[-1] < self.sma_long[-1]:
self.log('BUY CREATE, %.2f' % self.dataclose[0])
self.buy()
else:
# 死叉:短期均线下穿长期均线
if self.sma_short[0] < self.sma_long[0] and self.sma_short[-1] > self.sma_long[-1]:
self.log('SELL CREATE, %.2f' % self.dataclose[0])
self.sell()
if __name__ == '__main__':
cerebro = bt.Cerebro()
data = bt.feeds.PandasData(dataname = df,
fromdate = df.index[2917],
todate = df.index[-1],
timeframe=bt.TimeFrame.Days)
cerebro.adddata(data)
# cerebro.adddata(data_pingan)
cerebro.addstrategy(SMA)
cerebro.addanalyzer(bt.analyzers.SharpeRatio, _name = 'SharpeRatio')
cerebro.addanalyzer(bt.analyzers.DrawDown, _name = 'DrawDown')
cerebro.broker.setcash(100000.0)
cerebro.broker.setcommission(commission = 0.0003)
cerebro.addsizer(bt.sizers.PercentSizer, percents=90)
cerebro.addanalyzer(bt.analyzers.PyFolio, _name='pyfolio')
# 打印起始条件
print('Starting Portfolio Value: %.2f' % cerebro.broker.getvalue())
result = cerebro.run()
# 打印最终结果
print('Final Portfolio Value: %.2f' % cerebro.broker.getvalue())

# 获取分析器结果
sharpe_ratio = result[0].analyzers.SharpeRatio.get_analysis()
max_drawdown = result[0].analyzers.DrawDown.get_analysis()
# 打印夏普比率、最大回撤
print('Sharpe Ratio:', sharpe_ratio['sharperatio'])
print('Max Drawdown:', max_drawdown['max']['drawdown'])

# 计算总收益率
total_return = cerebro.broker.getvalue() / cerebro.broker.startingcash - 1
# 计算交易天数
start_date = df.index[2917]
end_date = df.index[-1]
trading_days = (end_date - start_date).days
# 计算年化收益率
annual_return = (1 + total_return) ** (365.0 / trading_days) - 1
print("Total Return:", total_return)
print("Annualized Return:", annual_return)

import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
strat = result[0]
pyfoliozer = strat.analyzers.getbyname('pyfolio')
returns, positions, transactions, gross_lev = pyfoliozer.get_pf_items()
import pyfolio as pf
pf.create_full_tear_sheet(
returns,
positions=positions,
transactions=transactions,
live_start_date='2022-01-05')
cerebro.plot(iplot=False)
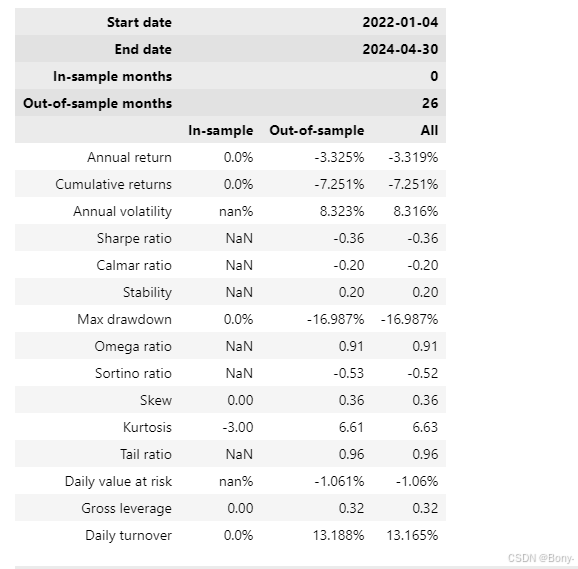
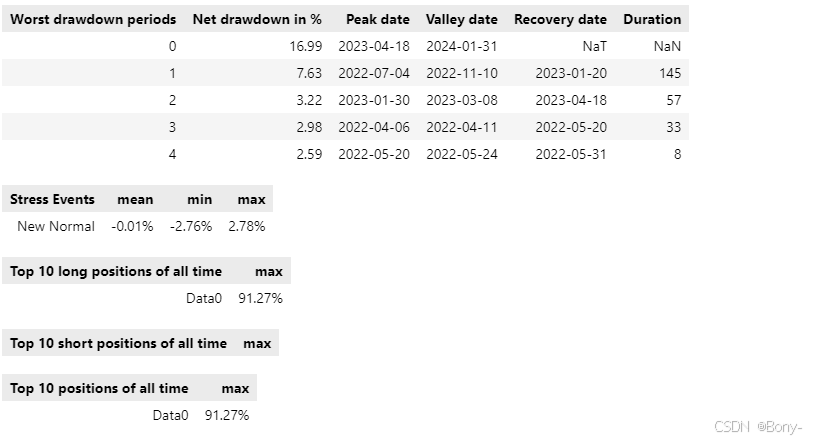
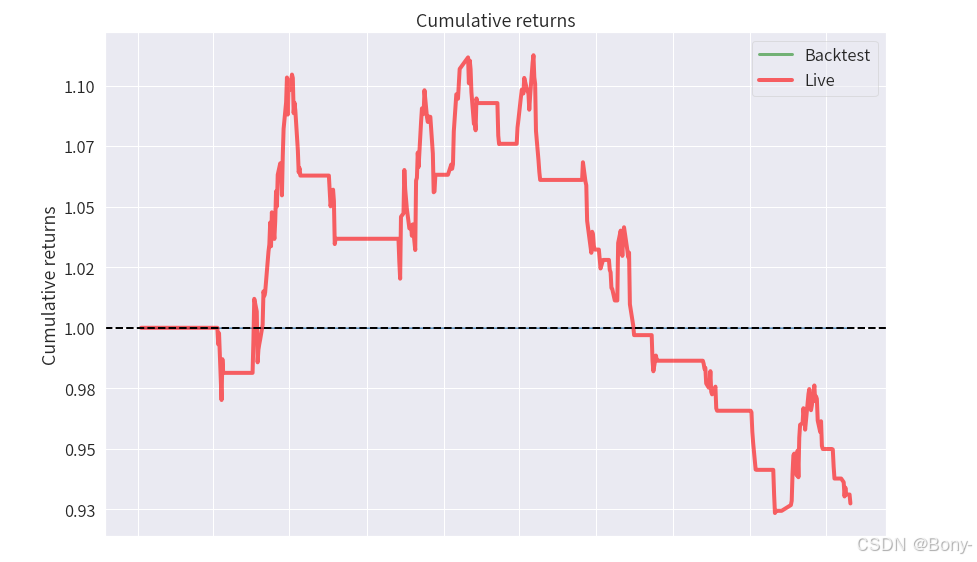
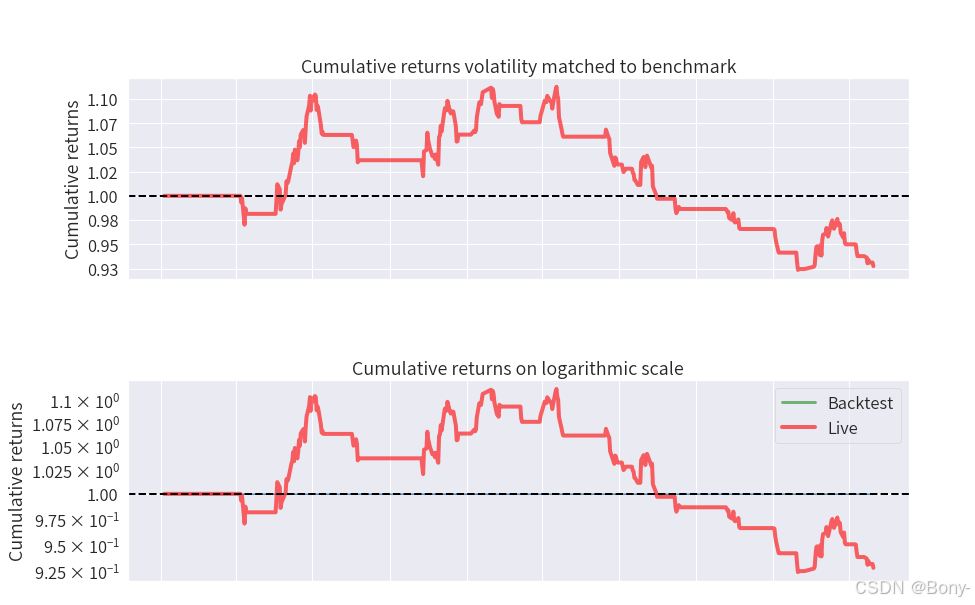
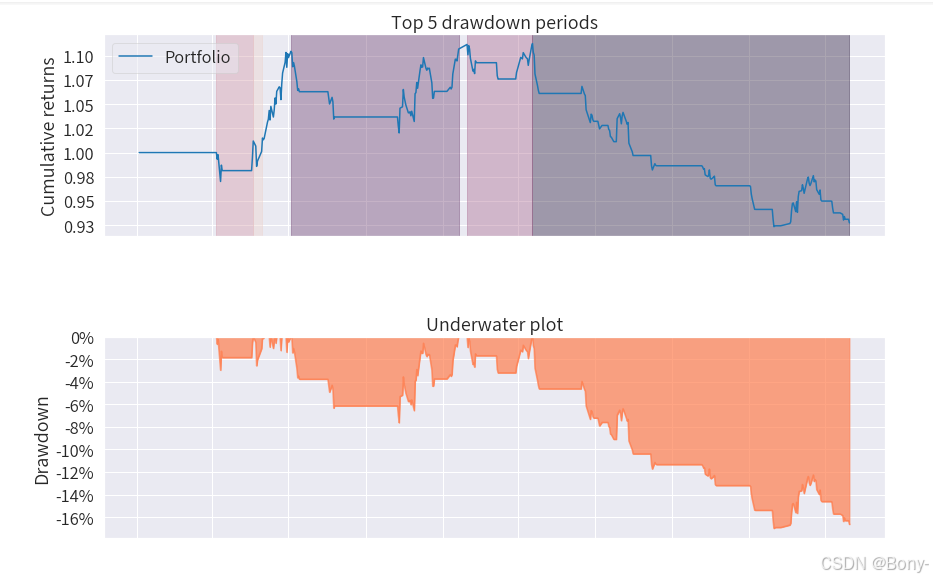
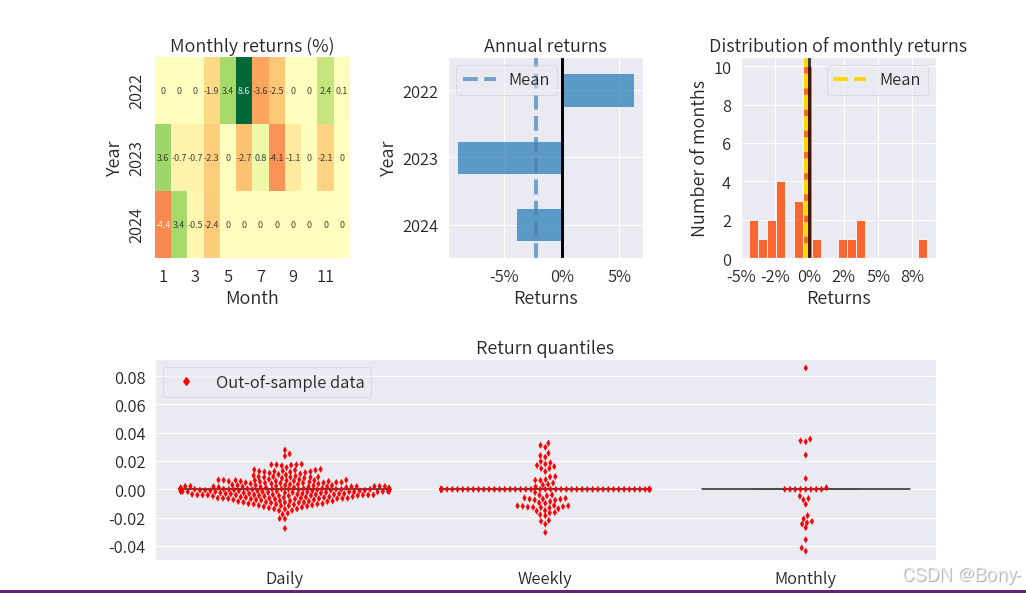
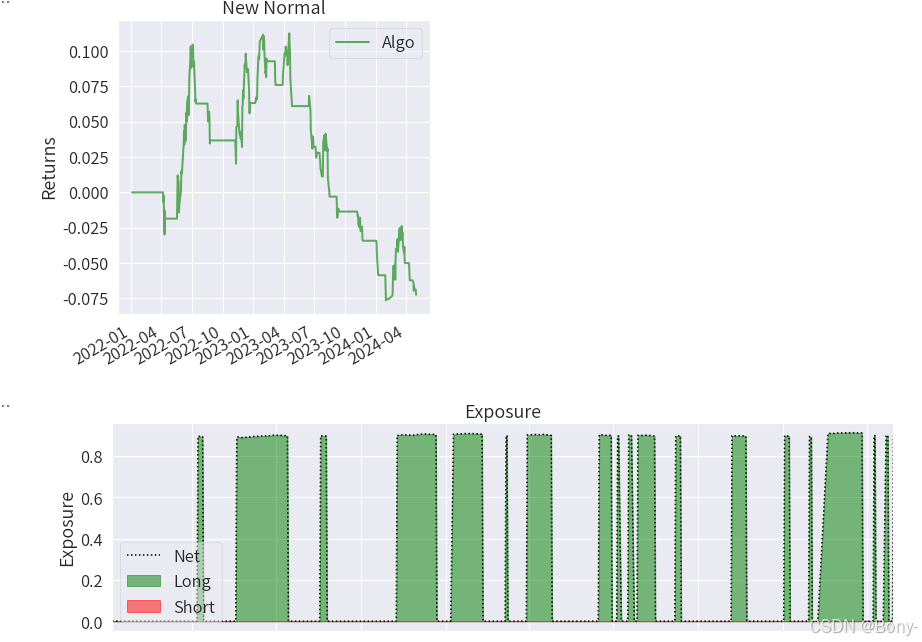
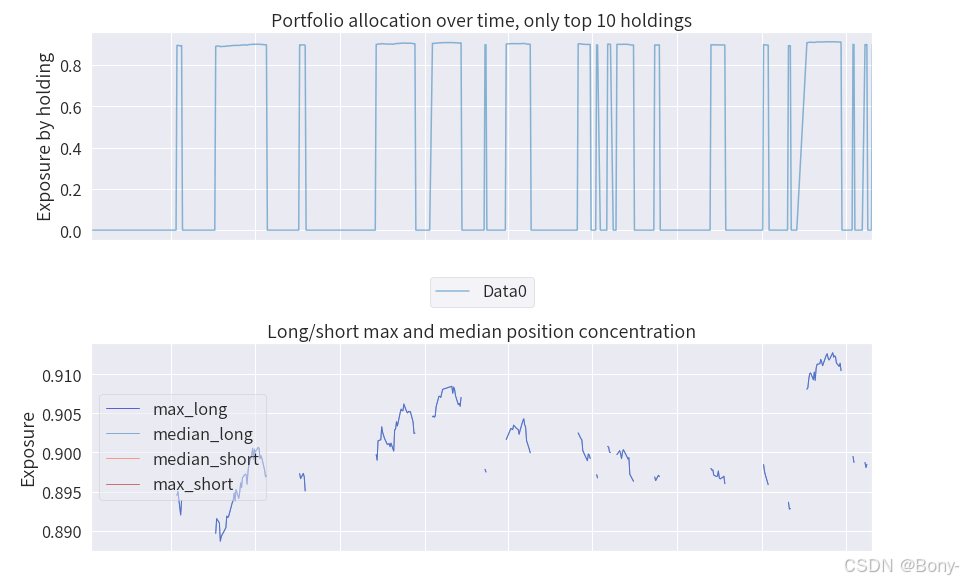
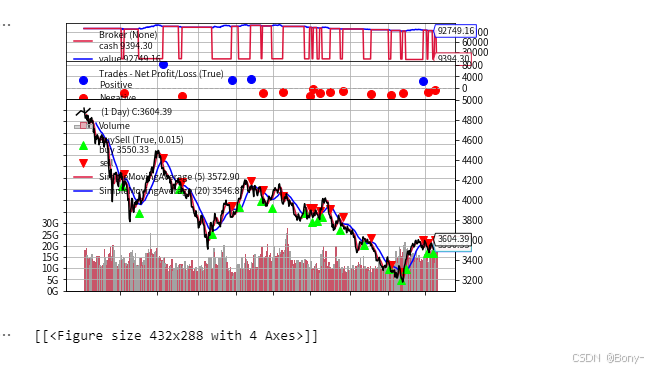
金叉死叉策略的表现结果很差,夏普比率为-0.508, 最大回撤为16.98, 回撤还可以, 总收益率-7.25%, 年化收益率-3.19%
100000元的本金经过两年的买卖变为92749.16, 净亏7250.83
从图中也可以看出红点多于蓝点, 意味着大多是亏钱的交易, 胜率很低
由于2022年至2024年沪深300整体下跌, 金叉死叉策略失效也能理解
三. EEMD-LSTM策略
# 初始化 EEMD 对象
eemd = EEMD()
# 执行 EEMD 分解
eIMFs_open = eemd.eemd(df['open'].values, max_imf=5)
eIMFs_close = eemd.eemd(df['close'].values, max_imf=5)
class SMA(bt.Strategy):
def log(self, txt, dt=None):
'''此策略的日志记录功能'''
dt = dt or self.datas[0].datetime.date(0)
print('%s, %s' % (dt.isoformat(), txt))
def __init__(self):
self.dataclose = self.datas[0].close
self.dataopen = self.datas[0].open
self.prediction_data = [] # 存储前七天的开盘价和收盘价数据
self.totaldata = df[['open','close']][:2917]
self.order = None
self.buyprice = None
self.buycomm = None
def notify_order(self, order):
if order.status in [order.Submitted, order.Accepted]:
# 做多/做空 订单 已提交/已执行 到/被代理 - 无事可做
return
# 检查订单是否已经完成
# 注意:如果没有足够资金,代理可能拒绝订单
if order.status in [order.Completed]:
if order.isbuy():
self.log(
'BUY EXECUTED, Price: %.2f, Cost: %.2f, Comm %.2f' %
(order.executed.price,
order.executed.value,
order.executed.comm))
self.buyprice = order.executed.price
self.buycomm = order.executed.comm
else: # 做空
self.log('SELL EXECUTED, Price: %.2f, Cost: %.2f, Comm %.2f' %
(order.executed.price,
order.executed.value,
order.executed.comm))
self.bar_executed = len(self)
elif order.status in [order.Canceled, order.Margin, order.Rejected]:
self.log('Order Canceled/Margin/Rejected')
self.order = None
def notify_trade(self, trade):
if not trade.isclosed:
return
self.log('OPERATION PROFIT, GROSS %.2f, NET %.2f' %
(trade.pnl, trade.pnlcomm))
def next(self):
new_data={
'open': self.dataopen[0],
'close': self.dataclose[0],
}
new_row = pd.DataFrame(new_data, index=[0]) # 将字典转换为 DataFrame,并设置索引
self.totaldata = pd.concat([self.totaldata, new_row], ignore_index=True)
if len(self.prediction_data) < 7:
# 如果数据不足七天,则继续收集数据
self.prediction_data.append((self.dataopen[0], self.dataclose[0]))
return
if self.order:
return
lstm_re = []
for i in range(6):
window_size = 7 # 滞后阶数为7天
n_steps = 1 # 每次预测1个时间步
df_ = pd.DataFrame(np.concatenate([eIMFs_close[i].reshape(-1, 1), eIMFs_open[i].reshape(-1, 1)], axis=1), columns=['close', 'open'])
# 生成窗口数据
windowed_data = [df_.iloc[i - window_size:i, [0, 1]].values.flatten() for i in range(window_size, len(df_))]
new_df = pd.DataFrame(windowed_data, columns=[f'x{i}' for i in range(1, 2 * window_size + 1)])
new_df['target'] = df_.iloc[window_size:, 0].values
# 创建特征矩阵X和目标变量y
X = np.array([new_df.iloc[i:i + n_steps, :-1].values for i in range(len(new_df) - n_steps + 1)])
y = new_df['target']
# 数据标准化
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_reshaped = X.reshape(X.shape[0] * X.shape[1], X.shape[2])
X_scaled = scaler_X.fit_transform(X_reshaped)
X_scaled_reshaped = X_scaled.reshape(X.shape[0], X.shape[1], X.shape[2])
y_scaled = scaler_y.fit_transform(y.values.reshape(-1, 1))
pre_x = X_scaled_reshaped[len(self.totaldata)-window_size:len(self.totaldata)-window_size+1]
with torch.no_grad():
y_pred = loaded_models[i](torch.tensor(pre_x, dtype=torch.float32).to(device)).cpu().numpy().flatten()
# 最后一个由于没有数据直接return
if y_pred.size > 0:
y_pred = scaler_y.inverse_transform(y_pred.reshape(-1, 1)).flatten()
else:
return
lstm_re.append(y_pred)
# 将六个模型的预测结果求和得下一天的收盘价预测值
next_close_prediction = sum(lstm_re)
if not self.position:
# 如果下一天的收盘价预测值大于今天的收盘价: 买
if next_close_prediction > self.dataclose[0]:
self.log('BUY CREATE, %.2f' % self.dataclose[0])
self.buy()
else:
# 如果下一天的收盘价预测值小于今天的收盘价: 卖
if next_close_prediction < self.dataclose[0]:
self.log('SELL CREATE, %.2f' % self.dataclose[0])
self.sell()
# 由于每天都要使用六个模型进行预测, 运行时间可能较慢, 大概需要30-40mins
if __name__ == '__main__':
cerebro = bt.Cerebro()
data = bt.feeds.PandasData(dataname = df,
fromdate = df.index[2917],
todate = df.index[-1],
timeframe=bt.TimeFrame.Days)
cerebro.adddata(data)
cerebro.addstrategy(SMA)
cerebro.addanalyzer(bt.analyzers.SharpeRatio, _name = 'SharpeRatio')
cerebro.addanalyzer(bt.analyzers.DrawDown, _name = 'DrawDown')
cerebro.broker.setcash(100000.0)
cerebro.broker.setcommission(commission = 0.0003)
cerebro.addanalyzer(bt.analyzers.PyFolio, _name='pyfolio')
cerebro.addsizer(bt.sizers.PercentSizer, percents=90)
# 打印起始条件
print('Starting Portfolio Value: %.2f' % cerebro.broker.getvalue())
result = cerebro.run()
# 打印最终结果
print('Final Portfolio Value: %.2f' % cerebro.broker.getvalue())
# 保存 cerebro 对象和结果
with open('EEMD_LSTM策略.pkl', 'wb') as f:
pickle.dump((cerebro, result), f)
print('Cerebro and result saved successfully.')

# 获取分析器结果
sharpe_ratio = result[0].analyzers.SharpeRatio.get_analysis()
max_drawdown = result[0].analyzers.DrawDown.get_analysis()
# 打印夏普比率、最大回撤
print('Sharpe Ratio:', sharpe_ratio['sharperatio'])
print('Max Drawdown:', max_drawdown['max']['drawdown'])

# 计算总收益率
total_return = cerebro.broker.getvalue() / cerebro.broker.startingcash - 1
# 计算交易天数
start_date = df.index[2917]
end_date = df.index[-1]
trading_days = (end_date - start_date).days
# 计算年化收益率
annual_return = (1 + total_return) ** (365.0 / trading_days) - 1
print("Total Return:", total_return)
print("Annualized Return:", annual_return)

import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
strat = result[0]
pyfoliozer = strat.analyzers.getbyname('pyfolio')
returns, positions, transactions, gross_lev = pyfoliozer.get_pf_items()
import pyfolio as pf
pf.create_full_tear_sheet(
returns,
positions=positions,
transactions=transactions,
live_start_date='2022-01-05')
cerebro.plot(iplot=False)
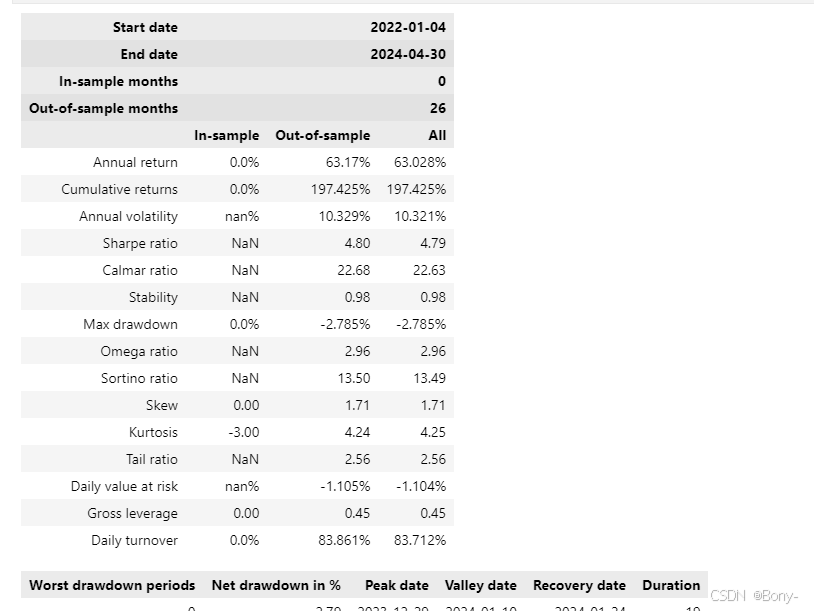
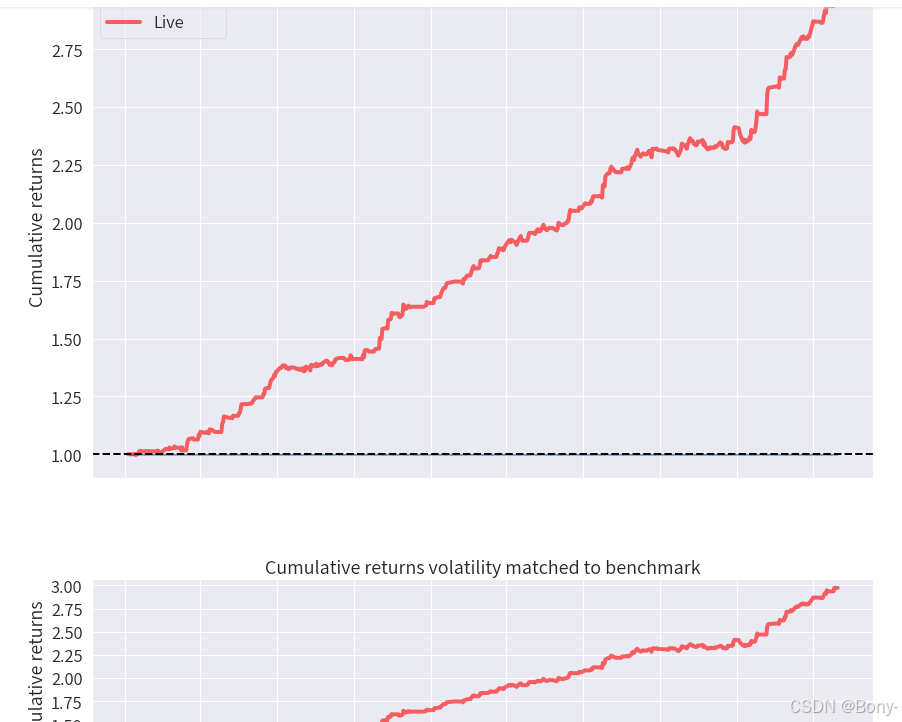
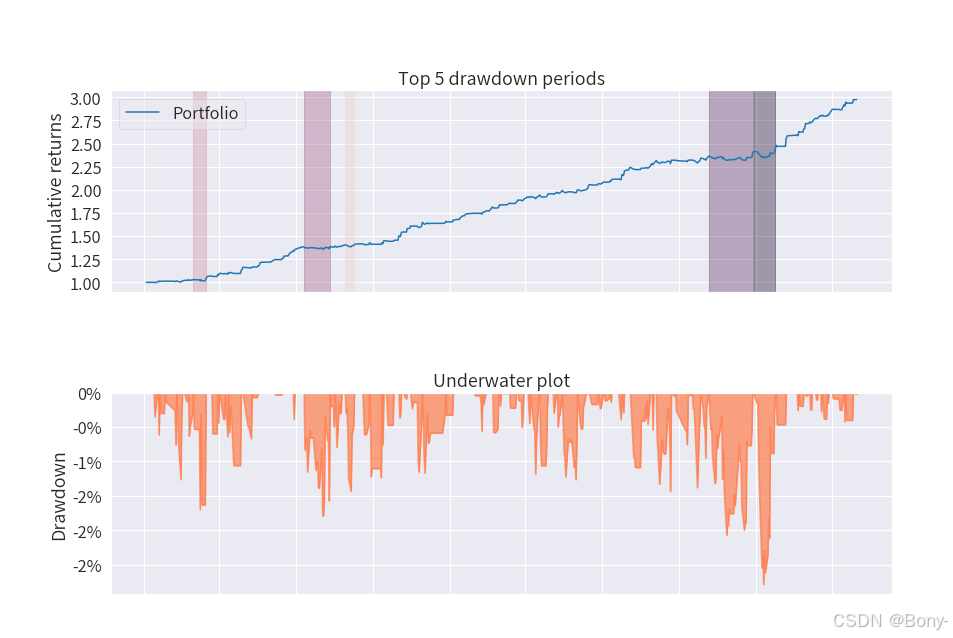
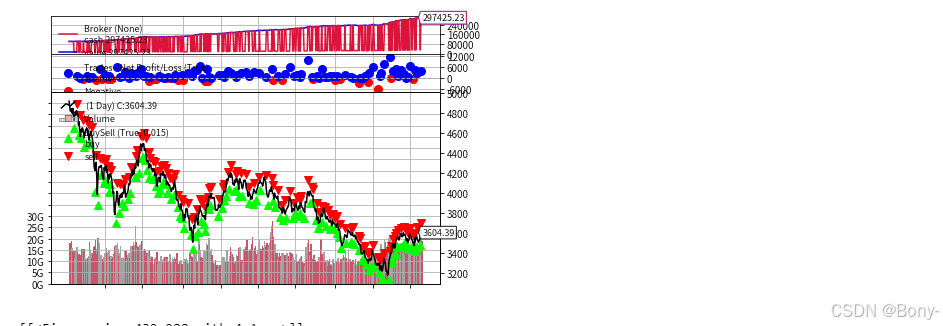
EEMD-LSTM策略的表现姣好, 夏普比率2.54, 最大回撤2.75, 总收益率194%, 年化收益率59%
本金由100000元经过两年交易变为 297425.23
相比之下金叉死叉策略甚至做不到稳定盈利
此外, 由于该策略买卖的唯一条件就是下一天预测的收盘价与当天收盘价的对比, 所有该策略会较为频繁的交易, 以求获得更多的超额利润
图中也可以看出觉大多是都是蓝色点, 代表是成功的交易, 胜率很高
PS: 由于LSTM模型的神经元权重具有随机性, 每一次运行的结果会在一个合理范围内波动
if __name__ == '__main__':
# 加载 cerebro 对象和结果
with open('EEMD_LSTM策略.pkl', 'rb') as f:
cerebro, result = pickle.load(f)
# 可以继续使用这些对象
print('Cerebro and result loaded successfully.')

















 813
813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









