




上一篇:详解Xilinx AXI Traffic Generator IP核:AXI4总线性能验证利器
1 引言
在复杂的FPGA系统设计中,AXI总线的性能直接影响整个系统的效率。Xilinx提供的AXI Performance Monitor (APM) IP核正是专门用于测量和分析AXI系统性能的强大工具。
2 APM核心架构与功能
APM IP核通过AXI-Lite接口进行配置,能够精确测量AXI系统的关键性能指标:
核心特性:
-
支持最多8个监视器插槽,可配置为AXI4内存映射或AXI4-Stream
-
测量总线延迟、内存流量、吞吐率等关键指标
-
支持8个外部事件计数,每个都有独立的启动/停止信号
-
必须连接到设计中的最快时钟(core_aclk)
两大核心模块:
-
事件日志模块:记录特定事件,帮助重建事务以分析系统行为
-
事件计数模块:提供硬件计数器,统计与AXI事务相关的事件
3 事件计数机制深度解析
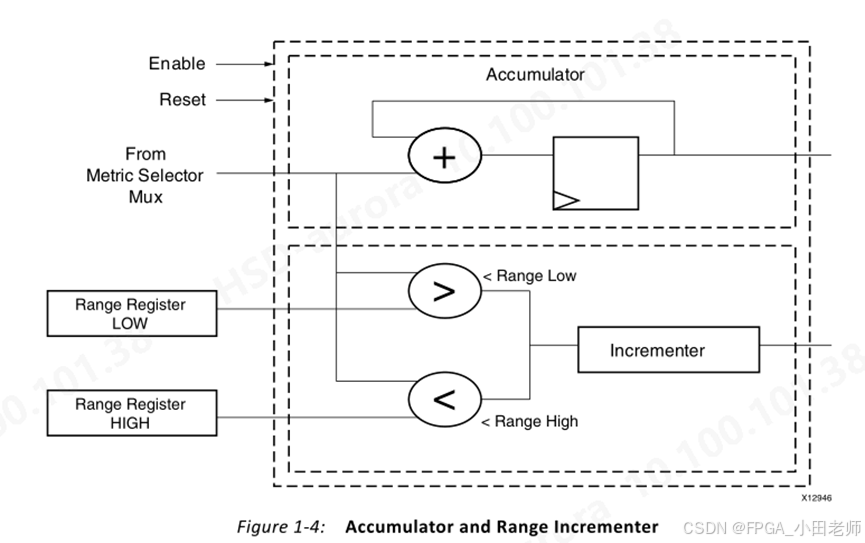
APM的事件计数模块由可配置的累加器和递增器组成(最多10个),其架构如下:
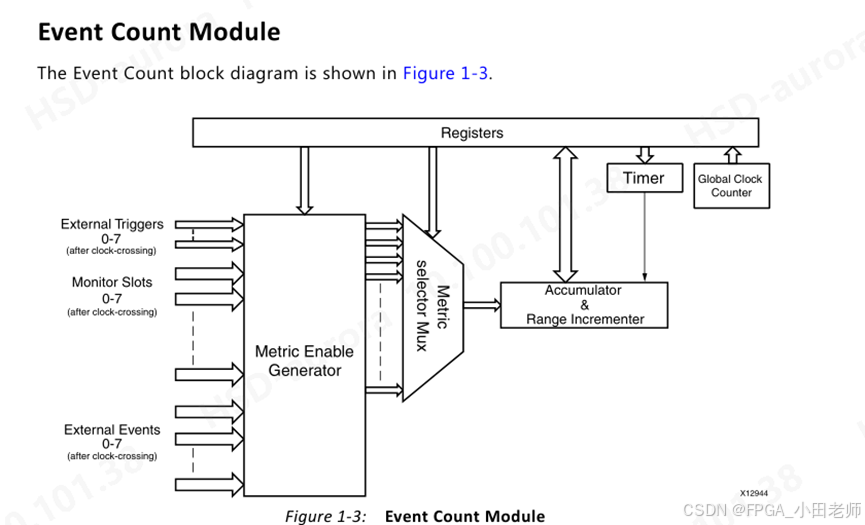
关键组件:
-
累加器:提供事件的聚合统计值
-
Range Incrementer:将事件计数与范围寄存器比较,用于统计特定范围内的延迟
-
计时器:在预设时间间隔内对计数器值进行采样
4 实战演示:四核联动仿真框架
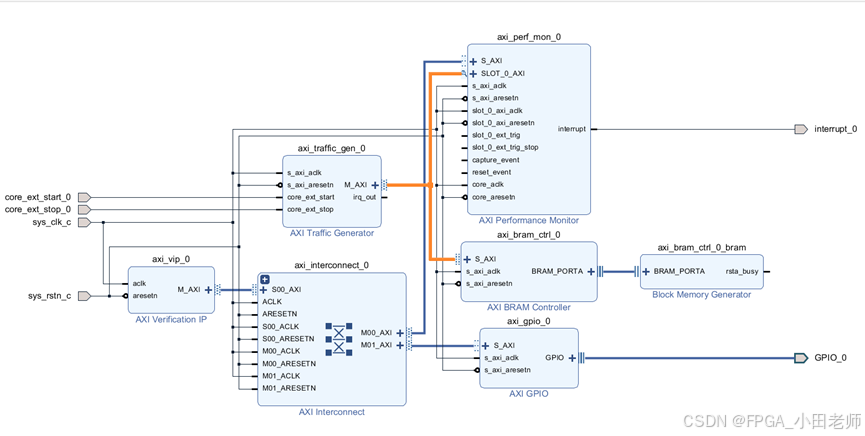
为了深入理解APM的应用,我们搭建了一个完整的仿真系统:完整工程在这里AXI总线性能分析实战工程:ATG+APM+BRAM联合仿真源码资源-优快云下载
4.1 系统架构
-
AXI Traffic Generator:产生持续的AXI4写数据流
-
APM:监控总线行为,统计性能指标
-
AXI BRAM:作为目标存储设备
-
AXI VIP:配置ATG和APM的工作模式
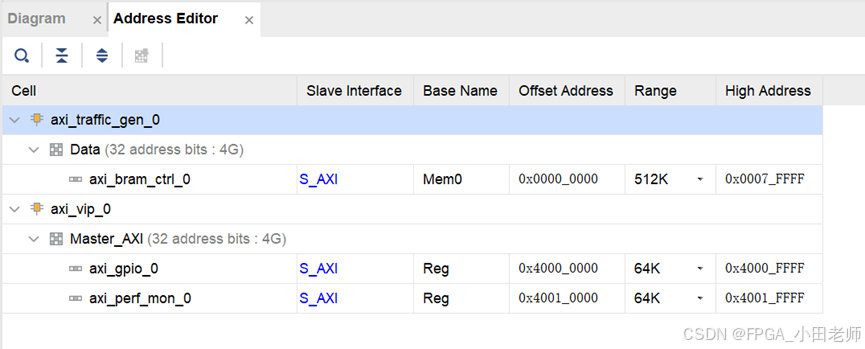
4.2 地址空间分配
-
0x4000_0000:AXI GPIO(控制ATG启停) -
0x4001_0000:APM寄存器配置 -
0x0000_0000:AXI BRAM存储空间
5 APM配置与数据采集流程
第一步:初始化配置
mst_agent.AXI4_WRITE_BURST(0,32'h4001_0300,0,mtestDataSize,mtestBurstType,mtestLOCK,3,0,0,0,'h0,32'h0002_0002,0,mtestBresp);
mst_agent.AXI4_WRITE_BURST(0,32'h4001_0300,0,mtestDataSize,mtestBurstType,mtestLOCK,3,0,0,0,'h0,32'h0000_0051,0,mtestBresp);
mst_agent.AXI4_WRITE_BURST(0,32'h4000_0000,0,mtestDataSize,mtestBurstType,mtestLOCK,3,0,0,0,'h0,32'h0000_0001,0,mtestBresp);给0x4001_0300寄存器写0x0002_0002,即复位APM里面的所有计数器,复位全局时钟计数器
给0x4001_0300寄存器写0x0000_0051,即使能APM的所有计数器,使用外部trigger作为计数器开始信号
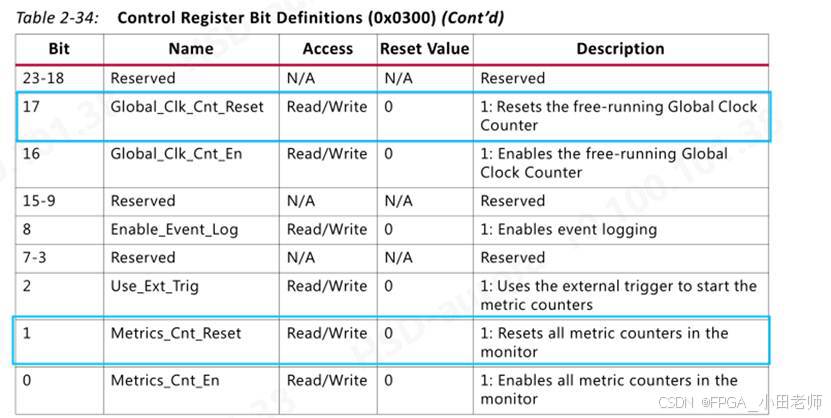
之后给0x4000_0000写1,即配置ATG开始传输数据。
第二步:中断配置
mst_agent.AXI4_WRITE_BURST(0,32'h4001_0030,0,mtestDataSize,mtestBurstType,mtestLOCK,3,0,0,0,'h0,32'h0000_0001,0,mtestBresp);
mst_agent.AXI4_WRITE_BURST(0,32'h4001_0034,0,mtestDataSize,mtestBurstType,mtestLOCK,3,0,0,0,'h0,32'h0000_0002,0,mtestBresp);
mst_agent.AXI4_WRITE_BURST(0,32'h4001_0024,0,mtestDataSize,mtestBurstType,mtestLOCK,3,0,0,0,'h0,32'h0000_1000,0,mtestBresp);
mst_agent.AXI4_WRITE_BURST(0,32'h4001_0028,0,mtestDataSize,mtestBurstType,mtestLOCK,3,0,0,0,'h0,32'h0000_0002,0,mtestBresp);
mst_agent.AXI4_WRITE_BURST(0,32'h4001_0028,0,mtestDataSize,mtestBurstType,mtestLOCK,3,0,0,0,'h0,32'h0000_0001,0,mtestBresp);给0x4001_0030寄存器写0x0000_0001,使能全局中断;

给0x4001_0034寄存器写0x0000_0002,使能采样间隔计数器溢出中断;
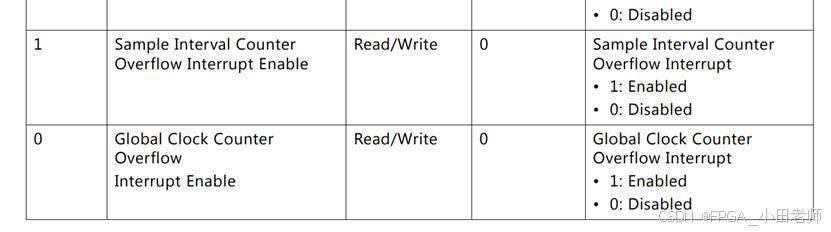
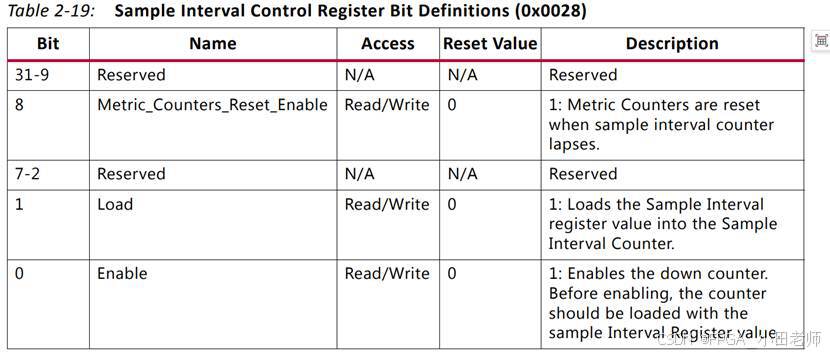
给0x0x4001_0024寄存器写0x0000_1000,即采样间隔,设置为4096个clk进行一次统计。

给0x0x4001_0028寄存器写0x0000_0002,再写0x0000_0001,即将刚才设置的采样间隔导入计数器里面,然后开始向下计数。
第三步:性能数据统计
APM提供丰富的性能统计寄存器:
- 0x0x4001_0210:写事务计数
- 0x0x4001_0240:读事务计数
- 0x0x4001_0200:写byte计数
- 0x0x4001_0230:读byte计数
- 0x0x4001_0220:写的总延迟
- 0x0x4001_0250:读的总延迟
- 0x0x4001_0254:高16bit—写最大延迟 低16bit—写的最小延迟
- 0x0x4001_0258:高16bit—读最大延迟 低16bit—读的最小延迟
task WriteReadCounter ();
// mst_agent.AXI4_READ_BURST (0,32'h4001_002c,0,mtestDataSize,mtestBurstType,mtestLOCK,3,0,0,0,0,mtestRData,mtestRresp,mtestRUSER);
mst_agent.AXI4_READ_BURST (0,32'h4001_0210,0,mtestDataSize,mtestBurstType,mtestLOCK,3,0,0,0,0,mtestRData,mtestRresp,mtestRUSER);
$display("0x210 write trans count = %d decimal",mtestRData[31:0]);
mst_agent.AXI4_READ_BURST (0,32'h4001_0240,0,mtestDataSize,mtestBurstType,mtestLOCK,3,0,0,0,0,mtestRData,mtestRresp,mtestRUSER);
$display("0x240 read trans count = %d decimal",mtestRData[31:0]);
mst_agent.AXI4_READ_BURST (0,32'h4001_0200,0,mtestDataSize,mtestBurstType,mtestLOCK,3,0,0,0,0,mtestRData,mtestRresp,mtestRUSER);
write_byte_count[31:0] = mtestRData[31:0];
$display("0x200 write byte count = %d decimal",mtestRData[31:0]);
mst_agent.AXI4_READ_BURST (0,32'h4001_0230,0,mtestDataSize,mtestBurstType,mtestLOCK,3,0,0,0,0,mtestRData,mtestRresp,mtestRUSER);
read_byte_count[31:0] = mtestRData[31:0];
$display("0x230 read byte count = %d decimal",mtestRData[31:0]);
mst_agent.AXI4_READ_BURST (0,32'h4001_0220,0,mtestDataSize,mtestBurstType,mtestLOCK,3,0,0,0,0,mtestRData,mtestRresp,mtestRUSER);
$display("0x220 write total latency = %d decimal",mtestRData[31:0]);
mst_agent.AXI4_READ_BURST (0,32'h4001_0250,0,mtestDataSize,mtestBurstType,mtestLOCK,3,0,0,0,0,mtestRData,mtestRresp,mtestRUSER);
$display("0x250 read total latency = %d decimal",mtestRData[31:0]);
mst_agent.AXI4_READ_BURST (0,32'h4001_0254,0,mtestDataSize,mtestBurstType,mtestLOCK,3,0,0,0,0,mtestRData,mtestRresp,mtestRUSER);
$display("0x254 write minimum latency = %d decimal",mtestRData[15:0]);
$display("0x254 write maximum latency = %d decimal",mtestRData[31:16]);
mst_agent.AXI4_READ_BURST (0,32'h4001_0258,0,mtestDataSize,mtestBurstType,mtestLOCK,3,0,0,0,0,mtestRData,mtestRresp,mtestRUSER);
$display("0x258 read minimum latency = %d decimal",mtestRData[15:0]);
$display("0x258 read maximum latency = %d decimal",mtestRData[31:16]);
// $display("write throughput Rate (MB/s) = %.4f ",(write_byte_count*100)/4096);
endtask6 性能指标计算与结果分析
6.1 实测结果展示
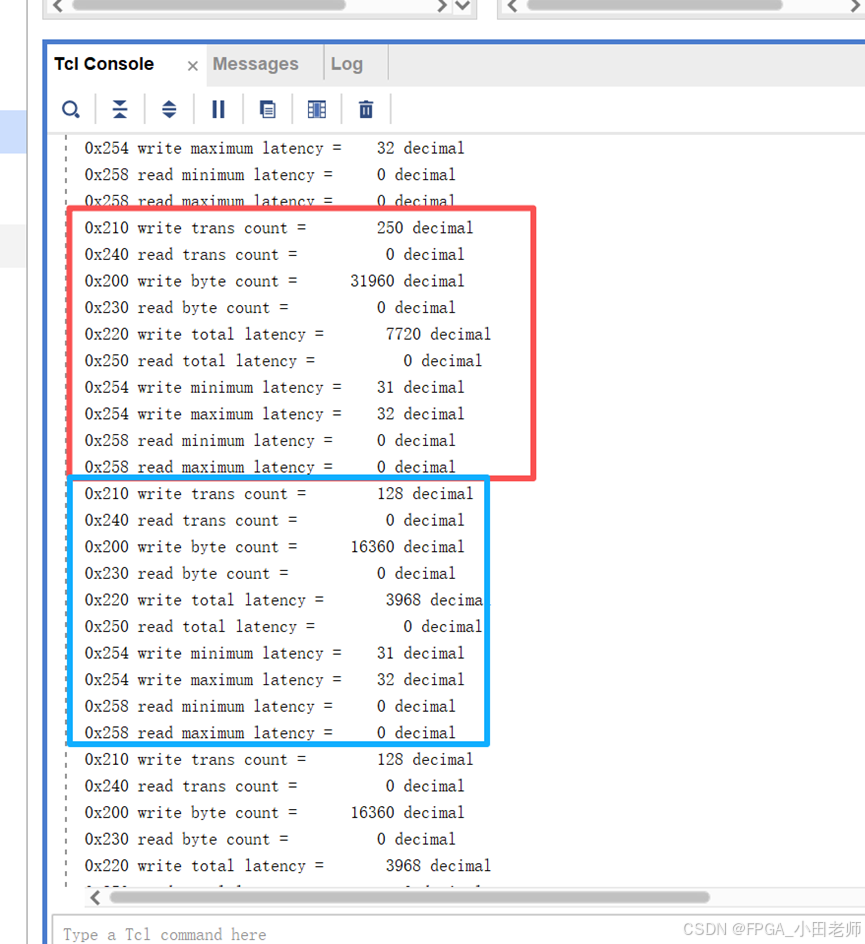
在40960ns采样周期内统计到:
-
写事务:250次
-
写数据量:31960字节
-
总延迟:7720个时钟周期
-
最小延迟:31周期,最大延迟:32周期
6.2 统计方式和延迟分析
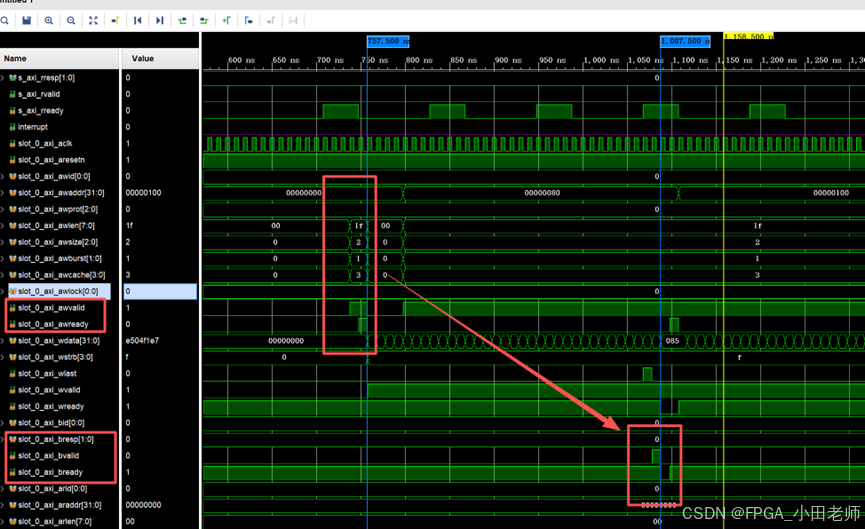
如下图所示,我们以写事务为例,我们每完成一次写事务,即每收到一次写Resp信号,我们认为完成了一次写事务,写事务计数器(0x0210寄存器)就会+1;
APM精确测量从发起请求到收到应答的完整延迟。如图中所示,在757.5ns发起写请求,1087.5ns收到应答,延迟为330ns(33个时钟周期)。
6.3 吞吐率计算
比如我们时钟100MHz对应10ns,采样间隔4096(寄存器0x0024的值)即每4096*10ns统计一次,这一段时间写传输的数据量是n个byte(寄存器0x200的值),则写的吞吐率为 n/(4096*10ns),其常用的单位是B/s,即每秒传输多少个byte。
本次写传输的吞吐率为31960B/40960ns.
7 应用场景与价值
APM IP核在以下场景中发挥重要作用:
-
系统性能分析:识别AXI总线瓶颈
-
架构优化验证:对比不同系统架构的性能差异
-
实时监控:在生产环境中持续监控系统健康度
-
调试辅助:快速定位性能异常的根本原因
8 总结
AXI Performance Monitor IP核为FPGA开发者提供了强大的AXI总线性能分析能力。通过精确的事件计数、灵活的配置选项和丰富的数据统计,APM能够全面揭示系统的性能特征,为优化设计提供数据支撑。
掌握APM的使用,不仅能够提升系统调试效率,更能深入理解AXI总线的工作机制,从而设计出更高性能的FPGA系统。结合AXI Traffic Generator等IP核,可以构建完整的性能测试与验证环境,显著提升开发质量。
下一篇
介绍完了AXI_Traffic_generate ip核 和 AXI_Perfomence_Monitor ip核,我们下一篇,就介绍如何使用这两个IP对DDR3进行性能评估,敬请期待!


















 2015
2015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











