



前言
“灵巧手”(dexterous hand)通常指具有类人手结构、多自由度的末端执行器,能够进行精细的抓取与操作,而不仅仅局限于平行夹紧(如下图)。它们模仿人类手指关节和肌腱驱动,使机器人能够执行转动、重定位、穿插等复杂操作。根据结构和材料不同,灵巧手大致可分为刚性型、柔性型和混合型:刚性型采用金属或坚硬塑料结构,关节通过电机或舵机驱动,优点是定位精度高、力矩大;柔性型主要用硅胶、橡胶等软材料,可通过气动驱动或形变实现自适应抓取,天生适合对柔软或不规则物体的抓取;混合型结合刚柔两者,例如刚性骨架包裹柔性层,兼顾承力和安全性。近年来,随着增材制造和传感技术进步,灵巧手的设计趋势是结构更轻便、可拓展(如3D打印一体化设计)且集成丰富传感器,使其在保持精细操作能力的同时降低成本和复杂度。总体来看,从并联双爪等简单夹具到今天的多指柔刚结合的灵巧手,已经形成多条发展脉络,各种创新不断涌现。
在机器人学中,“灵巧手”是把感知—决策—执行闭环落实到接触尺度的关键枢纽,其重要性体现在方法论与系统层两个层面:在方法论上,灵巧手将原本“抓取—位移”的低维任务,提升为包含滚动、指间重排、推挤与非抓取(non-prehensile)操作在内的操作原语集合,使机器人需正面处理接触—摩擦驱动的混合动力学、互补约束与部分可观测性(POMDP),由此推动触觉融合(tactile fusion)、接触状态估计、阻抗/顺应控制、模型—学习混合(model-based × RL/IL)与触觉伺服等核心技术的演进;在系统层面,灵巧手以高自由度与顺应性结构、密集触觉传感为载体,显著扩展同一硬件在开放世界中的任务覆盖率,减少对治具与专用末端执行器的依赖,提升通用机器人在装配、检修、服务与医疗辅具等高价值场景下的经济性与安全性。更进一步,灵巧手是“通用机器人”与“具身智能”落地的瓶颈环节:只有在手内操控(in-hand manipulation)与工具使用被可靠学习与泛化之后,语言/视觉等高层规划才能通过细粒度接触行动被兑现。因此,灵巧手既是推进机器人能力边界的技术抓手,也是将抽象智能转化为可复用、可规模化物理能力的基础设施。
为此,本文主要围绕近期在顶会(RSS,CoRL,ICRA,IROS)发表的“灵巧手”相关主题的论文,进行了简单介绍和分析,按照“一句一图”的模式展开(一句:什么问题,怎么解决;一图:文章最体现的figure,进行解释),便于浏览及泛读效率。文章对应涉及的复杂公式进行简化处理或略过,深入细节请参考原文。
RSS 2025
DexterityGen: Foundation Controller for Unprecedented Dexterity
作者 Zhao-Heng Yin, Changhao Wang, Luis Pineda, Francois R. Hogan, Chaithanya K. Bodduluri, Akash Sharma, Patrick Lancaster, Ishita Prasad, Mrinal Kalakrishnan, Jitendra Malik, Mike Lambeta, Tingfan Wu, Pieter Abbeel, Mustafa Mukadam.
内容简介:这篇工作把“人类远程操控的意图(高层)”与“强化学习得到的低层运动基元”拼接起来,打造一个通用“灵巧操控基础控制器”。直觉上,人擅长给出粗粒度的动作命令,但很难在没有触觉的异构手上做细致稳定的操作;而 RL 擅长把低层接触与稳定性打磨得很扎实。作者先用 RL 在模拟中学出一大堆“灵巧手运动原子”(如在手内旋转/平移、再抓取等),再把它们组织成“可被人类提示调用”的生成式控制器。到了真实世界,人类只需给出粗指令,控制器就能生成稳定、安全且细致的机器人手动作,完成工具使用、复杂重抓等高难度操控。实验证明它在稳定性(比如持物时长)上显著提升,并能做出此前少见的“用笔/螺丝刀/注射器”等灵巧技能。
如上论文 Fig.1 左侧显示“Coarse Motion Command → Foundation Dexterity Controller → Fine Dexterous Action”的链路,左侧是人类通过远程操控给出粗动作;中间是 DexGen 的“生成控制器”,把粗动作翻译成多接触、安全的细动作;右侧是各种高难技能(在手内大幅重定向+工具使用)的实拍帧。要点:①“提示→细动作”的箭头表明这是“以人提示驱动”的运动合成;②控制器内部标出“RL 预训练基元库”,解释了“泛化来自大量运动原子”的直觉;③右侧多案例并列,强调“同一控制器跨任务/跨物体的复用性”。
DOGlove: Dexterous Manipulation with a Low-Cost Open-Source Haptic Force Feedback Glove
作者 Han Zhang, Songbo Hu, Zhecheng Yuan, Huazhe Xu.
内容简介: 这篇是“让人更像人地遥操作灵巧手”。很多遥操作系统贵、传感单一,操作者摸不到力和触感,导致精细操作难做。DOGlove 直接把力反馈 + 触觉做进低成本手套(硬件与软件开源),且支持 21 DoF 动捕与 5 DoF 多向力反馈,并在指尖提供振动触觉。核心直觉是:只要操作者真实“感觉到”手物接触,细微力控与摩擦调节就自然发生,从而能在无视觉或弱视觉时也稳健操控。进一步地,作者用手套采集演示并做模仿学习,显示该方案兼具“数据采集器”和“实时遥操工具”的双重价值。
如上“Figure 1(系统示意)”把手套结构、动力传递、以及“动作/力的重定向(retargeting)”画在一张图:①上半是手套的关节/拉索示意,标出 21-DoF 动捕与 5-DoF 力反馈路径;②下半是多种真实任务的照片拼图(无视觉力控瓶身、调控粘稠液体流量、在手内翻滚等)。
Dexonomy: Synthesizing All Dexterous Grasp Types in a Grasp Taxonomy
作者 Jiayi Chen, Yubin Ke, Lin Peng, He Wang.
内容简介: 问题是:灵巧抓取不该只有“抓住没”,而是要按抓取类型来抓(比如 31 类 GRASP taxonomy)。作者提出一个从“人标注的手型模板”出发、两阶段自动合成大规模“类型化”灵巧抓取的流水线:先“让物体适配手模板”,再在物理仿真里“让手微调适配物体”。该策略能生成接触丰富、无穿模、物理可信的抓取,并通过接触力控制校验。最后他们做出 10.7k 物体、950 万抓取、31 种抓取类型的大数据集,并训练一个“按抓取类型条件化”的生成模型,在真实世界从单目点云就能执行目标抓取类型。直觉上就是“先有可泛化的类型库,再学会从视觉把‘类型意图’落到手上”。
如原文 图 2,把“按抓取类型生成”的核心模型拆开:输入是单视角点云与抓取类型码本(codebook);经 Sparse3DConv 提取物体表征后,与类型向量拼接进入Mobius 正态化流,输出抓取位姿与其质量评分;随后经 MLP 预测pre-grasp / grasp / squeeze三段手部关节配置。图中红色虚线框特别标出“类型条件”模块——没有它就退化成不区分抓取类型的生成。
Dex1B: Learning with 1B Demonstrations for Dexterous Manipulation
作者 Jianglong Ye, Keyi Wang, Chengjing Yuan, Ruihan Yang, Yiquan Li, Jiyue Zhu, Yuzhe Qin, Xueyan Zou, Xiaolong Wang.
内容简介: 这是一篇“用生成模型造海量演示”的灵巧手数据工程论文。直觉上,灵巧操控需要极多样的演示,而真实采集贵且慢——于是作者用带几何可行性约束的生成模型,批量合成十亿级抓取与关节/铰接操作演示。大数据不仅在模拟基准上显著超越已有方法,还能迁到实机验证鲁棒性。更重要的是,它把“灵巧操控”的数据鸿沟变成“算力 + 几何约束”的工程问题,释放了后续大模型/大策略训练的潜力。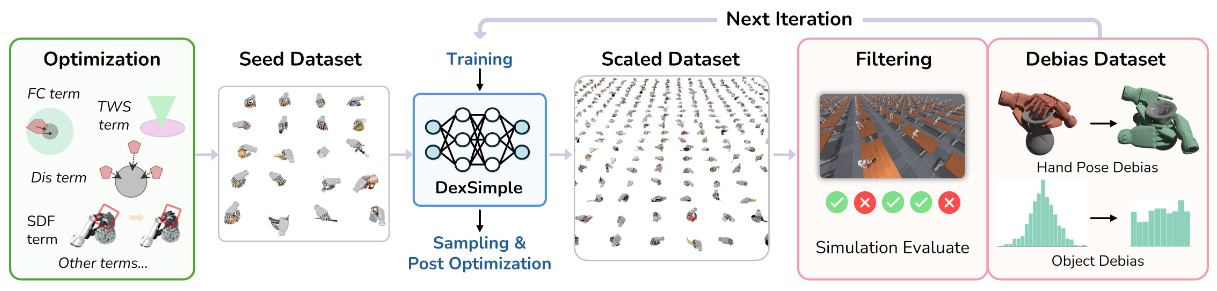
如上图,输入:对象资产(多类可操作物体)+ 手部初始姿态。 → 控制式优化先行:基于可微力闭合/任务扭矩空间等能量项合成稳定接触的关键手姿,得到Seed(小而精)。这一步用球体近似手部几何 + SDF 约束避免穿模,并在关节限幅/自身碰撞项下搜索可行抓取/操作姿态。 训练生成模型(DexSimple):用 Seed 训练条件化的 CVAE(Conditional Variational Autoencoder),并在训练中显式加入几何可行性(点-球 SDF)等约束项,使生成结果更“可执行”。 规模化采样(π 倍扩展):用 DexSimple 生成Proposal(大规模候选)。图中以比例 π 标注“从小到大”的数据放大。 可行性与去偏:对 Proposal 先过仿真评审(simulation critic)过滤不可行轨迹,再用去偏采样(debiased algorithm)刻意补齐“少见条件”(如物体表面稀疏区域/困难对象),拉高多样性,得到Debiased。 优化细化(refinement):对 Debiased 结果做轻量后优化(只调接触/穿模/距离项,微调指尖贴合),在保证效率下进一步提升物理可行性与接触质量。然后写回仿真验证。 迭代闭环 → Dex1B:将净化后的数据并入训练集,再训练更强的生成器,再扩一轮……多次迭代后,数据规模不断放大形成成功轨迹,构成 Dex1B。
Vib2Move: In-hand Object Reconfiguration via Fingertip Micro-vibrations
作者 Xili Yi, Nima Fazeli.
内容简介: 这篇很“巧”:不用复杂的全手重规划,而是让指尖打微振、借重力把物体在掌内微位移、微旋转。直觉上,这像人手用“轻颤+轻松开”把薄片或小件重新对齐——能省算力,也能化解高摩擦导致的卡滞。作者系统化地建模/实证“振幅、频率、法向载荷”与物体迁移的关系,并在真实系统上展示在手内重构姿态的鲁棒性。价值在于:把“在手内二次定位/配准”的老难题,化为可控的动态摩擦调制。
如上原文 图 7,用微振动动态调摩擦、在重力平面内建模滑动、用两类原语(旋转/振动)做闭环路径规划——串成一条从初始到目标位姿的完整流水线。Stage 1:Centering the Object ,先通过姿态重构重力场,再用振动降低等效法向力→减摩诱发可控滑动。 Stage 2:Positioning to the Goal,重复“定姿不振动→定姿振动→视觉反馈校正”的闭环节拍,逐步把位置误差压到 r_error 以内。 Stage 3:Adjusting Orientation, 当平移误差达标后,再次选择能产生充足重力力矩的夹爪朝向,发振让物体做近纯旋转,把角度误差压到阈值内;最后小幅校正因旋转带来的微小位移耦合。
CordViP: Correspondence-based Visuomotor Policy for Dexterous Manipulation in Real-World
作者: Yankai Fu, Ning Chen, Qiuxuan Feng, Zichen Zhou, Mengzhen Liu, Mingdong Wu, Tianxing Chen, Shanyu Rong, Jiaming Liu, Hao Dong, Shanghang Zhang.
内容简介: 核心直觉:单目点云质量参差、手指遮挡严重,直接“点云→动作”很难;那就先构建“手-物对应”。作者提出以稳健 6D 位姿估计 + 机器人本体感知为基础的“交互感知点云(interaction-aware point clouds)”,并显式学习物体表面接触图与臂-手协同信息。这些结构化要素用来预训练表征,再接上扩散策略做模仿学习。4 个真实任务上,方法表现出更强泛化与鲁棒性(跨视角、跨物体)。它把“3D 信息稀疏+遮挡”的现实痛点,换成“可学的空间对应关系”。
如上原文的Fig. 2(Overview Framework),形成交互感知点云→基于接触与手臂协同的表示预训练→对应关系驱动的扩散策略——在一条可复用的流水线上串起来。具体地, (a) Interaction-aware 3D Point Clouds(交互感知点云): 单视角 RGB-D 的遮挡与噪声难以支持灵巧操作。作者先用 TripoSR 从单张图生成物体的数字孪生初始点云,再用 FoundationPose 进行稳健 6D 位姿跟踪;同时依据机器人 proprioception(关节状态)通过前向运动学生成手部点云。将“物体点云 + 手部点云 + 姿态”融合成交互感知点云,在不同视角下仍具一致性与完整性,为后续学习提供可靠 3D 观测。 (b) Contact & Coordination-Enhanced Pretraining(接触与协同增强预训练): 以大规模 play data 预训练观测编码器,i. 接触图(contact map)预测:从“物体-手”点云计算物体表面到手表面的对齐距离,得到接触强度监督,促使编码器显式学到手-物接触几何;ii. 手-臂协同(coordination)建模:将手与臂的状态特征做交叉注意力建立时空对应,分别用“手→臂动作、臂→手动作”的重构损失,让表示捕捉协同运动学。 结果是得到一套已“注入接触/协同先验”的 3D 表示(ϕ_H, ϕ_O, ψ_A,H)。 (c) Correspondence-based Diffusion Policy(对应关系驱动的扩散策略): 将上一步的表征作为条件,训练条件扩散策略(DDPM/DDIM 推理加速),直接在动作空间去噪生成控制序列。与常规 2D/3D BC/DP 不同,策略条件里自带手-物空间对应与手-臂时间协同,因此对遮挡、视角变化、未见物体/场景更稳健,示范样本效率也更高。
Complementarity-Free Multi-Contact Modeling and Optimization for Dexterous Manipulation
作者 Wanxin Jin.
内容简介: 多接触动力学传统常用“互补约束(complementarity)”,但它不光滑、求解棘手、调参多,难以上实时。作者从“优化接触模型的对偶”出发,提出完全不依赖互补约束的轻量多接触模型:闭式时间推进、可微、自动满足库仑摩擦、且几乎不用调参。用它做规划与控制,覆盖三类灵巧任务(指尖空中 3D 操控、TriFinger 在手内操控、Allegro 掌内重定位),平均成功率 96.5%、平均重定向误差 11°、MPC 50–100 Hz。直觉上,它把“接触复杂性”收敛到一个数值友好的建模框架里。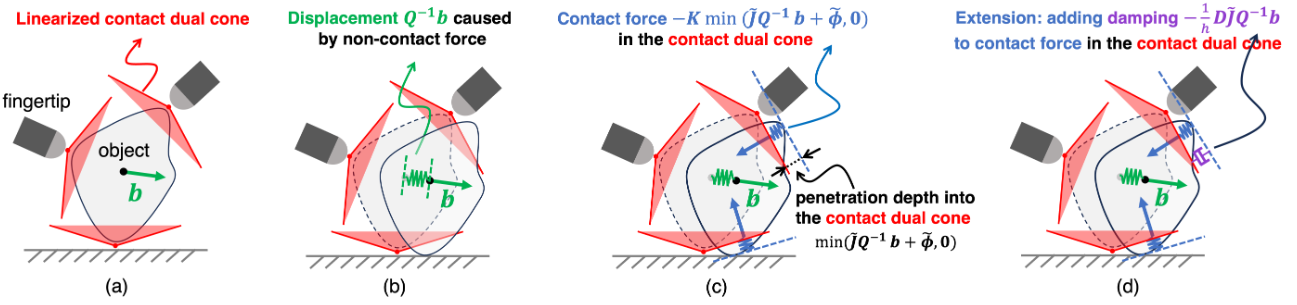
如上原文Fig. 2 ,用一个不含互补约束(complementarity-free)的闭式多接触模型来近似传统接触动力学。具体地(详细公式请参考原文), (a) 红色阴影:线性化的“接触对偶锥”约束区域。 这是原始 QP 接触模型中的对偶锥约束的几何示意;物体与地面/指尖的接触可行域被红区刻画。 (b) 绿色箭头:仅由“非接触力”b 引起的位移。 (c) 蓝色箭头:由“穿入对偶锥”触发的“弹簧样”接触力。 直观上就是“若位移使得状态穿入(penetrate)红色对偶锥,就像把‘弹簧’压缩了,于是产生朝外的接触力”。 (d) 紫色箭头:把阻尼并入接触力(扩展版)。 在弹簧样项之外,再加一项与接触点相对速度相关的阻尼,形成更稳定的时步更新;这在图 (d) 以紫色标示。
ViTaSCOPE: Visuo-tactile Implicit Representation for In-hand Pose and Extrinsic Contact Estimation
作者 Jayjun Lee, Nima Fazeli.
内容简介:在手内操控要同时估计“物体在手中的位姿”和“外部接触(手-物)分布”,而视觉部分可见、触觉局部稀疏,两者都不完整。ViTaSCOPE 用隐式表示统一这些信息:用 SDF 表示物体几何,用“神经剪切场”表示触觉分布,再把两者对齐到同一物体坐标系。直觉上,“把触觉当作几何上的连续场”,就能和视觉天然互补。作者在仿真和实机上验证该表示能更稳地恢复在手内的物体状态与接触结构,从而支撑更可靠的灵巧操控。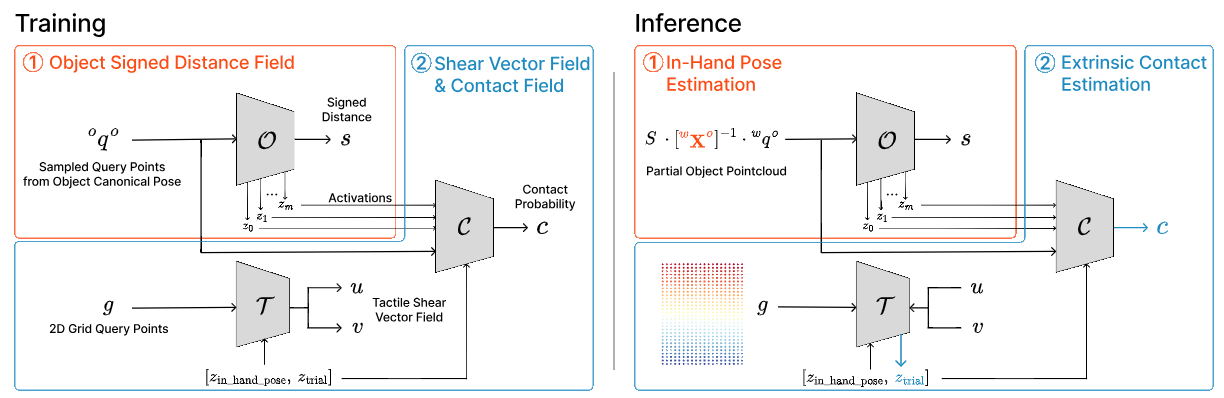
如上原文图3展示的就是: 先用 SDF 把几何定准 → 用优化找手内位姿 → 用潜码解释触觉剪切 → 以几何感知的方式估计外部接触。简单地,物体模块学“形状”(把物体几何学成一个可查询的形状表示); 触觉模块学“剪切位移场”(触觉膜上被外界接触拉动/摩擦产生的位移分布);接触模块学“哪里在接触”(按空间位置输出接触的可能性)。这三块合在一起,就是既懂几何、又懂触觉、还能判断接触的统一表示。 具体地,如图所示(为了简单符号表示,公式中“P~”表示P-tilde,"_"表示sub(下标)):
- O / T / C:三块模块——O(Object)学物体形状,T(Tactile)学触觉剪切场,C(Contact)学接触概率场。
- 输入与查询:P~={P~t,P~v} 是触觉/视觉点云;q 是三维查询点;g 是触觉膜上的二维网格点(s_x,s_y)。输出有:s(SDF 形状值)、c(接触概率)、ϕ(剪切向量场)。
- 编码与中间特征:zξ 表示“手内位姿”编码,zψ 是“外部接触试探码”,zO 是 O 的分层激活(几何特征)。
训练(Training)
先训 O:单独把 O 训练好,让它稳定地给出形状 s(物体表面可由 s=0 恢复点云/网格)。然后冻结 O。 再训 T 与 C:在冻结的 O 上,联合训练 T(从 g 处预测剪切 ϕ,条件包含 zξ、zψ)和 C(在三维位置上输出接触概率 c,并以 zO 与 zψ 为条件,让接触判断“懂几何”)。
推理(Inference)——按图示从左到右
先定姿态(估 zξ):基于视觉+触觉点云的联合信息,做“优化式推理”,先把物体在手里的姿态对齐好。 再解接触模式(估 zψ):给定姿态后,用观测到的剪切场 ϕ(g) 去反推“哪种外部接触模式更能解释这些剪切”,得到zψ。 最后判接触(出 c):C 在空间各点查询接触概率 c,并利用 zO(几何特征)与 zψ(接触模式)来做“几何感知”的接触预测;把c 高且在 s=0 的表面那些点,集合起来就是接触贴片。
PP-Tac: Paper Picking Using Tactile Feedback in Dexterous Robotic Hands
作者 Pei Lin, Yuzhe Huang, Wanlin Li, Jianpeng Ma, Chenxi Xiao, Ziyuan Jiao.
内容简介: 薄而软的纸类物体是机器人“最难拿稳”的类型之一:边缘细、外观多变、极易打滑。PP-Tac 搭一个带全向高分辨触觉的多指灵巧手系统,实时检测滑移并做在线摩擦力调节;动作生成上,先合成“捏纸”运动数据,再以扩散策略学出手-臂联合抓取。结果在多材料/多厚度/多刚度的薄片上实现 87.5% 成功率。直觉上,它把“纸张抓不住”的难点,变成“触觉闭环 + 统计生成”的可学问题。
如上原文Fig. 6 — PP-Tac policy 的推理流水线(Inference pipeline),将触觉先觉(R-Tac 深度重建+滑移检测+在线力控制)与扩散式策略生成整臂–手联动动作——串在一条闭环里。具体地,
- 输入侧(System State & Tactile Image):机器人本体状态(手指/手腕位姿与速度等)与触觉图像同步进入管线;触觉图像先经Depth Reconstruct变成传感膜的变形深度读数,用作后续力控制与策略条件。
- 滑移检测(Slip Detector)→ 力闭环:若检测到slip,就把“目标变形深度”(等价于更大的按压力)小幅上调,以提高静摩擦、抑制打滑,保证材料持续起拱(buckling)并形成可夹持区。
- 扩散策略(PP-Tac Policy):给定历史前缀运动、当前帧索引、扩散步 t与目标变形深度,编码器式 Transformer 在扩散去噪过程中预测未来若干步动作序列(手指关节+手腕姿态)。训练时用接触一致性等约束让“关节角—空间位置”自洽;推理时只需少量去噪步数即可实时输出。
- 输出侧(Position Control):预测到的手–臂联动动作直接下发到位置控制器执行;若过程中再次出现滑移,触觉分支继续闭环调力,形成“触觉—策略—执行”的稳健闭环。
RUKA: Rethinking the Design of Humanoid Hands with Learning
作者 Anya Zorin, Irmak Guzey, Nikhil X. Bhattasali, Lerrel Pinto.
内容简介: RUKA 不是“控制算法”,而是手的结构设计思路:用学习驱动的方式反推“什么样的关节与传动布局”更利于灵巧操控。直觉上,很多灵巧难题来自“先天骨架/耦合”的限制;如果把任务需求(在手内重定向、稳定重抓、指尖操作)放进优化/学习闭环,手的形态也能随之“适配任务”。作者展示了设计到实物的闭环证据,并给出项目页与开源资源。它提醒我们:软件(策略)和硬件(骨骼/腱)需要协同演化,才能把“灵巧”从算法层面真正落到机械层。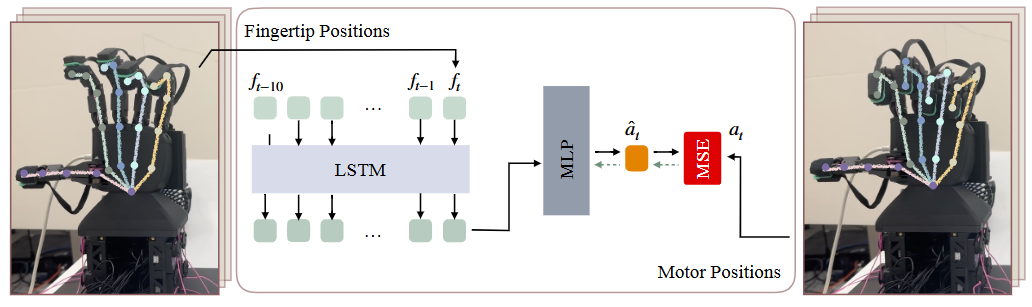
如上原文Fig. 8 — Controller architecture with MANUS gloves,展示“用学习解决腱驱手的控制难题”:左侧展示 MANUS 手套采集的人手/机手关键点与指尖位姿,中间是基于 LSTM 的时序编码 + MLP 回归的控制器,右侧是电机位置输出,实现从“指尖/关节目标→电机指令”的直接映射。具体地,
- 输入侧(数据来自 MANUS 手套):为每根手指采集指尖三维位置和一组关键点(人/机两种采集方式皆可)。这些时间序列会被送入控制器作为条件。
- 控制器结构(LSTM→MLP):控制器对最近若干帧的手指状态做时序编码(图中标注 ft, ft-1, …, ft-10),得到一个紧凑表示,再由 MLP 直接回归各关节的电机位置。论文实际为每根手指训练一个小模型:拇指用“指尖位姿→电机”,其余手指用“关节角→电机”,以贴合硬件/手套输出差异。
- 输出侧(Motor Positions):模型一次输出该手指对应的电机目标,闭环执行即可复现目标手势/指尖位置;整套方法避免了腱驱系统里“电机—关节—指尖”非线性、弹性、间隙带来的解析建模困难。
DexWild: Dexterous Human Interactions for In-the-Wild Robot Policies
作者 Tony Tao , Mohan Kumar Srirama∗, Jason Jingzhou Liu, Kenneth Shaw, Deepak Pathak
内容简介:让机器人手在“野外环境”也能像人一样稳地操作新物体、新场景,甚至换一套胳膊/手(跨形体)也能迁移。难点是:大规模高质量机器人数据很难、很贵,纯看网上视频又不够精确。DexWild-System:一套轻便、低成本、几分钟就能架好的“人手交互采集套件”,让普通人用自己的手在各种真实场所采数据(准确的手指/手腕轨迹 + 掌上小相机视角),一共攒了 9,290 段、93 个环境的人手示范;DexWild 共训练框架:用大量人手数据提供多样性,再配少量机器人示范做“形体落地”校准,二者按比例一起训练策略。How does co-training help with scaling up in the wild performance?
如原文Fig. 6,用三组柱状图直接量化出来“人手数据 + 少量机器人数据的共训练最能带来泛化”。具体地, In-Domain(同域新物体):只用机器人数据还能行,但1:2 共训练直接把平均分从 64.7%→79.8%。说明人手数据带来了对物体多样性更稳的表征。 In-the-Wild(机器人数据没见过这些场地):机器人单练掉到 28.5%;1:2 共训练飙到 75.1%,核心原因是人手数据覆盖了复杂真实场景,而少量机器人数据提供动作空间的落地。 In-the-Wild Extreme(两个数据集都没见过的极端新场地):机器人单练仅 22.0%,1:2 共训练到 62.7%。同时也能看出:人手=1:5时反而下降(例如Wild仅 50.9%),意味着“没有机器人校准会失去精准操控”,比例过高会被“人手分布”带偏。
此图解读为,人手数据=视觉与交互的多样性,机器人数据=形体与控制的落地;两者1:2权衡最好。 过拟合现象:只用机器人数据在新场景大幅掉分,证明“场景特异性过强”; 过分人手化的风险:人手占比太高会缺“机器人动作对齐”,导致实际执行不稳。
CoRL 2025
DexUMI: Using Human Hand as the Universal Manipulation Interface for Dexterous Manipulation
作者:Mengda Xu, Han Zhang, Yifan Hou, Zhenjia Xu, Linxi Fan, Manuela Veloso, Shuran Song.
内容简介:这篇工作把“人手”变成学习灵巧操作的通用接口。难点在于人手与各式机器人手之间存在巨大的体态差距(embodiment gap):运动学不一致、视觉外观不同、触觉信号也不同。DexUMI提出硬件 + 软件两层适配:硬件是一套可穿戴手部外骨骼,强制让演示动作落在目标机器人手的可行空间里,同时记录近似于机器人端的关节与触觉;软件端用视频分割 + 机器人手修复/“换手”补绘把人手演示的视频转成“仿佛机器人亲自操作”的训练素材。这样一来,数据采集不必依赖实时遥操作,效率更高,且同一套流程可迁移到不同形态的灵巧手(如 Inspire、XHand)。实机实验显示多个任务上有较高成功率,说明“人手即接口”的思路确实能缩小跨硬件的落差。
如原文Figure 1,展示把“缩小体态差距”的两条主线(动作/观测):外骨骼解决动作可行性,视频换手解决观测一致性,整套“人手 → 机器人手”的双通道适配总览:左侧是佩戴外骨骼的人手进行真实接触操作;右侧是经过视觉域适配后得到的“机器人手版本”演示。 关键元素:① 硬件适配——外骨骼以关节到指尖映射一致为目标优化设计,确保采集到的手部动作可直接映射到不同型号机器人手;② 软件适配——对演示视频先做人手与外骨骼分割,再把机器人手的渲染片段与场景背景重合/替换,得到“机器人视角一致”的训练数据;③ 多平台泛化——同一流程示范在欠驱动与全驱动两类灵巧手上完成多任务。
Text2Touch: Tactile In-Hand Manipulation with LLM-Designed Reward Functions
作者:Harrison Field, Max Yang, Yijiong Lin, Efi Psomopoulou, David Barton, Nathan F. Lepora.
内容简介:这篇工作把大语言模型(LLM)请来“写奖励函数”,专攻带触觉的在手多轴旋转这种高难度灵巧操控。传统奖励设计又长又脆,尤其面对高维触觉容易调不动;作者把环境上下文与变量清单喂给 LLM,让它迭代地生成/改写奖励。为了上机可用,先在仿真用Teacher学带特权信息的策略,再蒸馏到只看本体感知 + 触觉的Student,零样本落地到四指全驱灵巧手 + 视觉型触觉传感器上。结果显示 LLM 奖励既更短更简洁,又能在真实硬件上把稳定旋转做得更快更稳,省掉大量人工调参时间。直觉上,就是用“会写规则的 LLM”去驯服“读触觉的灵巧手”。
如上原文的Figure 2展示了“LLM 产奖 + 师生蒸馏 + 触觉上机”三段式主线,从文本任务描述/环境信息 → LLM 生成候选奖励 → 迭代筛选/反思改写,产出Teacher策略;随后Teacher→Student 蒸馏,只保留真实部署可得的触觉 + 本体观测。其中,绿色模块标注提示工程与可扩展变量(>70 个)以减少语法/语义错误;黄色是Teacher,紫色是Student(可上硬件);右侧是实机部署到带 TacTip 触觉的 Allegro Hand 的闭环流程。
RobustDexGrasp: Robust Dexterous Grasping of General Objects from Single-view Perception
作者:Hui Zhang, Zijian Wu, Linyi Huang, Sammy Christen, Jie Song.
内容简介:这篇工作追求“一眼看过去就能稳抓各种新物体”的灵巧抓取,而且还能在干扰下自适应。核心直觉是:与其精准重建全局几何,不如构造“手中心”局部形状表征——用各关节到物体表面的动态距离向量,直接描述潜在接触区域;再配一套Teacher(带特权视觉/触觉)→ Student(仅初始单视点 + 噪声关节)的训练流程:先模仿蒸馏能力,再用强化学习学会抗扰自适应。最终在24 万+ 仿真物体与512 个真实物体上都拿到高成功率,说明“少视角 + 局部表征 + RL 自适应”这条路泛化强、韧性好。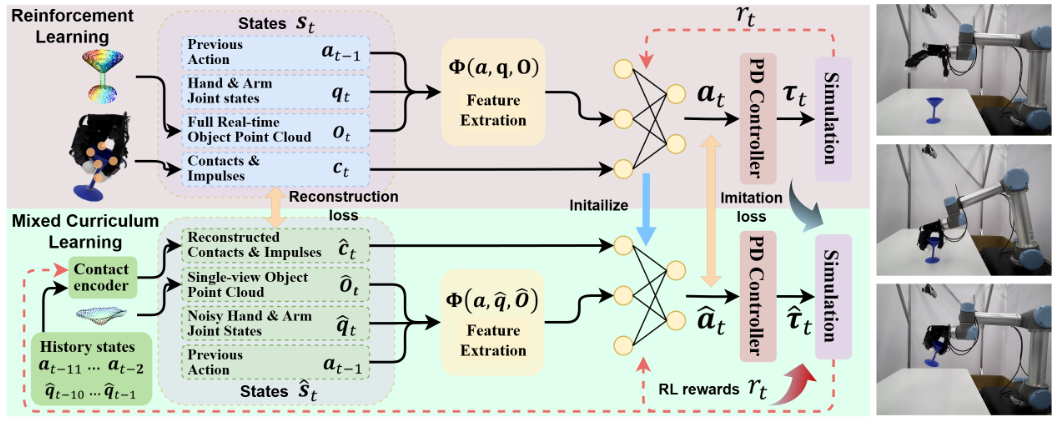
如上原文的Figure 2展示了局部几何表征、师生蒸馏、抗扰 RL 课程,解释了为何能在单视点与外界干扰下仍稳抓广域未知物体。自上而下地串起Teacher/Student 双策略与混合课程(IL→RL)训练框架:Teacher 拿特权接触/冲量 + 全量点云学会“理想抓取”;Student 只有初始单视点点云 + 噪声关节,在模仿基础上逐步切换到 RL,学习在随机干扰/观测噪声下自适应动作。输入侧的手中心距离向量表征(finger-to-surface distance),策略输出到手/臂关节目标,以及贯穿训练的接触/冲量重构损失。
ClutterDexGrasp: A Sim-to-Real System for General Dexterous Grasping in Cluttered Scenes
作者:Zeyuan Chen, Qiyang Yan, Yuanpei Chen, Tianhao Wu, Jiyao Zhang, Zihan Ding, Jinzhou Li, Yaodong Yang, Hao Dong
内容简介:目标是在强遮挡与高杂乱度场景里做目标导向的灵巧抓取,还要能零样本迁移到真实环境。论文构建了“教师→学生”两阶段框架:教师在仿真里拥有更强的感知与闭环控制能力来产出可迁移的示范,学生则在现实的稀疏感知下执行稳定抓取。配合域随机化与关键转移技巧,系统能在严重遮挡时保持鲁棒。核心价值是把“闭环灵巧抓取”从实验室“干净条件”推进到真实工业/生活场景的杂乱环境。
如上原文Figure 2 — Training Framework展示仿真里先用老师策略学会在不同拥挤度下的安全抓取 → 再把老师的知识蒸馏到只看点云的学生扩散策略 → 直接零样本上真实机器人。具体地,
- Teacher:在仿真中三阶段课程学习 ① Stage 1 — General Grasping:先在单物体场景把“基本抓取能力”练扎实; ② Stage 2 — Strategic Grasping:再到拥挤(clutter)场景学“绕障/清障后再抓”的策略; ③ Stage 3 — Safety Curriculum:最后加入安全约束(力阈、桌面接触惩罚等),把“过猛、碰撞多”的动作收敛为 低冲击、可部署 的接触行为。三阶段共同依赖一套几何+空间嵌入表示(对每段手指连杆同时计算到目标物与非目标物的最近距离向量),既编码了局部几何,又让策略天然“感知杂物”和风险。
- 数据生成与筛选
用已学成的老师策略在不同拥挤度场景里滚动采样成功轨迹,并做数据过滤,为后续蒸馏准备“既多样又干净”的示范。 - Student(DP3 扩散策略):从特权观测到点云观测
学生策略只用单目相机的部分点云 + 机器人关节,骨干是 3D Diffusion Policy (DP3)。图中两项关键的sim-to-real桥接: Point-cloud alignment:把相机点云与合成的机器人/地面点云拼起来,并带目标掩码,补密度、稳空间关系; System Identification:对手臂和灵巧手做系统辨识,缩小动力学差距。最后学生以 15 Hz 输出手臂—手的动作序列,实现闭环抓取。 - Zero-shot Real-World
右侧落地框表明:学生策略不需要任何真实示范,可直接零样本部署到实机,在稀疏/密集/超密集等多种拥挤度、未见物体/布局上保持高成功率与温和接触。
LodeStar: Long-horizon Dexterity via Synthetic Data Augmentation from Human Demonstrations
作者:Weikang Wan, Jiawei Fu, Xiaodi Yuan, Yifeng Zhu, Hao Su
内容简介:难点在于长时序灵巧操作既要细腻接触动作,又要把多个技能无缝串接。LodeStar 从少量人类演示出发,先用基础模型把演示自动分解为语义化技能片段;再以残差式 RL在仿真中为每个技能生成多样化合成演示扩充数据;最后用Skill Routing Transformer在执行中选择/衔接技能实现端到端长任务。核心价值是:不用巨量真实数据,也能得到稳健、可迁移的长时序灵巧操作策略。
如上原文Figure 2 — LODESTAR Pipeline展示了(1)自动切分技能、(2)用仿真生成合成示范以强化每个技能、(3)用“技能路由 Transformer”把技能顺畅串起来完成长时序任务。具体地,
- ① 技能切分(Skill Segmentation):把少量人类示范按帧切成“操作技能段”和“过渡运动段”。做法是用视觉/视觉-语言基础模型(从视频中提取空间与接触线索)构建每个技能的帧级判别器:既看关键点的相对位置关系,也看指尖是否与目标物体接触,从而得到语义明确、边界合理的技能片段。
- ② 合成数据强化技能(Synthetic Data for Skill Training):对每个技能单独建仿真场景,基于少量真实示范做行为克隆得到“基础策略”,再用残差式强化学习在仿真里做域随机化与状态分布扩展,滚动采集多样且可行的成功轨迹;最终把真实+仿真的示范共同训练,得到更稳健的技能策略。
- ③ 技能组合(Skill Routing Transformer, SRT):在仿真中自动生成与筛选“技能之间的过渡轨迹”数据,然后训练一个Transformer:它在执行时决定当前处于“过渡”还是某个技能阶段,若是过渡就直接产生日常动作,若是技能则调用对应技能策略,从而把多个技能顺滑地衔接成完整的长时序任务。
DexSkin: High-Coverage Conformable Robotic Skin for Learning Contact-Rich Manipulation
作者:Suzannah Wistreich, Baiyu Shi, Stephen Tian, Samuel Clarke, Michael Nath, Chengyi Xu, Zhenan Bao, Jiajun Wu
内容简介:论文提出一种可弯折、可大面积覆盖的电容式“机器人皮肤”,能在曲面指腹/指背上提供高密度、可标定、可本地化的触觉读数。它面向学习型操控场景设计:读数可跨传感器实例快速标定、可直接构造奖励(如力度惩罚),并在在线 RL与学习自模仿等流程中稳定工作。实验覆盖在手重定位、包裹松紧物(橡皮筋)等“接触丰富”的灵巧操作,证明高覆盖触觉对策略学习与迁移的直接价值。
如上图原文Figure 4 — Pen reorientation task rollouts 展示了高覆盖、可定制的 DexSkin 让策略在纯触觉+本体感知下完成手内重定向,并且对外界扰动具备鲁棒恢复能力;与“降维触觉”(空间池化)和“无触觉”基线的并排对比,直接可视化了 DexSkin 的决定性作用。具体地,
- 上排(DexSkin):机器人先抓笔、再将其顶靠柜面完成手内转正;当人手在中途旋转扰动笔后,策略能读出触觉热力图的变化(尖端圆顶与侧壁税格显著发亮),重复关键动作把笔再次立起。这说明策略确实在用空间分辨率很高的触觉分布来推断“笔在手里的姿态”,并据此闭环修正。
- 中排(Spatial pooling 触觉):把整片触觉“压成少量统计量”后,策略难以判断当前是否已经转正,常常在无效动作上停滞;遇到扰动几乎不会恢复。这强调了局部接触位置信息的必要性——只看总压力/平均值不够。
- 下排(No tactile):完全看不见接触变化,就会机械重复训练态轨迹;一旦环境或物体发生细微变化(如被转回水平),便彻底失效。
FFHFlow: Diverse and Uncertainty-Aware Dexterous Grasp Generation via Flow Variational Inference
作者:Qian Feng, Jianxiang Feng, Zhaopeng Chen, Rudolph Triebel, Alois Knoll
内容简介:这篇工作要解决“多指手在仅有部分点云时,如何生成又多样又靠谱的抓取”。它用正则化流(Flow) 做成的深层潜变量模型(DLVM) 同时学习“先验流(看物体)”和“抓取流(看抓取)”。因为 Flow 可精确给出似然,作者把它当成“不确定性刻度”:看不见的表面(视角不确定)或 OOD 物体(对象不确定)都会给出更低似然,于是能风险感知地挑抓取。再把评分器与似然结合成不确定性感知排序,既多样、又稳,又能高效采样(相较扩散法更快)。在仿真和实机里,它在多样性与成功率上都显著优于现有方法。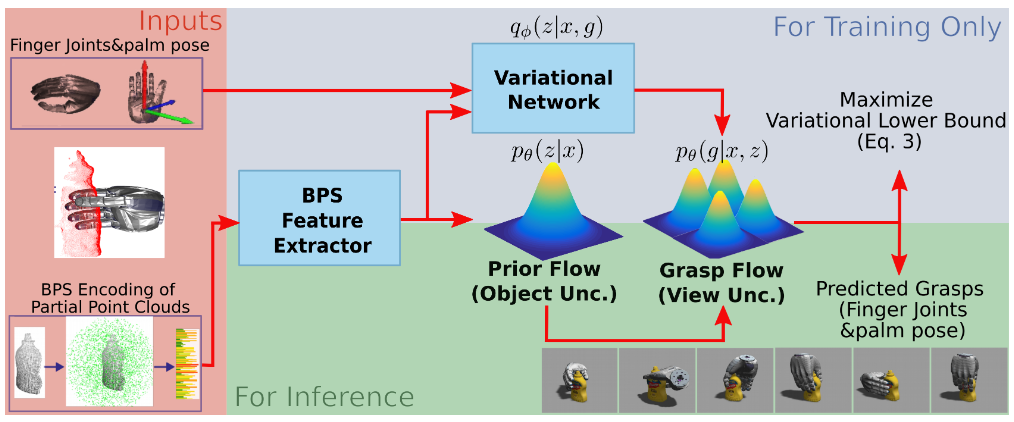
如上原文Figure 2 — Model Architecture 展示了 如何用“Prior Flow 建形状感知的潜空间,再用 Grasp Flow 生成多样抓取,并把流的似然变成可用的不确定性信号”,从而在多样性、成功率与推理效率上同时占优。具体地,
1) 训练阶段(上) 输入是部分点云(来自单视角/遮挡场景),先经点云编码(如 BPS)得到特征。 Prior Flow:学“点云→潜变量 z”的输入相关先验(比 cVAE 的固定高斯更灵活),让潜空间真正承载“形状/可抓取结构”的信息。 Grasp Flow:学“(z, 点云信息) → 抓取”的可逆映射,用正则的可逆流替代 cVAE 中僵硬的高斯观测假设,捕捉多峰抓取分布、避免坍塌。 变分网络:只在训练期用来推断 z 的近似后验,配合变分下界优化,把 Prior Flow 与 Grasp Flow 对齐,学到表达力强的潜空间。
2) 推理阶段(下) 先从 Prior Flow 采样 z(条件在当前点云),再送入 Grasp Flow 生成抓取候选;因为是离散可逆流,采样快、评估准(可直接算出似然)。 不确定性感知: Prior Flow 似然低 ⇒ 说明物体形状很新/分布外(对象级不确定); Grasp Flow 似然低 ⇒ 抓取更偏向不可见/未观测面(视角级不确定)。 不确定性融合筛选:把判别式抓取评估器分数与 Grasp Flow 似然融合,优先那些稳、且少碰撞的候选。
GraspQP: Differentiable Optimization of Force Closure for Diverse and Robust Dexterous Grasping
作者:René Zurbrügg, Andrei Cramariuc, Marco Hutter
内容简介:它要解决“怎么系统化地生成既多样又满足力闭合的灵巧抓取”。核心是把力闭合写成一个隐式的二次规划(QP)能量,并做成可微形式,这样既能优化也能用于大规模样本合成。作者还提出 MALA*(调整后的 Langevin 采样/拒绝策略),在能量分布上自适应地拒绝不良步长,提升收敛与解的稳定性。方法能产生覆盖捏取、三指精细抓等多类抓取型式,并在 5700 个对象、5 种手型、3 类抓取上构建了大规模数据集。结果显示在抓取多样性与最终稳定性上都更好。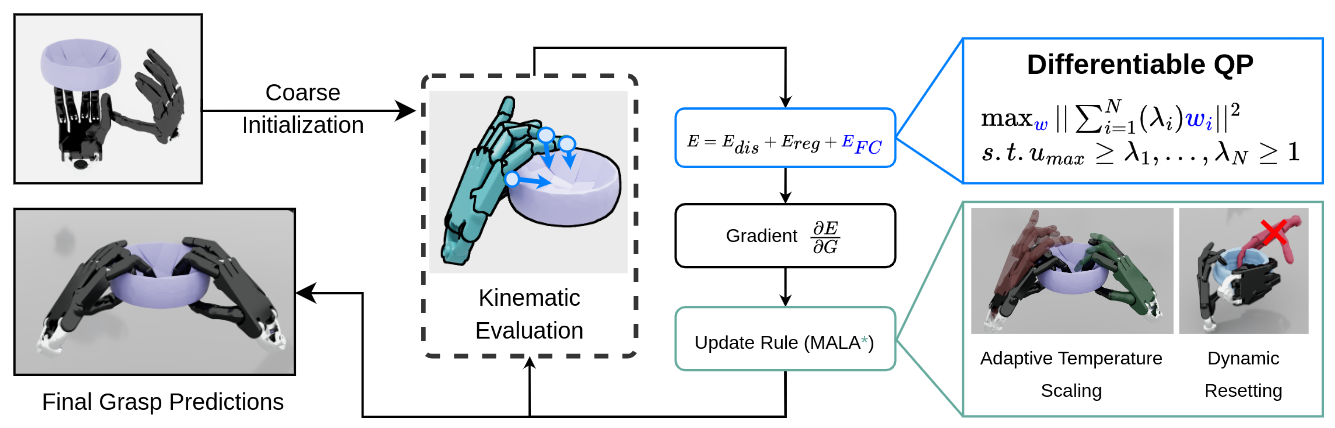
如上原文上图Figure 2 — Overview of our Grasp Generation Method,展示了(1) 基于可微QP的严格“力闭合”能量来保证物理可行、(2) 分布感知的 MALA* 优化来避免模式坍塌、提升多样性。具体地,如上图所示
- 粗初始化 → 候选抓取:从多种手型与物体上随机/启发式生成一批抓取“种子”,进入统一的能量最小化框架。
- 复合能量函数(E = 距离 + 正则 + 力闭合) 距离项:把被激活的接触点拉到物体表面附近、抑制穿透; 正则项:关节限位、手-物/自碰约束等,保证几何可行; 力闭合项:用可微QP显式计算接触扳手是否能正向张成六维扳手空间(含摩擦金字塔),并配合奇异值体积因子提升“抗扰空间”体量——这是与以往近似/放松指标最大的不同:物理更严谨,还能反传梯度。
- MALA* 分布感知优化 在每一步梯度更新后,不再“各抓取各优化”,而是看整批样本的能量分布来自适应调节: Dynamic Resetting:能量落在分布尾部的差样本自动重置,跳出劣势局部最小; Adaptive Temperature:谁比整体更“差”,谁就给更高温度、更易接受探索性步长,抑制模式坍塌、拉高多样性。
经过若干迭代,留下的是既稳定又彼此差异大的抓取集合。 - 输出
收敛后得到跨手型、跨抓取范式(power / pinch / precision)的高多样、物理稳定抓取预测,可直接用于数据集生成与下游学习/评测。
KineSoft: Learning Proprioceptive Manipulation Policies with Soft Robot Hands
作者:Uksang Yoo, Jonathan Francis, Jean Oh, Jeffrey Ichnowski
内容简介:目标是让软体手学会灵巧的在手内操作。它把软手的“形状本体感知”当成一等公民:设计内嵌应变传感阵列做遮挡无关的形状估计,用它来支撑基于扩散的模仿学习,再配一个按目标形变轨迹跟踪的形状条件控制器。核心直觉是:软体的顺从性不是负担而是教学优势(人手可“牵着”软手走出示范),于是数据收集更自然、更对齐本体状态。实验显示:形状估计更准、轨迹跟踪更稳、任务成功率更高。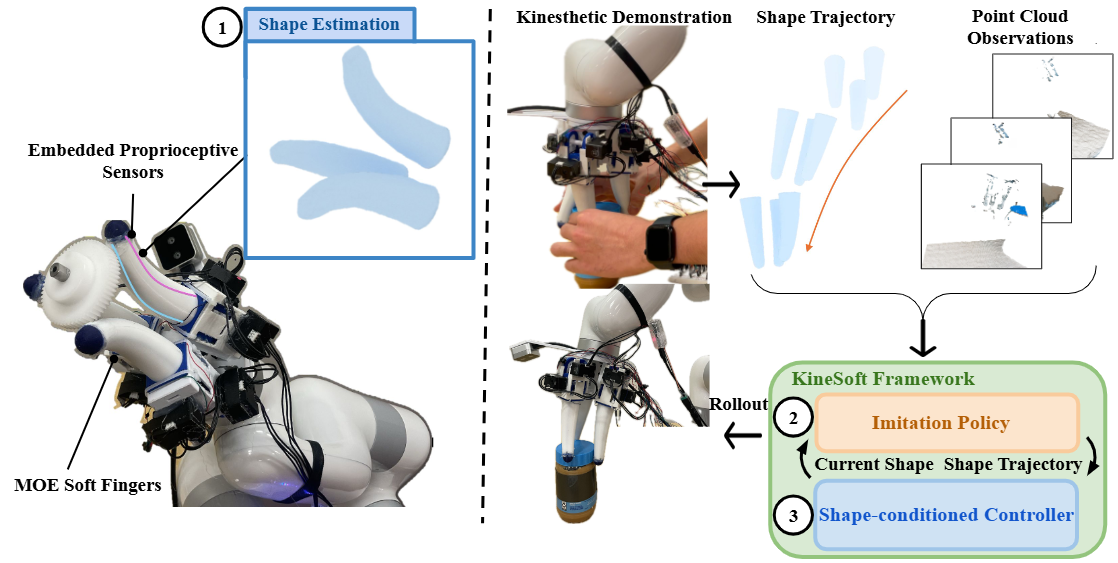
如上原文Figure 1 — KineSoft Framework,展示了(1)用嵌入式应变传感做“形状级”本体感知 ;(2)用扩散式模仿学习在形状轨迹上学策略 ;(3)用“按形状跟踪”的低层控制器把策略变成可执行动作。具体地,
- 输入与示教:人直接“捏/推”软手完成kinesthetic demonstration;同时,嵌入式应变传感阵列读出手指内部形变,手腕相机提供点云观测。这一步得到的是“形状轨迹”(而非传统关节角/力矩)。
- 高保真形状估计(Proprioceptive model):把多路应变信号映射为网格顶点位移,实时重建每根手指的三维形状;这是后续学习与控制的统一状态表示,能跨“人手示教/电缆驱动执行”的差异保持一致。
- 模仿策略(Diffusion-based imitation policy):以“当前形状 + 场景点云”为条件,策略直接预测下一段形状变化(以及末端执行器小幅位姿调整),学到“如何把手指形状变成完成任务的动作”。
- 按形状跟踪(Shape-conditioned controller):把“期望形状 − 当前形状”的网格误差投影到每根手指两路拮抗腱的主变形方向上,生成伺服增量,100 Hz 闭环跟踪形状轨迹,把高层“形状意图”落为稳定的腱驱控制。
- Rollout(执行):上述三块闭环运行,完成诸如拧瓶盖、掀盖、莓果采摘、纸张/布料拾取、卡扣开盖等接触密集任务,体现软手在脆弱物体与复杂接触中的优势。
Self-supervised perception for tactile skin covered dexterous hands(Sparsh-skin / PercepSkin)
作者:Akash Sharma, Carolina Higuera, Chaithanya Krishna Bodduluri, Zixi Liu, Taosha Fan, Tess Hellebrekers, Mike Lambeta, Byron Boots, Michael Kaess, Tingfan Wu, Francois Robert Hogan, Mustafa Mukadam
内容简介:这篇面向磁性感知触觉皮肤(覆盖指尖、指节、手掌)做自监督预训练:输入为全手历史触觉+手爪运动学,输出一个通用触觉嵌入,可迁移到定位、状态估计、策略学习等下游任务。动机是视觉触觉(如 GelSight)只在指尖且带宽受限,而磁性皮肤覆盖广+响应快。预训练后,多个基准任务上样本效率和性能都明显提升(最高提升 41%+),相较端到端训练更稳更通用。价值在于给灵巧手的全手触觉提供了“像视觉那样的通用表征”。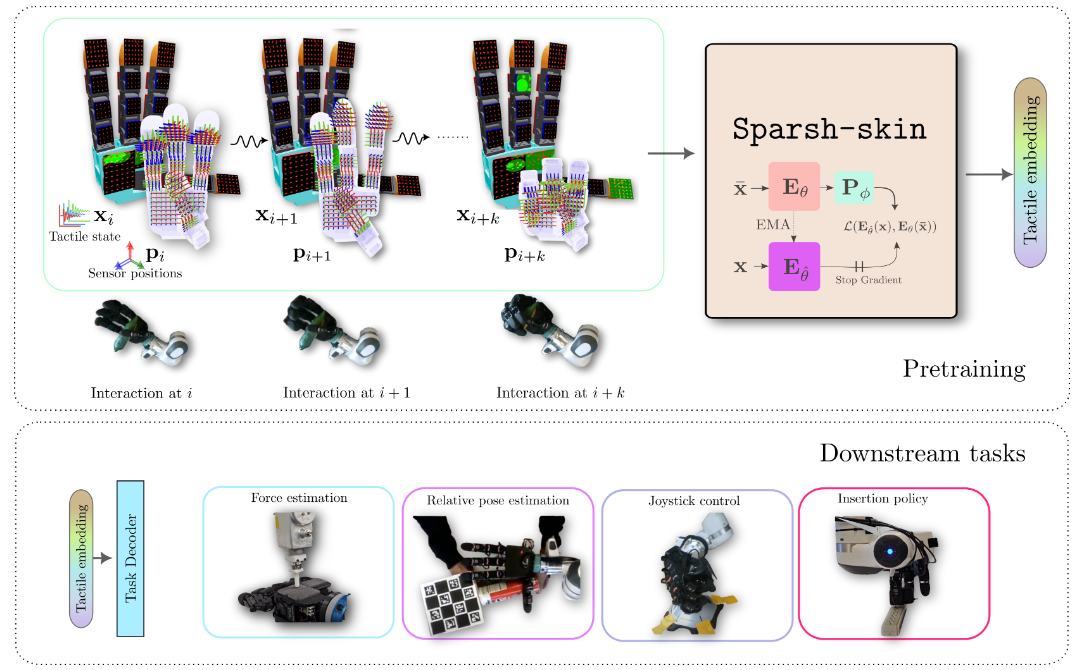
如上原文Figure 1 展示了 Sparsh-skin 的闭环——用自监督把“全手触觉流”学成通用表示,再把这套表示即插即用地接到各种接触密集型任务上,实现更强、更省标注、更易部署的灵巧操作感知与控制。具体地,
- 数据与硬件:Allegro 灵巧手贴满 Xela 磁触觉皮肤(18 片、共 368 个传感单元);收集约 4 小时“无标注、原子级在手交互”作为预训练素材。磁触觉的优势是全手覆盖、响应快(≈100 Hz),适合捕捉接触动态。
- 输入:每个时刻送入一小段触觉历史x_i 与对应三维传感器位置 p_i(来自手部运动学),而不是把触觉当成静态图像。这让模型显式利用时序+空间信息来理解接触。
- 预训练目标:自监督(学生-教师式自蒸馏)学到全手语境化表征;训练时会对触觉令牌做块掩蔽(跨相邻触点成块遮盖),要求学生去预测教师的高层表示,避免用重建像素那样的噪声敏感目标。
- 输出(可迁移表征):得到一个通用触觉嵌入,可直接接到不同解码头/策略上: 即时任务(如三轴力回归)用注意力池化的小 MLP; 时序任务(摇杆姿态、物体在手面上的平移/转角估计)用“Transformer + 注意力池化”; 策略学习(插头对孔)把表征与视觉特征一起输入策略解码器,显著提升成功率与样本效率。
Dexplore: Scalable Neural Control for Dexterous Manipulation from Reference-Scoped Exploration
作者:Sirui Xu, Yu-Wei Chao, Liuyu Bian, Arsalan Mousavian, Yu-Xiong Wang, Liang-Yan Gui, Wei Yang
内容简介:针对用人手/手–物 MoCap 大库训练灵巧手策略时的演示噪声与体现差距问题,Dexplore 用一个统一的“参考约束探索”单环训练:把传统“重定向→跟踪→残差”三段式合并,把演示当作软参考,策略在“参考范围”内用强化学习自己找最省力、可执行的动作。所得跟踪策略再蒸馏成视觉条件的生成式控制器,在多物体、多技能上泛化。价值在于:把不完美演示转成有效监督,并形成可扩展的灵巧操控控制。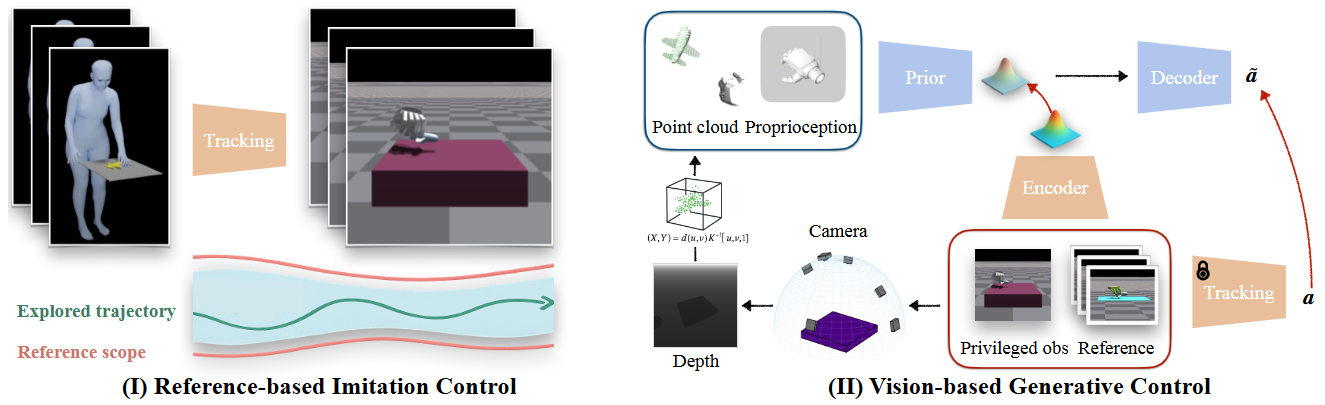
如上原文Figure 2 — Overview of DEXPLORE展示了(I) 用“参考范围探索”(Reference-Scoped Exploration, RSE) 学一个直接从 MoCap 学来的状态式跟踪控制器;(II) 再把它蒸馏成仅用单目深度 + 本体感知的视觉生成式控制器。具体地,
- (I) Reference-based Imitation Control(左半) 输入:手部本体感知(关节/腕部状态)+ 参考轨迹(来自人类 MoCap)。 关键做法:不要求“逐帧严丝合缝”的刚性跟踪,而是把参考轨迹转成空间“包络/范围”——只要滚动轨迹始终落在参考诱导的范围里就算成功;范围会自适应收紧,让早期大胆探索、后期更精准。 目的:让策略在保留人演示意图的同时,自行发现更符合机器人手形体/驱动限制的动作(避免三段式“重定向→跟踪→残差修正”的误差累积)。 产物:一个鲁棒的状态式“教师”控制器,可跨多物体/多手型追踪并完成接触丰富的操控。
- (II) Vision-based Generative Control(右半) 输入:单目深度重建的物体点云 + 本体感知(无特权物体真值/无 MoCap 在线对齐)。 核心结构:先验网络给出与观测相关的潜在技能分布,解码策略在该潜码条件下产出低层动作;训练时用 DAgger 把左侧“教师”动作蒸馏过来,并用 KL 对齐“推理时只有部分观测”的先验与“训练期有特权信息”的编码器。 能力:通过采样潜在技能实现多风格、人样行为的生成,并可泛化到新物体/新视角,最终实机部署只需一台深度相机即可闭环。
GraspVLA: a Grasping Foundation Model Pre-trained on Billion-scale Synthetic Action Data
作者:Shengliang Deng, Mi Yan, Songlin Wei, Haixin Ma, Yuxin Yang, Jiayi Chen, Zhiqi Zhang, Taoyu Yang, Xuheng Zhang, Heming Cui, Zhizheng Zhang, He Wang
内容简介:这篇把纯合成动作数据做到“十亿级”,训练出一个抓取方向的 VLA 基座模型。它把感知(自回归表征)与动作生成(基于 flow-matching)用“链式思考”范式统一训练,并结合互联网语义来缓解“语义-动作”鸿沟。好处是:成本低、不依赖昂贵的真机采集,还能零样本泛化与少样本定制(贴合人偏好)。从直觉上看,它把“数据鸿沟”问题反过来:先用超大规模、高随机性的合成数据学通用技能,再少量真实对齐。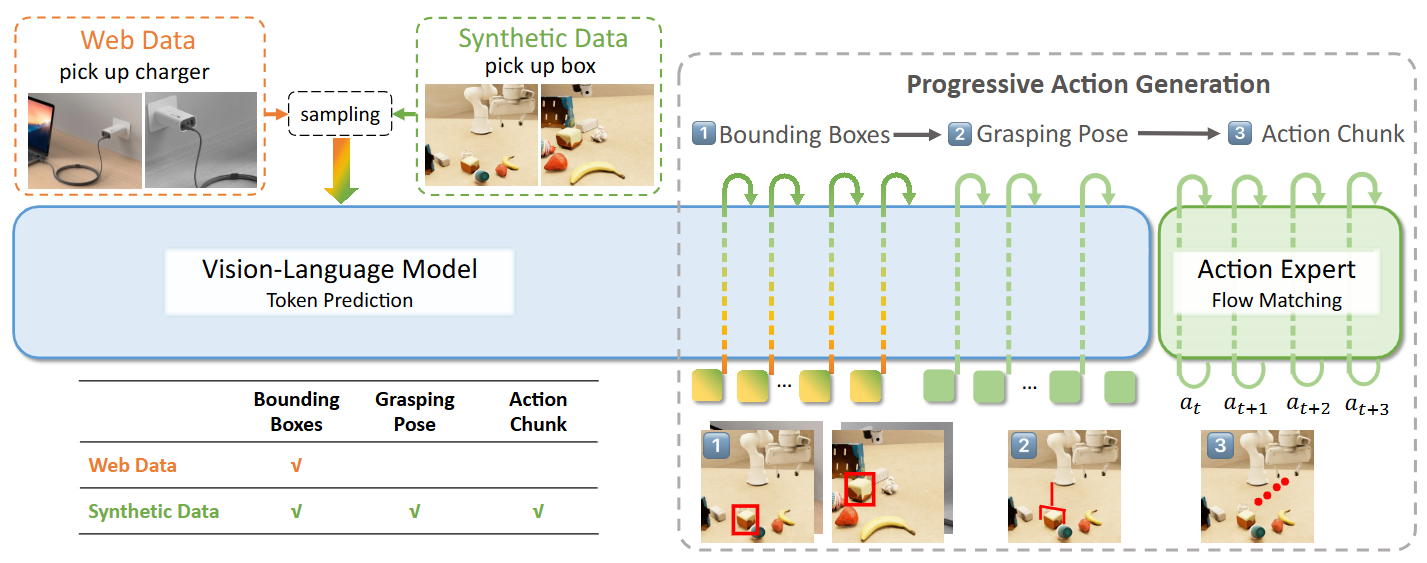
如上原文的Figure 3 展示了用 PAG 把“看懂(框/姿态)→会抓(动作段)”拆成可训练的链路,让“纯合成动作数据”与“互联网语义数据”在同一框架下协同,从而实现开放词表、强泛化、可零样本上机的抓取基础模型。具体地,
- VLM 视觉-语言骨干(左)
输入多视角图像与指令,先自动回归地输出目标物体的 2D 框;对合成数据还会继续预测抓取位姿(图中“Bounding Boxes → Grasping Pose”两步)。这一步把“互联网语义数据(只训框)”与“合成动作数据(训框+姿态)”统一到同一种中间表述上,形成“像 CoT 一样的中间推理”。 - PAG(逐步动作生成)桥接两种数据(中)
把“框 →(对合成数据还包含)抓取位姿”当作动作生成的中间步骤: 互联网数据:只到框(对齐语义、学定位/指令理解); 合成动作数据:到框 + 抓取位姿(补上几何/三维感知)。 两类数据由同一 VLM 接口承接,共享提示模板与训练格式,自然打通“语义到动作”的通道。 - Action Expert(右)— 基于 Flow Matching 的动作解码
在 VLM 的键值缓存与中间推理 token条件下,按段生成末端执行器动作(action chunk),并把最近两帧本体感知(proprioception)编码成 token 供解码器使用;这样能闭环地、更短路径地完成抓取。
Ensuring Force Safety in Vision-Guided Robotic Manipulation via Implicit Tactile Calibration
作者:Lai Wei, Jiahua Ma, Yibo Hu, Ruimao Zhang
内容简介:开门等受约束的操作里,力安全比单纯“能开”更关键;太大的侧向/法向力会伤门也伤机器人。作者提出 SafeDiff:先用视觉生成未来状态序列,再用实时触觉反馈“隐式校准”这些状态,使其满足门的物理约束(沿铰链圆弧)。本质是把触觉当“偏差修正信号”,让状态规划在线收敛到安全轨迹。他们还构建了大规模门操作数据集与一套安全评测指标,证明方法在仿真与真实都明显降低“有害力”。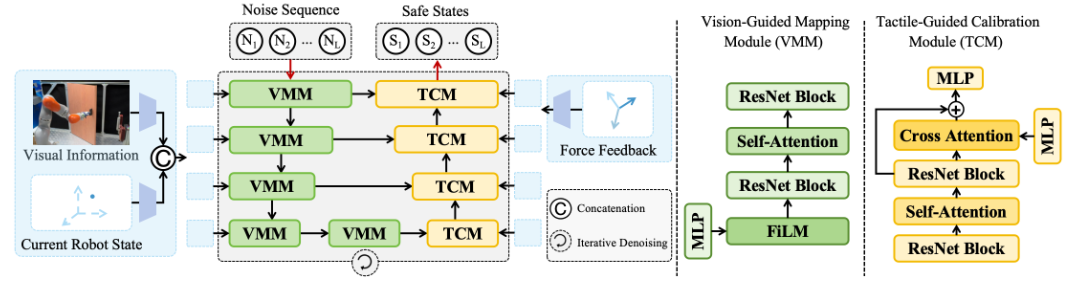
如上原文Figure 2 展示了 SafeDiff 的核心闭环——视觉定大势,触觉做校准,把生成的未来状态序列不断拉回“安全弧线”,从源头上降低开门过程中的有害侧向力。具体地,
- 输入与输出
输入是一段“噪声序列”,再结合场景视觉(相机图像提取的上下文)与当前机器人状态,经过若干次迭代去噪,直接产出未来的一串机器人末端状态(而不是动作命令)。之所以“生成状态而非动作”,是因为开门的安全与否更直接取决于末端状态是否沿着门的圆弧轨迹走。 - 编码器:VMM(Vision-Guided Mapping Module)
多尺度堆叠的 VMM 先把图像+当前状态映射成“初始状态表示”。图里可以看到:视觉信息通过条件化层(类似 FiLM)“调制”噪声序列,再配合自注意力+残差块保证时间上的连贯性;多尺度设计像 U-Net 的下采样路径,逐步压缩序列长度、提升特征维度,用来刻画不同时间尺度的门几何与相对位姿。 - 解码器:TCM(Tactile-Guided Calibration Module)
TCM 在上采样路径中注入触觉(力)信号,把前面的“视觉引导状态”校准为更安全的状态:先用自注意力和残差块强化时间一致性,再用交叉注意力让“当前的力反馈”对应到“未来状态的微调量”,相当于把触觉当成“增益型负反馈”,不断把轨迹拉回门的约束弧线上。图中还画出编码器—解码器的短接,保证细节不过度丢失。
ICRA 2025
𝒟(R,O) Grasp: A Unified Representation of Robot and Object Interaction for Cross-Embodiment Dexterous Grasping
作者:Zhenyu Wei, Yiyang Liu, Xuanlin Li, Yuzhe Qin, Gao Huang, Lin Shao
内容简介:这篇工作把“机器人手型 R、物体 O、以及两者的交互关系 D”统一到一个连续表示里,从而把“抓取”看成一个跨平台可转移的映射问题。直觉上,先学会一种手—物统一坐标系的表达,再用它把不同手(Shadow/Allegro/仿人手)的抓取互相迁移。相比只在单设备上训练的做法,这种表示天然具备跨手型、跨关节数的一致性。方法上以扩散/生成范式预测抓取配置,并辅以约束保证可落地执行。价值在于:同一模型“一次学习,多手通用”,极大减少为每只手单独收集与调参的成本。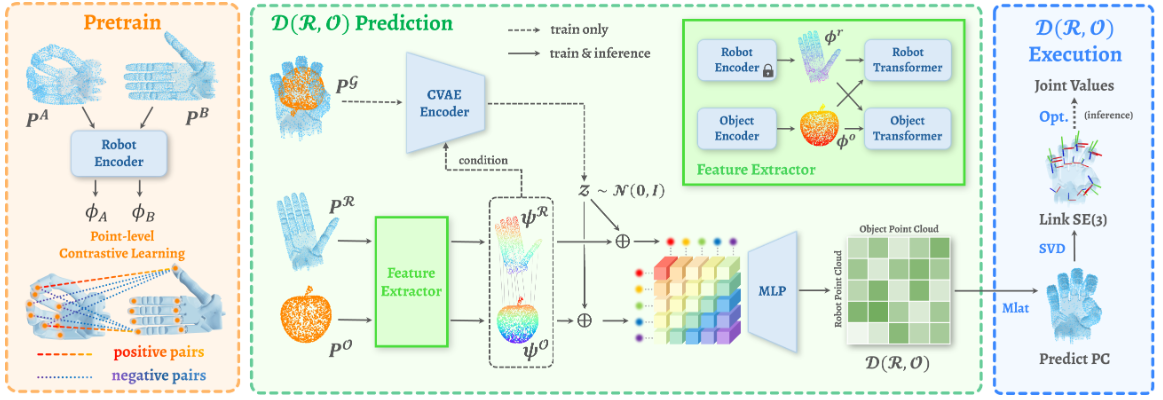
如上原文Figure 2展示了 D(R,O) 的核心思路——用“手—物距离矩阵”这一个交互式表示,把多手型、多物体的灵巧抓取统一到同一套可微、可解、可部署的管线上。。它最完整地体现了“以交互为中心(interaction-centric)的统一抓取表示”,以及由此带来的跨手型泛化、速度和稳定性。具体地,
- (a) 预训练:Configuration-Invariant Robot Encoder
用对比学习对“同一只手在不同关节构型”的点云做一一对齐,让同一物理部位在特征空间保持一致。这样一来,后续不管手指张开/并拢、腕姿怎么变,编码器都能输出对构型变化不敏感的手部特征,为跨手型与多样抓取打底。 - (b) 表示学习:预测 D(R,O)
输入开放态手部点云与物体点云,经双塔点云编码 + 跨注意力建立“手—物”对应关系;再用 CVAE 引入潜变量,输出一个矩阵 D(R,O),其每个元素是“该手部点与该物体点在目标抓取姿态下的相对距离”。这个交互式表示同时“看见”了手的关节结构和物体几何,比“只看手”或“只看物”的表示更能泛化到新手型/新物体,并天然支持多样抓取(采样不同潜变量)。 - (c) 解析与执行:由 D(R,O) 得到关节解
先把 D(R,O) 当作“多点测距”,直接重建目标抓取姿态下的整手点云;再对每个手部连杆做刚体配准拿到各自的 6D 姿态,最后做一个受约束的小步优化求出关节角(带关节限位),通常小于 1 秒即可收敛。相比“先预测接触/关键点再解 IK”的做法,这条链路更直、也更稳。
Variable-Friction In-Hand Manipulation for Arbitrary Objects via Diffusion-Based Imitation Learning
作者:Qiyang Yan, Zihan Ding, Xin Zhou, Adam J. Spiers
内容简介:他们不用复杂多指手,而是用可变摩擦双指做“滑/滚”协同,把灵巧性“外包”给材料与接触模式切换。传统方法要为每个物体手工设定“滚到哪个面”“何时转向”等规则,泛化差。本文改为扩散式模仿学习 + 仿真与真实联合共训:少量实演示 + 大量仿真就能学到任意物体→任意目标位姿的精细 in-hand 运动。核心直觉:把难的接触动力学交给数据分布,而不是写死规则;再用“摩擦态切换”使控制动作变得低维而稳定。价值:2 小时训练 + 1 小时采数就能达到 mm/° 级精度,覆盖非规则物体。
如上原文Fig. 4展示了用扩散模仿学习 + 仿真/真实共训把“简单硬件(变摩擦两指手)”推到“任意形状、任意目标位姿”的核心诀窍;它解释了为何不需要逐物体奖励工程,却仍能在真实机上取得稳健效果(如文中平均成功率71.3%等实证结果所示)。具体地,
- 上左侧:数据来源(演示生成)
在仿真与真实平台上,先用一个“平滑性优先”的RL策略跑出物体在两指变摩擦手中的顺畅轨迹;再用后见目标重标注(HER)把每段轨迹的最终位姿当作目标,直接当“专家演示”。这样无需为每个物体精细设计奖励,也不受多边形/非多边形或目标接触面的限制。图中此块输出两路演示集:仿真演示 D_sim 与真实演示 D_real。 - 上右侧:策略学习(扩散模仿学习,Co-Training)
将 D_sim 与 D_real混合采样,训练扩散策略(Diffusion Policy)来近似条件分布 p(a∣o)。目标函数即扩散损失,对动作进行噪声添加/去噪的DDPM训练;等概率采样仿真与真实数据,显式缩小Sim2Real差距,同时降低对真实数据量的依赖。 - 下侧:部署与执行(VF手混合动作空间)
学到的策略在变摩擦两指手上执行:离散动作负责旋/滑与摩擦模式切换(6种原语),连续动作给出主动手指的相对角度增量;二者交替,兼顾稳定与效率。借此,实现任意形状物体 → 任意目标位姿的连续域操控。
DROP: Dexterous Reorientation via Online Planning
作者:Albert H. Li, Preston Culbertson, Vince Kurtz, Aaron D. Ames
内容简介:主张在线采样式规划(SPC)也能把 in-hand 方块连贯重定向到目标姿态,而不必训练一个超大规模离线 RL 策略。系统由关键点视觉估计 + 采样预测控制器组成,实时并行滚动前瞻、选优控制。直觉:既然接触模式多变,那就实时“试算很多条短视窗策略”,选代价最低的那条,而不是预先学“所有可能”。他们证明在实体手上也能做到与强 RL 基线相当的表现。价值:改目标/改模型无需再训练,工程运维成本更低。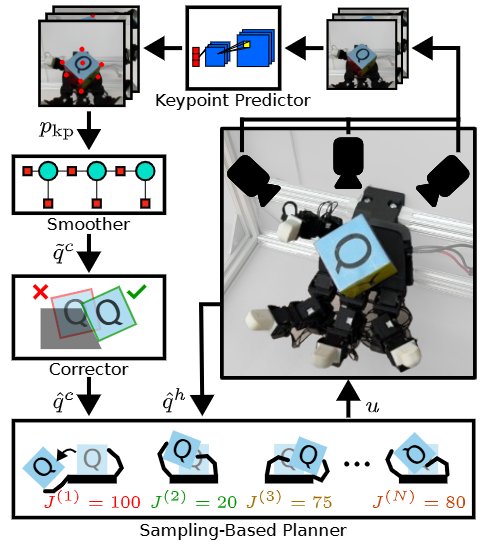
如上原文Fig. 1 展示了多相机感知 → 关键点 → 平滑 → 物理校正 → 并行仿真评估多套动作 → 按评分更新采样并输出当前动作 → 循环执行。具体地,
1) 视觉姿态估计链
多相机图像先由关键点预测器找出立方体角点,再交给平滑器做时间上的稳态融合,最后通过物理一致的校正器避免手与物体“穿模”等不合理姿态;得到的平滑、可信的立方体姿态会喂给规划器使用。这个“三段式”估计器是系统稳定性的地基。
2) 采样式在线规划器
以“当前估计的系统状态”为起点,规划器并行生成一批候选动作方案,在仿真里短时间向前“滚动”预测它们的表现,计算每个方案的“好坏”分数,再在线调整下一轮的采样分布,并输出此刻要执行的动作。如此循环,边评估边更新,实现持续在线决策。实现上,作者采用了标准的并行仿真与两种常见的采样更新策略(PS、CEM),便于落地与对比。
3) 任务目标与评价侧重点
规划器在评分候选方案时,同时考虑两件事:尽快把立方体转到目标姿态、尽量不让立方体离开“安全区域”以避免跌落。作者在实验里特意把“防跌落”的权重调高,换取更稳的真实机表现。
GAGrasp: Geometric Algebra Diffusion for Dexterous Grasping
作者:Tao Zhong, Christine Allen-Blanchette
内容简介:抓取的核心对称性是 SE(3):物体怎么旋转/平移,抓取分布应“相应地等变”。本文用几何代数(Geometric Algebra, GA)把物体点云与手姿态嵌入统一代数空间,再配合等变注意力模块 + 条件扩散直接在这个空间里采样抓取。与常规“靠数据增强学等变”的方式不同,这里把等变性刻进模型结构,因此数据与参数效率更高。再叠加一个可微物理引导,让生成的抓取更符约束、更稳。价值:对“未见过姿态/朝向”的泛化更强。
如上原文Fig. 2 将几何代数表示(保证 SE(3) 等变)+ 扩散式抓取生成 + 高效的几何注意力编码——放进一条数据流。具体地,
- 输入与嵌入:点云 O(物体观测)与当前的抓取状态 g_t 被一起嵌入到几何代数 G_3,0,1 的多向量表示中。用 GA 表示的好处是:旋转/平移等 SE(3) 变换在表示空间里“天然可算”,为后续网络显式编码等变性打下基础。
- 等变编码(GATr Blocks):主体由多层 GATr(Geometric Algebra Transformer)模块构成:等变线性层、几何双线性单元(把几何乘积与“并(join)”运算合成特征)、以及几何代数版注意力(Query/Key/Value 都是多向量),并配上等变的 LayerNorm 与门控 GELU。这些算子在 SE(3) 作用下保持预测的一致性,是“任意姿态泛化”的关键。
- 降采样与跨注意力:为提效,网络对点云做 FPS + kNN 池化 的降采样;随后用跨注意力把“抓取状态 + 时间步 t”与“点云特征”对齐,产出对g_t 的更新,得到下一步 g_t-1。这与扩散去噪的“逐步细化”过程对应。
- 输出:重复若干步,从噪声态一路去噪到可执行的多指抓取候选;还在去噪过程中接入物理可微的引导/微调,让生成更稳定、更贴合真实接触物理。
Visuo-Tactile Object Pose Estimation for a Multi-Finger Robot Hand with Low-Resolution In-Hand Tactile Sensing
作者:Lukas Mack, Felix Grüninger, Benjamin A. Richardson, Regine Lendway, Katherine J. Kuchenbecker, Joerg Stueckler
内容简介:抓在手里的物体经常被手自身遮挡,单靠相机位姿估计不稳。这篇把低分辨率“触觉接触开关”阵列(每个指节一个二值触点)与视觉、手指关节读数做因子图融合:视觉给全局几何,触觉给“哪里真在碰”,编码器给手姿态,三者一起优化出物体 6D 姿态。直觉:粗触觉也有大作用,尤其在强遮挡和噪声时提供“物理一致性”约束。价值:在多指灵巧操作/装配前置环节给出更稳的在线位姿流。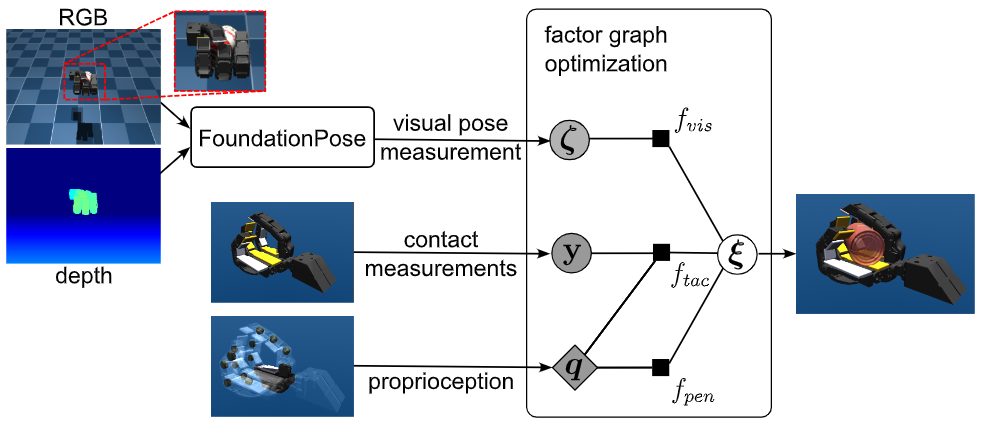
如上原文Fig. 1 展示了在因子图里融合视觉(FoundationPose)、低分辨率触觉接触、与手部关节本体感知,并加入“不可穿透”几何约束来联合估计手中物体位姿。具体地,
- 视觉测量 → 视觉因子 f_vis
外部 RGB-D 摄像头先用 FoundationPose 给出一个“物体位姿测量”(ζ)。图中将它作为视觉因子接入因子图,提供强而快速的外观匹配信号,但会在手部严重遮挡时变得不可靠。 - 手部姿态(关节角)与接触 → 触觉因子 f_tac
多指手每个掌/指骨节内侧贴了低分辨率的软质触觉贴片(每个连杆一块,输出二值“是否接触”)。图中把所有贴片的接触读数 y 与手的关节配置 q 一起送入触觉因子:一旦某贴片“报接触”,优化器就把该贴片表面上的最近点与物体表面对齐,从而把“遮挡下视觉看不见的接触信息”变成位姿约束。 - 几何一致性 → 穿透惩罚因子f_pen
图中还接入了“不可穿透”约束:若当前物体位姿与手部几何发生相互穿透,因子会给出强惩罚,把解往几何上更可信的方向拉回。 - 因子图优化器(中心圆框) → 目标:物体位姿 ξ
上述三类信息被统一到因子图里,对“物体位姿 ξ”做实时优化:视觉提供全局对齐,触觉提供局部接触约束,穿透项提供物理可行性。论文使用鲁棒损失下的非线性最小二乘(LM)实现,抗掉“视觉被遮挡”或“触觉误触发”的离群值。图的右侧即为输出:当前时刻的物体 6D 位姿,实测可达约 13.3 Hz 的在线更新。
ViViDex: Learning Vision-based Dexterous Manipulation from Human Videos
作者:Zerui Chen, Jing Xu, Guangyao Zhai, Qifeng Chen, Masayoshi Tomizuka
内容简介:不依赖动作示例或手套,直接从人类视频里学灵巧操作。做法是把视频解析成潜在中间表征(手—物互动关键帧/接触事件/指尖轨迹等),再蒸馏成多指手的视觉策略;跨域对齐靠表征学习与模仿损失,而不是人工对齐骨骼。直觉:先学“人是怎么摸和推的”,再把这种操作语法转译到机器人。价值:大幅降低数据采集门槛,能快速覆盖多样日常灵巧任务。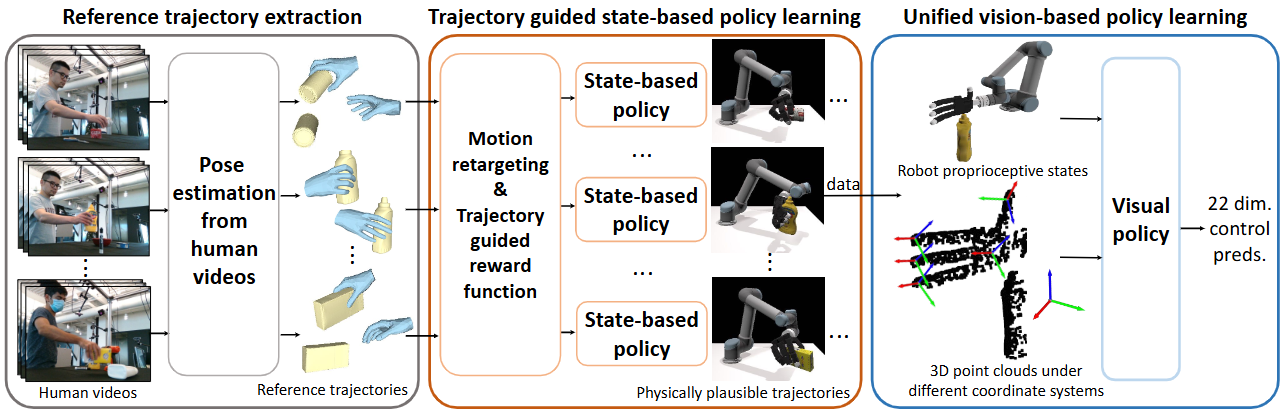
如上原图Fig. 1 展示了先把“人类看起来自然”的动作修到“机器人真能做”,再把“真能做”的经验教给只看视觉的统一策略。具体地,
- ① 从人类视频得到“参考轨迹”
先做手-物体姿态估计与动作重定向,把人手动作迁移到机器人手上,得到“看起来自然但未必物理可行”的参考轨迹。这些轨迹是“人类示范的直觉模板”。 - ② 轨迹引导的状态策略(RL)
针对每段参考轨迹,作者设计了两阶段的奖励:预抓取阶段学“像人那样接近”;操作阶段同时约束手的运动与物体的期望运动/接触/抬起,并在训练中做初始化与目标的轨迹增强,把“看起来自然”的参考,优化成物理上能成功的执行轨迹。这一步输出大量成功的、可执行的“样本剧本”。 - ③ 统一视觉策略(BC 或 3D 扩散策略)
用②滚出的成功剧本来训练“只看传感器”的视觉策略:输入3D点云+机器人本体状态,不再依赖特权的物体真值;为让策略“更懂目标与交互”,图中引入了坐标系变换——把点云同时投影到目标坐标系与手掌/指尖坐标系,显式曝露“去向哪儿、手与物体怎么接触”的线索。策略输出高维控制(图中示例为“22维控制量”)。
DexMimicGen: Automated Data Generation for Bimanual Dexterous Manipulation via Imitation Learning
作者:Zhenyu Jiang, Yuqi Xie, Kevin Lin, Zhenjia Xu, Weikang Wan, Ajay Mandlekar, Linxi “Jim” Fan, Yuke Zhu
内容简介:面对“双手灵巧”数据昂贵的问题,本文用自动化模仿生成从少量人示教扩增到2 万+ 演示,涵盖 9 类任务、跨多仿真器与真实机器人。方法核心是Real→Sim→Real:把人演示结构化成可生成的任务阶段/接触模板,仿真里大量合成,再回到现实做轻量修正。直觉上是“把人类演示的操作语法参数化,然后批量造数据”。价值:极大降低双手灵巧数据成本,并且用简单 BC 就能拿到很高成功率。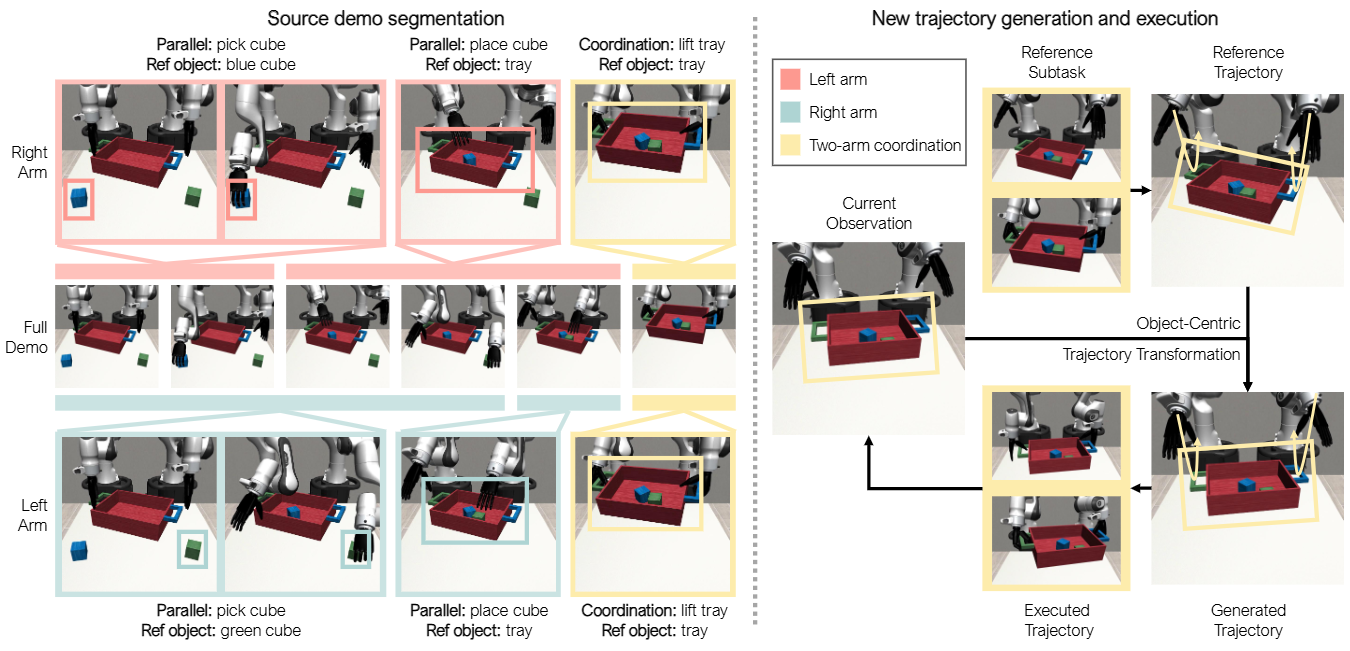
如上原文figure. 3 按手臂分别分段的示范、对象坐标系上的轨迹变换与回放、并行异步执行 + 同步协作、以及成功过滤——在一条可复用的数据生成→执行闭环里完整呈现。具体地,
- 左侧:按手臂的源示范分段与标注
将人类遥操作得到的源示范,分别对左臂/右臂做对象中心(object-centric)的子任务分段,并记录每段的参考对象位姿;需要两臂配合的段落会被标注为“协调(coordination)子任务”,以便后续执行时对齐。 - 右侧:在新场景中“生成并执行”
读取当前场景里参考对象的姿态,将源段落在对象坐标系下做SE(3)变换后得到生成轨迹,并在仿真中执行: 并行异步:两条“手臂动作队列”各自推进,互不强制对齐; 协同同步:遇到协调子任务时,两臂采用同一变换并在执行中互相等待,对齐到同一结束时间步; 手指动作:抓手/手指关节直接回放源示范中的动作; 成功过滤:仅当整个任务达成预设成功条件时,才把该次回放保留为训练样本。
MuST: Multi-Head Skill Transformer for Long-Horizon Dexterous Manipulation with Skill Progress
作者:Kai Gao, Fan Wang, Erica Aduh, Dylan Randle, Jane Shi
内容简介:把长任务拆成多种技能原语(skills),再用 Transformer 做多头并行技能建模与“进度值”调度。直觉是:在灵巧装箱/摆放等任务里,机器人要“会切换、会续接”,而不是一条端到端大网络。MuST 用“进度”表示每个技能执行到哪一段,从而稳妥衔接复杂序列。价值:可扩展到新的技能库、适应任务顺序变化。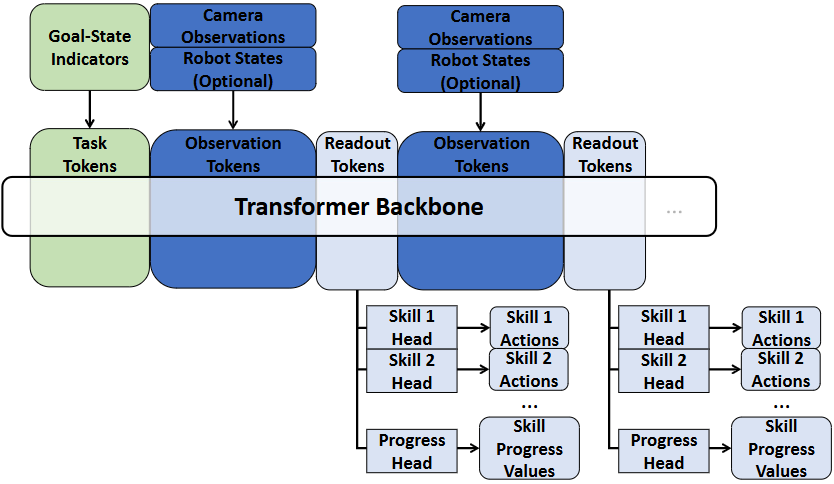
如上原文Fig. 2 把“可复用的技能库”与“可度量的执行进度”结合进同一策略框架,用进度来串联/切换技能,成为长时序灵巧操作的核心。用同一骨干网络并行学习多种“技能”、为每个技能实时估计“进度”、以及用进度来选择下一步要执行的技能(ProGSS)。具体地,
- 输入与骨干(Octo 预训练 Transformer):多模态观测(相机、机器人状态,可选“目标图像/语言指示”)被分词后送入预训练的 Octo 骨干;Readout Token融合多模态信息,作为后续各个“头”的统一表征。
- 多技能动作头(N 个):每个技能各有一个“动作头”,直接从 Readout 表征解码该技能的动作(位姿 + 吸取开关等);这样把长任务拆成可复用的技能,降低单一策略直接覆盖全流程的难度。
- 进度头 + 技能选择(ProGSS):独立的“进度头”同时输出每个技能的进度值(0–1);根据进度与终止阈值,ProGSS 在当前时刻选择该执行的技能。这解决了长流程里“何时切换/跳过/重试某技能”的歧义问题,也让系统能对扰动做出合理反应(如进度不达标就重做)。
- 执行闭环:被选中的技能输出一段动作,执行后再次观测→更新进度→再选技能,直到所有技能完成或任务失败。同一骨干 + 多头的设计也让并行学习、按需扩展新技能变得直接(新增一个动作头 + 扩一维进度向量即可)。
IROS 2025
ORCA: An Open-Source, Reliable, Cost-Effective, Anthropomorphic Robotic Hand for Uninterrupted Dexterous Task Learning
作者:Clemens C. Christoph, Maximilian Eberlein, Filippos Katsimalis, Arturo Roberti, Aristotelis Sympetheros, Michel R. Vogt, Davide Liconti, Chenyu Yang, Barnabas Gavin Cangan, Ronan J. Hinchet, Robert K. Katzschmann
内容简介:这篇工作聚焦“灵巧手硬件门槛太高”的痛点:贵、复杂、难维护,导致真实世界灵巧操作研究推进缓慢。ORCA 手把关键点做“减法”:17-DoF 腱驱+自张紧/自校准结构+可“弹起”的关节,减少维护成本并提升可靠性。它集成触觉传感,强调“开箱即用、一天内装好”,让研究团队能快速开展遥操作、模仿学习、以及零样本的仿真到现实强化学习。作者用长时无故障循环与多任务基准证明耐用性与可用性。价值直观:把“灵巧手=烧钱+工程负担”改造成“灵巧手=可复制、可承载学习闭环”的平台。
如上原文Fig. 1 展示了:低成本、易装配的人手型结构(A),可连续数小时不间断地跑模仿学习任务(B),以及经受长时间循环的稳定性与重复性(C)。具体地,
(A) 人手形态 + 抗过载的“可弹出”销轴关节 + 快速张紧的棘轮线轴
A1/A2 展示了poppable pin joints:轴承坐在弧形槽里,正常工作紧固,受过载时优先“弹出”而不是折断,既保留了销轴关节稳定与易建模的好处,又具备抗冲击、易维护的鲁棒性。A3 则是棘轮式线轴,徒手就能快速回张力、消松弛,无需拧松线轴,现场维护成本低。整只手3D 打印、集成触觉、材料成本 < 2,000 CHF、单人 < 8 小时装配完,把“入门门槛”和“维护门槛”一起降下来。
(B) 连续 7+ 小时的自复位模仿学习运行
这一帧强调“不中断学习”的真实可用性:作者把手部署在自复位的模仿学习场景中,连续运行 7 小时以上都无需对手部硬件干预,验证了在长期任务中没有明显的疲劳/松弛导致的性能崩塌。这说明 ORCA 不只是“能动起来”,而是能稳定地长时间动起来。
(C) 可靠性与重复性测试(电流/温度长期稳定)
右侧给出2.5 小时的连续抓取与腕部运动循环测试结果:手指与腕部电机的峰值电流与温度在整个实验中保持稳定,期间完成2250+ 次抓取循环与550+ 次腕部屈伸,无停机、无断裂、无性能明显下滑。论文还在摘要/正文中报告了>10,000 次连续循环(约 20 小时)的耐久结果,进一步支撑“可长跑”的结论。
TypeTele: Releasing Dexterity in Teleoperation by Dexterous Manipulation Types
作者:Yuhao Lin, Yi-Lin Wei, Haoran Liao, Mu Lin, Chengyi Xing, Hao Li, Dandan Zhang, Mark Cutkosky, Wei-Shi Zheng
内容简介:传统灵巧手遥操作常“追随人手”,但人手的生物力学限制会“锁死”机器手更高的可操作空间。TypeTele 的直觉很大胆:别再强行一一模仿人手姿态,而是引入“操控类型(manipulation types)”的中间层,让操作者选取/切换更适合任务的手型与接触模式。这样,机器手可以做“人手做不到但机器手结构能做”的动作——例如不寻常的指尖滑动/滚动、超范围的对指等。系统把“类型→动作”映射做了工程化封装,遥操作即刻收益:更稳、更快、更通用。实际实验表明,对多对象、多任务都能更可靠。价值:把遥操作从“跟手姿态”升级为“按类型调用机器手的结构潜能”。
如上原文Fig. 3 把 TypeTele 的“先选类型、再插值控制”的核心哲学完整落地——既释放了灵巧手的结构优势,又避开了人机形态差异的坑。这张图把整套方法的三大支柱“类型库、MLLM 辅助的类型检索、插值映射的类型化控制”连成一条闭环数据流,最直接地呈现了作者用“操控类型”解放灵巧手潜能、突破传统姿态重定向瓶颈的思路。具体地,
- 类型库(Dexterous Manipulation Type Library)
按层级分类覆盖单手/双手、抓取/非抓取与“机器人专属”的特殊姿态;每个类型都配有对象与任务属性(适合的物体、接触部位、形状、方向、意图)以及两帧锚姿态(伸展/收缩),作为后续控制的“动作空间”。这样既能描述“要做什么”,也明确“像什么样”。 - MLLM 辅助的类型检索(Retrieval Process)
给定场景图像+语音/文字命令,系统先让大模型拆分任务步骤,再为每一步的左右手各自选型(如“把手抓锅柄”“拇食指捏扳机”)。检索依据正是类型库里预先标注的那些属性,保证“选到就能用、用得合理”。 - 类型化遥操作(Teleoperation Process with Interpolation Mapping)
一旦确定类型,操作者只需自然地开合手指,系统把人手当前姿态在“伸展↔收缩”两帧锚姿态间做插值,同步映射到机器手的关节空间;遇到多步骤/双手协作,图里示例会分步指定左右手类型并随步骤切换。核心效果是:人手给出意图与幅度,机器手在该类型可行域内“聪明地完成细节”。
Hierarchical Reinforcement Learning for Articulated Tool Manipulation with Multifingered Hand
作者:Wei Xu, Yanchao Zhao, Weichao Guo, Xinjun Sheng
内容简介:这篇直面“用镊子/剪刀这类带关节工具”的在手操作难题:工具本身会动,接触力学更复杂,策略极易不稳。作者用层级式 GCRL(目标条件 RL)把问题拆开:低层管“手+工具”的精细协作与构型切换,高层像任务导演,给定工具目标状态并调度手臂达成抓取/操作。这种“高层定目标、低层做细活”的分工,既稳住了接触,又保持策略可泛化。实测显示对不同尺寸与形状目标都能成功夹取,成功率约 70.8%。价值:为“带关节工具”的在手操控给出一条实用的学习路线,可迁移到剪刀、医械等工具。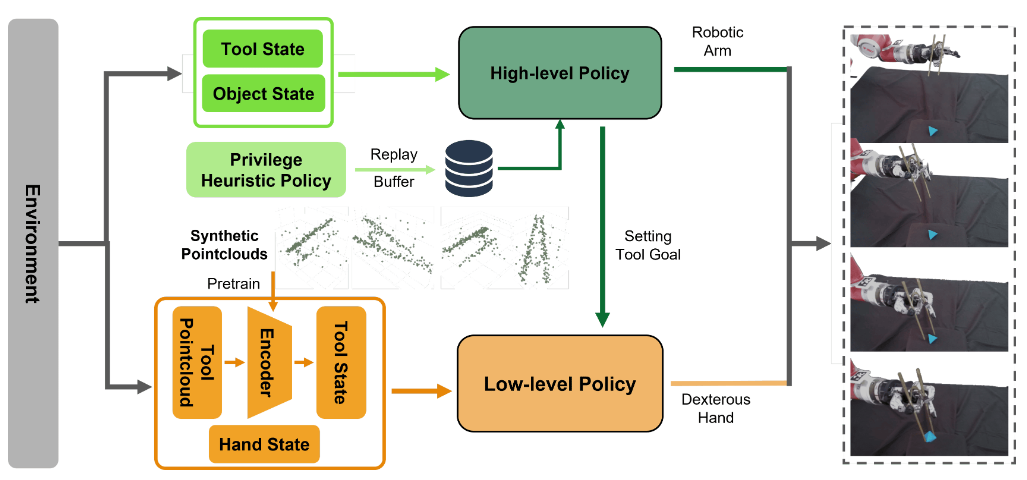
如上原文Fig. 2 展示了:感知→(工具状态编码)→ 低层策略改“形”→ 高层策略定“形”并动“臂” → 完成夹取的过程。具体地,
- 工具状态编码:从点云里把“工具的位姿+形状能力(affordance)”提炼成紧凑表征(含一个低维潜变量表示镊子张开度等),供策略直接用,避免原始点云噪声与遮挡干扰。
- 低层策略(手指改“形”):输入“手的关节状态 + 工具状态 + 目标形状”,学会只靠多指配合去稳定地调整工具形状(比如精确控制镊子开合),尽量少移动工具整体姿态。
- 高层策略(定“形”+动“臂”):输入“工具状态 + 目标物体与放置目标的相对位置”,一边给低层下达下一步的工具目标形状,一边控制机械臂把手/工具送到物体附近,协调手—臂完成夹取与搬运。
Geometric Retargeting: A Principled, Ultrafast Neural Hand Retargeting Algorithm (GeoRT)
作者:Zhao-Heng Yin, Changhao Wang, Luis Pineda, Krishna Bodduluri, Tingfan Wu, Pieter Abbeel, Mustafa Mukadam
内容简介:灵巧手遥操作/模仿学习离不开“手姿态重定向”(从人手关键点到机手关键点)。很多方案要么慢、要么靠大量调参、要么在线优化重、难实时。GeoRT 的直觉是“把几何本质做成目标函数”:保持运动保真、覆盖 C-空间、响应平滑、捏合对应、防自碰撞……统一进一个无测试时优化的神经目标体系里。结果是 1kHz 级的超快映射,少超参,且精度/稳定性兼顾。价值:这是“数据闭环/遥操作/演示采集”的底座能力,速度够快,后端还可以串接通用控制器进行误差修正。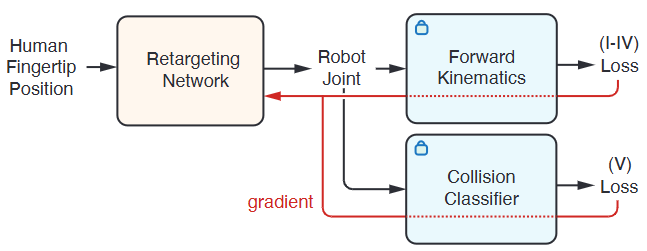
如上原图Fig. 6:用几何原则定义目标 → 通过可微前向运动学把误差量化在指尖空间 → 结合碰撞判别器做无监督训练 → 直接得到1 kHz级的实时重定向模型。把 GeoRT 的“几何即目标、FK 作桥梁、无监督端到端”的训练闭环完整示意——这正是它比传统重定向更快、更稳、更好用的根本原因。具体地,
- 输入与映射:人手指尖位置 → Retargeting Network 输出机器手关节角(每根手指独立 MLP,最后拼成整手关节向量)。
- 可微前向运动学(FK):把关节角再前向运动学到“机器人指尖”坐标系,这样后续所有“几何目标”都能在同一个指尖空间里和人手进行对比、衡量。梯度反向穿过 FK回到网络。
- 几何目标(I–IV)在指尖空间计算: 运动保持:人手微小朝某方向动,机器人指尖方向一致; C-space 覆盖:通过 Chamfer 近似,让机器人指尖的运动范围被充分“填满”; 高平坦性:在不同区域、不同方向的响应灵敏度一致,手感不“忽快忽慢”; 捏合对应:拇指–食指等做人手捏合时,机器人也同步捏合到位。这些损失都在 FK 后的指尖空间里计算,再把梯度传回网络。
- 碰撞约束(V):并行接一个自碰撞分类器(训练好后固定),对会引发自碰的关节配置施加惩罚,鼓励无碰撞的重定向结果;同样把梯度回传到网络参数。
Learning Dexterous In-Hand Manipulation with Multifingered Hands via Visuomotor Diffusion Policies
作者:Piotr Koczy, Michael C. Welle, Danica Kragic
内容简介:本文把扩散策略(Diffusion Policy)搬到“在手操作”的视觉-运动端到端学习场景里。直觉是:扩散模型在复杂接触序列/长时动作生成上更稳健,能更好建模“手-物-手”的微小姿态变化与接触切换。作者通过遥操作/多任务数据,训练从视觉到动作的扩散策略,展示如旋开瓶盖等在手任务的可靠性提升。关键还在鲁棒性:在杂乱视觉与非理想接触下,扩散式生成较少陷入“局部坏姿态”。价值:为“在手操作的端到端学习”提供一条可扩展的策略学习范式。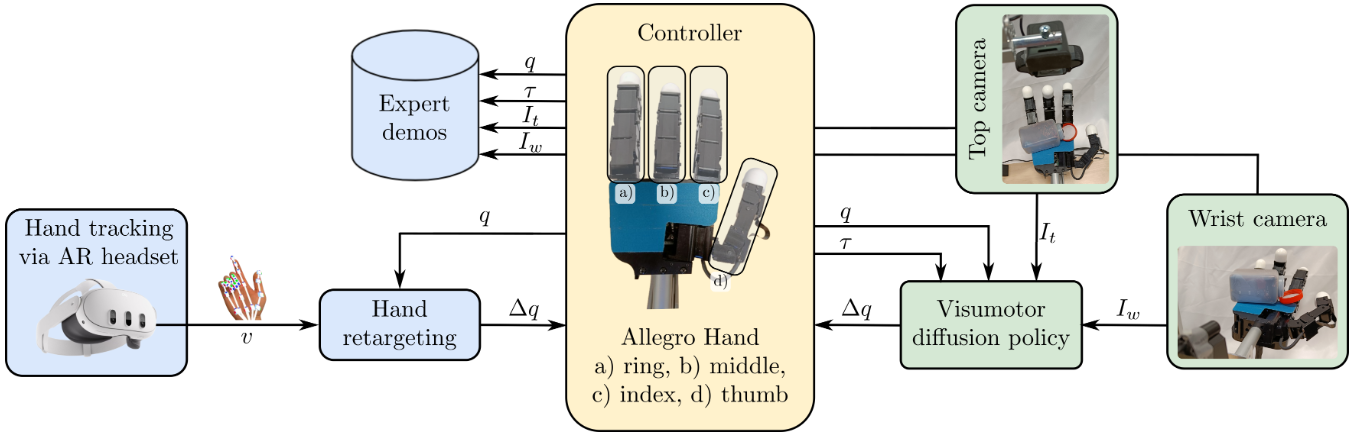
如上原文Fig. 2 :用 AR 头显做高质量遥操作采集 → 经过运动重定向与 IK 得到 Allegro Hand 的关节命令/多模态观测 → 训练并在线执行“视觉—本体感觉条件化”的扩散策略完成单手在手内拧盖。具体地,
- 左侧·遥操作采集:Meta Quest 3 实时手部追踪 → Unity 经 ROS-TCP 发送骨架点位 → “手部重定向节点”做运动重定向 + 逆运动学,输出 Allegro Hand 的增量关节命令 Δq,同时记录 q(关节位置)/ τ(关节力矩或电流)/ 顶视与腕部相机图像(It, Iw),形成示范数据。这个环节确保演示精确、响应快、覆盖多姿态。
- 右侧·自主执行:训练好的视动扩散策略(Visuomotor Diffusion Policy)以 It/Iw,q,τ为条件,闭环地输出下一步 Δq(以动作序列去噪的方式逐步细化),驱动手指配合与物体相对运动,完成在手内稳抓—推移—拧动—松盖的全过程。
- 与数据清洗的连接:示范进入训练前,作者用 HDBSCAN + GLOSH 做无监督离群过滤,去掉质量差的演示,以提升策略稳定性;这一步虽然不在该图显式画出,但与图中的“采集→训练→部署”主链紧密相连。
Beyond Anthropomorphism: Enhancing Grasping and Eliminating a Degree of Freedom by Fusing the Abduction of Digits Four and Five
作者:Simon Fritsch; Liam Achenbach; Riccardo Bianco; …; Robert K. Katzschmann
内容简介:作者反问:“一定要完全仿生才更灵巧吗?”答案是否定的。SABD 把无名指和小指的展收(Abd/Add)融合成一个大行程的联合关节,一边减少一个自由度、一边把“手掌两侧的张开幅度”大幅拉大,能抓更宽、更难夹的物。这像是“少一个电机,换来更实用的抓取工作空间”。实验里它不仅抓大件更稳,还在 RL 测试与远程操控里有更高成功率。直觉上,这是把“形态学增益”用于抓取稳定性与适配性的硬件创新。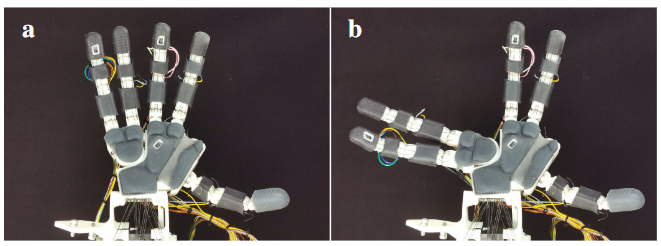
如上原文Fig. 4 :把第4、5指的MCP外展/内收关节合并为一个位于掌部更低、更中线的位置的单轴关节,从而把两指作为“一个整体”去外展,活动范围接近90°,带来非拟人但更有用的抓取姿态。具体地,
- (a) 基本姿态:手在未外展时的基准形态,可视为传统拟人结构的对照。
- (b) 完全外展姿态:合并关节驱动下,第4、5指所在的掌部区域整体旋转,使拇指与第4/5指能在很大横向距离上“正面对抗”。这不是人手常见的姿态,却非常适合大尺寸物体的单手抓,也能为稳定夹持提供更好的几何对置。
设计取舍
- 优点:少一个自由度/电机,腱线更少、潜在故障点更少;关节位置更低、轴更粗,鲁棒性更高;ROM 极大,拓展到非拟人抓取。
- 代价:合并后腱线需穿同一关节,带来额外耦合与摩擦;在全外展极限位时,第4/5指的伸展能力与有效力矩会受影响;控制上需处理分叉运动链。这些都是工程上需要继续优化的方向(如改进腱线走线与加入本体传感)。
In-Hand Manipulation of Articulated Tools with Dexterous Robot Hands with Sim-to-Real Transfer
作者:Soofiyan Atar; Daniel Huang; Florian Richter; Michael Yip
内容简介:抓刚体容易点,在手里操纵“自带机关”的工具(剪刀、钳子、腹腔镜器械)就难多了:关节摩擦/回差/空程、接触耦合等细节很难仿真。作者路线是:先在仿真用“特权观察”学一个强基模型,再蒸馏成可上机的“本体感知策略”,最后引入跨注意力的触觉-力矩自适应模块(CATFA)在真实硬件上微调 —— 一句话:用小量真机数据把“未建模接触细节”在线补齐。结果是对干扰/尺度/几何更稳健,且能泛化到没见过的新工具。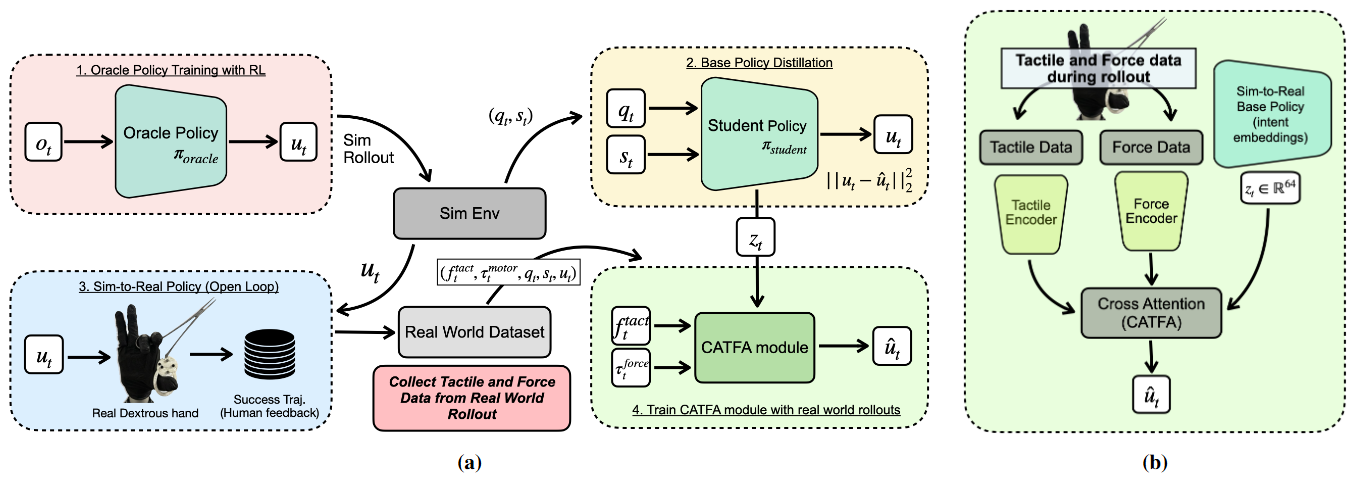
如上原图Fig. 2 :仿真学意图(加扰动)→ 蒸馏出只看本体的基础策略 → 上机用触觉+力经交叉注意力做在线细化与纠偏,稳操各类关节工具。就是模拟中学会“会做什么”→ 蒸馏得到可上机的基础策略 → 用触觉与力矩做跨注意力自适应。具体地,
- (a) Oracle → Student(模拟侧)
先在仿真里用特权观测训练一个“oracle”策略,并加入随机游走的外力/外力矩扰动,让策略在各种干扰下仍能稳定开合剪刀、钳子等带关节的工具。随后把它蒸馏成只看本体感觉(关节状态 + 开/合指令)的基础策略,为上机转移打底。 - (b) CATFA 适配(硬件侧)
在真实手上,冻结基础策略,取其最后一层的“意图嵌入”,与整手触觉“图像”和电机电流换算的关节力各自编码后,经过多头交叉注意力进行融合,输出细化后的关节目标。CATFA 只需少量成功的真实回放(作者报告不足 50 段)做行为克隆,就能学会在硬件上在线纠偏:看触觉/力反馈抑制打滑、稳住接触、调内力、应对工具联动的非理想摩擦/回差。
Adaptac-Dex: Adaptive Visual–Tactile Fusion with Hierarchical Reasoning for Dexterous Manipulation
作者:Jinzhou Li, Tianhao Wu, Jiyao Zhang†, Zeyuan Chen†, Haotian Jin, Mingdong Wu, Yujun Shen, Yaodong Yang, Hao Dong.
内容简介: 机器人做精细操作时既要“看”也要“摸”。但视觉/触觉的信息分布和可靠性在不同阶段不一样:靠近目标时多看,接触后多靠触觉。现有多模态融合常用“简单拼接”或固定权重,容易在关键时刻“用错感官”。 本文提出 AdapTac:用“力”来当注意力的指挥棒。把当前观测到的合力与模型预测的未来合力结合,作为查询去跨模态注意力里动态调配“看/摸”的比重;视觉由稀疏点云编码器提取,触觉由预训练触觉编码器提取,融合后的特征交给 3D 扩散策略做动作生成。无需人工打接触标签,也不假设“视觉永远更重要”。 可能价值? 在三类接触密集的真实任务(开盒、杯子重定向、海绵翻面)上,方法平均成功率 93%,显著优于仅视觉、直拼接、以及基于手工阈值的接触加权基线;对未见过物体也有 75% 的成功率。更重要的是,策略学会了按阶段切换关注:接近时更依赖视觉,接触后提升触觉权重。
如上原文Fig. 2 : “点云/触觉编码 → 预测未来合力 → 以(当前+未来)合力做查询的跨注意力融合 → 扩散策略出动作”。接近多看视觉,触碰多看触觉,全靠力信号自适应切换。具体地,
- 特征提取:
• 触觉 → 预训练触觉编码器得到触觉特征。
• 视觉 → 稀疏体素/点云编码器得到几何特征。 - 未来力预测(c):用一个“未来合力预测头”(扩散式)同时看视觉与触觉特征,预测接下来若干步的净合力,提供“接触将发生什么”的时间上下文。
- 力引导的跨注意力融合(d):把“观测到的当前合力 + 预测到的未来合力”拼接,作为查询;视觉/触觉特征作为键值进入注意力,输出自适应加权的融合表征。直觉上:即将接触或接触剧烈变化时,注意力会自动更看重触觉。
- 动作生成(e):融合后的动作特征作为条件,送入3D 扩散策略头,预测接下来的位移、姿态与手部关节目标。整条链路一起在模仿学习框架下训练(策略损失 + 未来力预测辅助损失)。
SimLauncher: Launching Dexterous Hand Manipulation Policies with Model-Based Simulation
作者: Mingdong Wu, Lehong Wu, Yizhuo Wu, Weiyao Huang, Hongwei Fan, Zheyuan Hu, Haoran Geng, Jinzhou Li, Jiahe Ying, Long Yang, Yuanpei Chen, Hao Dong
内容简介: 真实世界里的强化学习很费样本、探索慢、还常常要人手介入(演示/纠错),导致落地成本高、效率低。本文提出 SimLauncher:先在数字孪生里预训练一个视觉策略,再把它用到真实世界的在线RL里,发挥两点作用:① 把模拟回放和小规模真实回放一起当“示范”去启动/约束评论家(critic);② 让预训练策略在交互时提供动作候选,与RL策略的动作用Q值加权/抽样二选一,帮助探索更稳更快。整体采用 RLPD 式混合RL流程、视觉输入(RGB+本体)与10Hz控制。可能价值? 在三类任务(搬放、插入、灵巧抓取)上,对比依赖人工示范的混合RL基线,样本效率显著提升,成功率更高(如当本方法达成100%成功率时,强基线 IBRL 仍落后20–40%);同时表明仅靠模拟示范也能有效“引导起步”,并且扩大模拟示范的状态覆盖还能进一步加速。
如上原文Fig. 2 :“双源示范启动critic + 预训练策略动作提议”与“视角完全基于RGB、可与真实世界无缝接轨”的整体闭环清楚画出,是最能体现核心思想的一张。具体地,
- (I) 模拟端:策略预训练 & 示范采集 先用特权状态在模拟里学一个状态式策略,再把它蒸馏成视觉策略(RGB+本体);同时在数字孪生里大规模采集成功回放(也探讨了“混合示范”,即训练全程均匀抽取轨迹以扩大状态覆盖)。这些模拟示范 D_sim用于后续critic启动。
- (II) 真实端:少量真实示范 把预训练视觉策略直接上机回放,收集少量真实成功轨迹 D_real。训练时等比例采样 D_sim 与 D_real,避免critic过拟合于“纯模拟特征”,并持续把在线成功轨迹加入 D_real,缩小demo与重放缓冲的分布差。
- (III) 在线RL:动作提议 + critic启动(RLPD范式) 与环境交互时,同时计算RL策略动作 a_rl与预训练策略动作 a_bc,按 Boltzmann(Q) 采样二选一执行,既用于动作也用于训练目标的bootstrapping(目标 y 使用两者的最大Q)。每个训练batch按 R: 50% / D_real: 25% / D_sim: 25% 组成,更新 critic 与 actor。整套系统完全视觉驱动,背景掩膜可用 SAM2 初始化+跟踪,满足 10Hz 控制频率。

















 1368
1368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









