






图像分类
·将不同的图像,划分到不同的类别标签,实现最小的分类误差。

图像分类的三层境界
·通用的多类别图像分类
·子类细粒度图像分类
·实例级图片分类
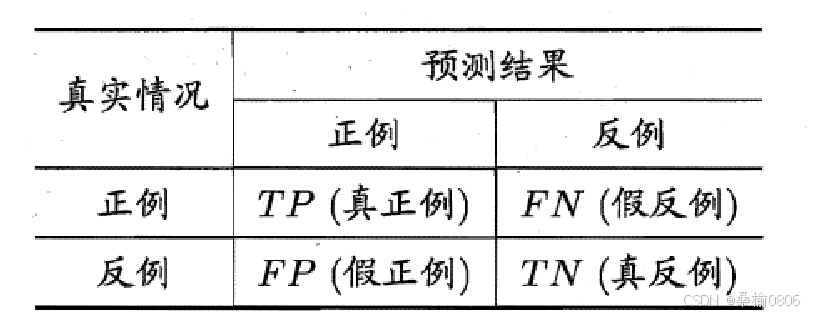
图像分类评估指标之混淆矩阵
TP(True positive,真正例)——将正类预测为正类数。
FP(False positive,假正例)——将反类预测为正类数。
TN(True negative,真反例)——将反类预测为反类数。
FN(False negative,假反例)——将正类预测为反类数。
图像分类评估指标
精确率(Accuracy):精确率是最常用的分类性能指标。可以用来表示模型的精度,即模型识别正确的个数/样本的总个数。一般情况下,模型的精度越高,说明模型的效果越好。
Accuracy = (TP + TN) / (TP + FN + FP + TN)
准确率(Precision):又称为查准率,表示在模型识别为正类的样本中,真正为正类的样本所占的比例。
Precision = TP / (TP + FP)
召回率(Recall):又称为查全率,表示模型正确识别出为正类的样本的数量占总的正类样本数量的比值。
Recall = TP / (TP + FN)
F1_Score:它被定义为正确率和召回率的调和平均数。
F1 = (2 × P × R) / (P + R)
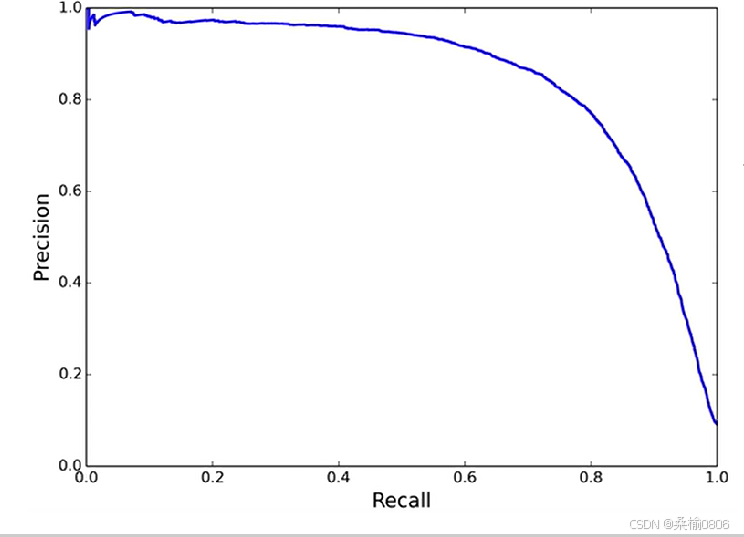
P - R曲线:
·召回率增加,精度下降。
·曲线和坐标轴面积越大,模型越好。
·对正负样本不均衡敏感。
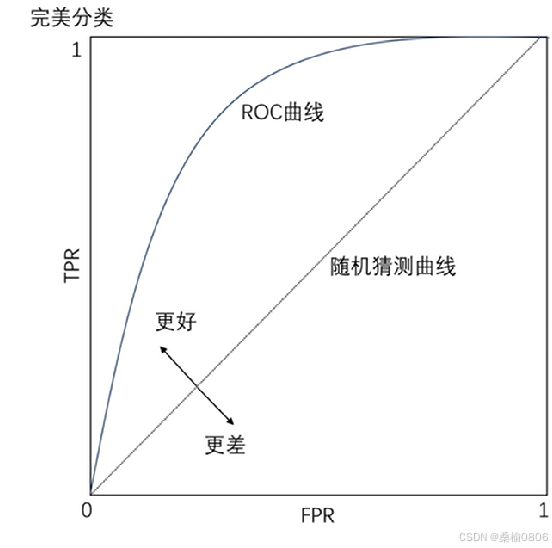
横坐标false positive rate(FPR):
FPR = FP / (FP + TN)
正类中实际负实例占所有负实例的比例。
纵坐标true positive rate(TPR):
TPR = TP / (TP + FN)
正类中实际正实例占所有正实例的比例。
正负样本的分布变化,ROC曲线保持不变,
对正负样本不均衡问题不敏感。
多类别分类模型各个类别之间的分类情况
被分类类别为第i类的数量,矩阵元素Cij表示第i类样本被分类类别为第j类的数量。
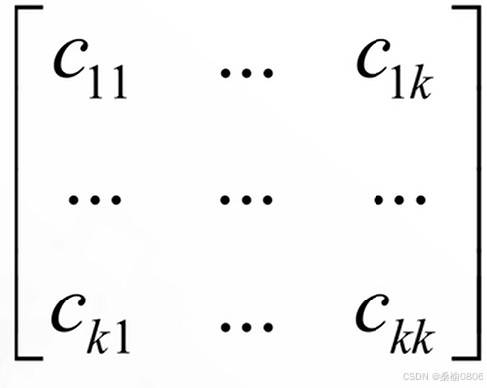
主对角线的元素之和为正确分类的样本数量,其余元素的值为错误分类的样本数量,其余元素的值越大,分类器准确率越高。
模型基本概念 - 网络的深度
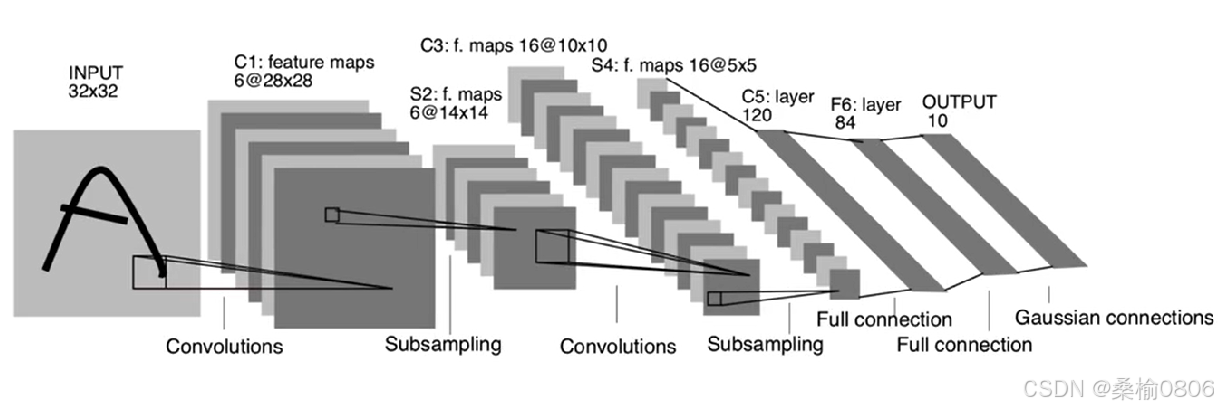
·深度学习最重要的属性,计算最长路径的卷积层+全连接层数量。LeNet网络,C1+C3+C5+F6+Output共5层。
·每一个网络层的通道数,以卷积网络层计算。
LeNet网络,C1(6),C3(16)。
图像分类中样本量过少的问题
·样本量极少:样本获取较难导致总体样本量过少。
样本量过少的解决方案1
·迁移学习:使用预训练模型。
ImageNet数据集具有通用性,使用它进行预训练可加速模型收敛。
样本量过少的解决方案2
·数据增强(有监督方法与无监督方法)
有监督方法:平移、旋转、亮度、对比度、裁剪、缩放等。

无监督方法:通过GAN网络生成所需样本,然后再进行训练。


















 1702
1702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









