







 本文详细介绍Python中numpy库的random函数,包括rand、randn、randint、random和uniform等,用于生成不同分布的随机数,适用于数据处理和科学计算。
本文详细介绍Python中numpy库的random函数,包括rand、randn、randint、random和uniform等,用于生成不同分布的随机数,适用于数据处理和科学计算。
在使用Python进行数据处理时,往往需要用到大量的随机数据,那如何构造这么多数据呢?Python的第三方库numpy库中提供了random函数来实现这个功能。
本文将根据官方文档以及其他博友的博客一起来谈论常见的random函数以及使用
首先说下numpy.random.seed()与numpy.random.RandomState()这两个在数据处理中比较常用的函数,两者实现的作用是一样的,都是使每次随机生成数一样,具体可见下图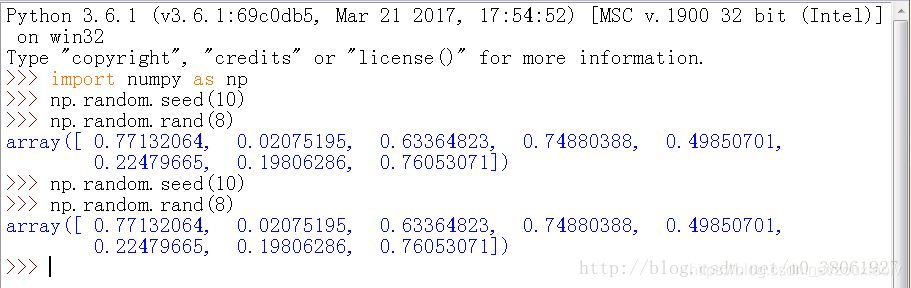
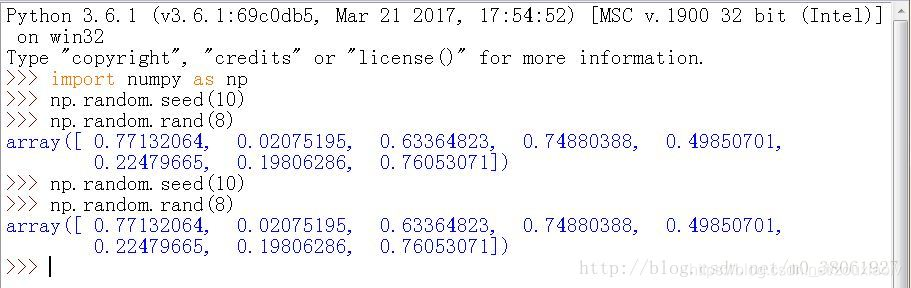
1.numpy.random.rand()
官方文档中给出的用法是:numpy.random.rand(d0,d1,…dn)
以给定的形状创建一个数组,并在数组中加入在[0,1]之间均匀分布的随机样本。
用法及实现:
2.numpy.random.randn()
官方文档中给出的用法是:numpy.random.rand(d0,d1,…dn)
以给定的形状创建一个数组,数组元素来符合标准正态分布N(0,1)
若要获得一般正态分布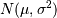 这里写图片描述则可用sigma * np.random.randn(…) + mu进行表示
这里写图片描述则可用sigma * np.random.randn(…) + mu进行表示
用法及实现: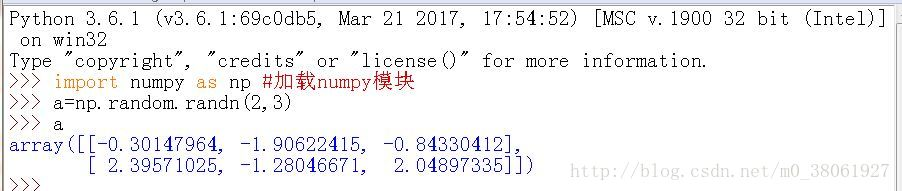
3.numpy.random.randint()
官方文档中给出的用法是:numpy.random.randint(low,high=None,size=None,dtype)
生成在半开半闭区间[low,high)上离散均匀分布的整数值;若high=None,则取值区间变为[0,low)
用法及实现
high=None的情形
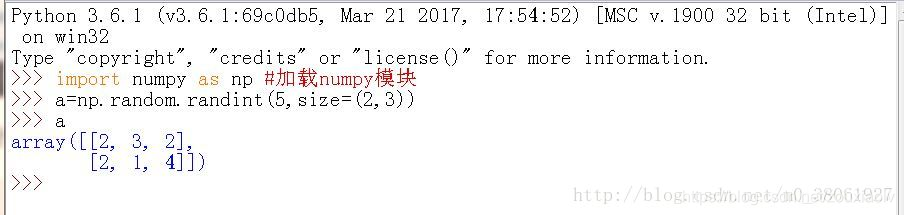
high≠None

4.np.random.random()函数参数
np.random.random((1000, 20))
上面这个就代表一千个浮点数,从0-20中随机
5.numpy.random.uniform介绍:
函数原型: numpy.random.uniform(low,high,size)
功能:从一个均匀分布[low,high)中随机采样,注意定义域是左闭右开,即包含low,不包含high.
参数介绍:
low: 采样下界,float类型,默认值为0;
high: 采样上界,float类型,默认值为1;
size: 输出样本数目,为int或元组(tuple)类型,例如,size=(m,n,k), 则输出m*n*k个样本,缺省时输出1个值。
返回值:ndarray类型,其形状和参数size中描述一致。
这里顺便说下ndarray类型,表示一个N维数组对象,其有一个shape(表维度大小)和dtype(说明数组数据类型的对象),使用zeros和ones函数可以创建数据全0或全1的数组,原型:
numpy.ones(shape,dtype=None,order='C'),
其中,shape表数组形状(m*n),dtype表类型,order表是以C还是fortran形式存放数据。

















 3037
3037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









