







25年3月来自哥伦比亚大学和UIUC的论文“PhysTwin: Physics-Informed Reconstruction and Simulation of Deformable Objects from Videos”。
创建现实世界物体的物理数字孪生体在机器人、内容创作和扩展现实(XR)领域具有巨大的潜力。本文提出一种名为 PhysTwin 的框架,它利用动态物体交互的稀疏视频,生成照片级真实且物理上逼真的实时交互式虚拟模型。该方法主要包含两个关键组件:(1)基于物理信息的表示方法,该方法结合弹簧-质量模型(用于逼真的物理模拟)、生成形状模型(用于几何建模)和高斯溅射(用于渲染);(2)一种多阶段、基于优化的逆向建模框架,该框架能够从视频中重建完整的几何形状、推断密集的物理属性并复现逼真的外观。其方法将逆向物理框架与视觉感知线索相结合,即使在视角不完整、被遮挡或受限的情况下,也能实现高保真度的重建。 PhysTwin支持对各种可变形体进行建模,包括绳索、毛绒玩具、布料和快递包裹。实验表明,在重建、渲染、未来预测和新型交互仿真方面,PhysTwin的性能优于其他同类方法。
构建交互式数字孪生对于建模世界和模拟未来状态至关重要,其应用领域涵盖虚拟现实、增强现实和机器人操控。一个物理上逼真的数字孪生(PhysTwin)应能精确捕捉物体的几何形状、外观和物理属性,从而实现与现实世界观测结果高度吻合的模拟。然而,如何从稀疏的观测数据中构建这样的表示仍然是一个巨大的挑战。
为可变形体创建数字孪生一直是视觉领域的一个难题。虽然动态 3D 方法(例如,动态 NeRF [2, 5, 8, 13, 14, 17, 27, 29–31, 39–41, 43, 55, 56, 58, 61]、动态 3D 高斯函数 [10, 20, 24, 33, 34, 59, 65, 66, 68])能够从视频中捕捉到观察的运动、外观和几何形状,但它们忽略底层物理特性,因此不适合模拟未见交互的结果。尽管近期基于神经网络的模型[4, 11, 28, 32, 36, 42, 49, 51, 52, 60, 64, 69]能够从视频中学习直观的物理模型,但它们需要大量数据,且仅限于特定物体或运动;而物理驱动的方法[9, 12, 27, 44, 63, 71, 72]通常依赖预扫描形状或密集观测来缓解不适定性。此外,它需要密集的视点覆盖,且仅支持有限的运动类型,因此不适用于通用动力学建模。
动态场景重建。动态场景重建旨在从深度扫描[6, 26]、RGBD视频[38]或单目或多视角视频[1, 5, 24, 31, 34, 39, 40, 43, 56, 58, 61, 67, 68]等输入中恢复动态场景的底层表示。动态场景建模的最新进展包括采用新场景表示方法,例如神经辐射场(NeRF)[2, 5, 8, 13, 14, 16, 17, 27, 29, 30, 31, 39–41, 43, 55, 56, 58, 61] 和三维高斯溅射[10, 20, 24, 33, 34, 59, 65, 66, 68]。D-NeRF [43] 通过优化可变形场,扩展经典 NeRF 在动态场景上的应用。类似地,可变形三维高斯溅射(Deformable 3D-GS)[66] 优化每个高斯核的变形场。动态三维高斯溅射(Dynamic 3D-GS)[34] 则针对每一帧优化高斯核的运动,以捕捉场景动态。 4D-GS [59] 使用 4D 神经体素调制 3D 高斯函数,实现动态多视图合成。尽管这些方法在动态多视图合成方面取得高保真度的结果,但它们主要侧重于重建场景外观和几何形状,而忽略捕捉真实世界的动态特性,这限制它们支持基于动作的未来预测和交互式模拟的能力。
基于物理的可变形体模拟。另一项工作是将物理模拟器应用于重建过程中,以进行物理参数的系统识别。早期的方法依赖于预扫描的静态物体,并且需要干净的点云观测数据 [9, 15, 19, 21, 35, 44, 47, 57]。大多数最新方法都基于SDF[45]、NeRF[3, 12, 27]或高斯溅射[22, 63, 71, 72],以支持更灵活的物理数字孪生重建。一些研究[12, 22, 63]手动指定物理参数,导致模拟结果与真实视频观测结果不匹配。其他研究[3, 27, 45, 71, 72]尝试从视频中估计物理参数。然而,这些方法通常受限于合成数据、有限的运动或需要密集的视角才能精确重建静态几何,从而限制它们的实际应用。与本文研究最接近的是Spring-Gaus[72],它也利用三维弹簧-质量模型从视频中学习。然而,他们的物理模型过于正则化,违反真实世界的物理规律,缺乏动量守恒和真实的重力。此外,Spring-Gaus模型需要密集的视点覆盖才能重建初始状态下的完整几何形状,这在许多实际场景中是不切实际的。其运动也仅限于桌面碰撞,缺乏动作输入,因此Spring-Gaus模型不适合作为下游应用的通用动力学模型。
基于学习的可变形体仿真。由于状态空间的高度复杂性和物理属性的可变性,对可变形体的动力学进行解析建模极具挑战性。最近的研究[4, 11, 36, 60, 64]选择使用基于神经网络的模拟器来模拟物体动力学。具体而言,基于图的网络能够有效地学习各种类型物体的动力学,例如橡皮泥[51, 52]、布料[32, 42]、流体[28, 49]和毛绒玩具[69]。 GS-Dynamics [69] 尝试利用动态高斯模型 [34] 的跟踪和外观先验信息,直接从真实视频中学习物体动力学,并且能够很好地泛化到未见过的动作。然而,这些学习模型需要大量的训练样本,并且通常仅限于运动范围有限的特定环境。
PhysTwin
本文旨在利用稀疏视点RGB-D视频序列构建交互式PhysTwin模型,捕捉物体的几何形状、非刚体动力学特性和外观,从而实现逼真的物理模拟和渲染。其采用基于弹簧-质量模型的可变形体动力学模型,实现高效的物理模拟,并能够处理各种常见物体,例如绳索、毛绒玩具、布料和快递包裹。
由于弹簧-质量模型简单高效,因此被广泛用于模拟可变形体。可变形体被表示为一组通过弹簧连接的质量节点,形成图结构 G = (V, E),其中 V 是质量节点的集合,E 是弹簧的集合。每个质量节点 i 具有位置 x_i 和速度 v_i ,它们随时间根据牛顿动力学演化。弹簧基于预定义的拓扑结构在相邻节点之间构建,从而定义物体的弹性结构。
节点 i 上的力是由弹簧连接的相邻节点的共同作用力造成的,其中 k_ij 是弹簧刚度,l_ij 是静止长度,γ 是阻尼器阻尼系数。外力 Fext_i 考虑重力、碰撞和用户交互等因素。弹簧力使系统恢复到静止状态,而阻尼器阻尼则耗散能量,防止振荡。对于碰撞,当两个质点非常接近时,采用基于脉冲的碰撞处理方法,包括物体与碰撞器之间的碰撞以及物体两个质点之间的碰撞。
弹簧-质量模型通过对速度和位置应用显式欧拉积分,利用动态模型 X_t+1 = f_α,G_0 (X_t, a_t) 更新系统状态。更正式地说,对于所有 i,vt+1_i = δ (vt_i +∆t F_i/m_i),xt+1_i = xt_i+∆tvt+1_i,其中 X_t 表示 t 时刻的系统状态,δ 表示阻力阻尼。在该公式中,α 表示弹簧-质量模型的所有物理参数,包括弹簧刚度、碰撞参数和阻尼。它还包含与控制交互相关的参数。G_0 表示弹簧-质量系统的“规范”几何形状和拓扑结构,a_t 表示 t 时刻的动作。
将 PhysTwin 的构建建模为一个优化问题。然后,提出两阶段策略:第一阶段针对物理相关的优化,第二阶段针对外观相关的优化。该框架利用构建的 PhysTwin 具备实时仿真的能力。
问题描述
给定一个可变形体在交互作用下的三个RGB-D视频,目标是构建一个PhysTwin模型,该模型能够捕捉物体随时间变化的几何形状、外观和物理参数。在每个时间帧t,将第i个摄像头的RGB-D观测值记为O_t,i,其中O = (I, D)表示RGB图像I和深度图D。
优化目标是最小化预测观测值Oˆ_t,i与实际观测值O_t,i之间的差异。预测观测值是通过函数g_θ将预测状态Xˆ_t投影并渲染到图像上得到的,其中θ编码由高斯溅射表示的物体外观。3D状态Xˆ_t随时间演化,遵循弹簧-质量模型,该模型捕捉可变形体的动力学特性,并使用显式欧拉积分法更新状态。这样就可以定义一个优化问题的代价函数,其中α、G_0、θ 分别表示物理、几何、拓扑和外观参数;代价函数量化预测观测值 Oˆ_t,i 与实际观测值 O_t,i 之间的差异。该代价函数分解为三个分量:C = C_geometry + C_motion + C_render,分别表示推断的系统状态与来自 3D 几何、3D 运动跟踪和 2D 颜色的相应观测值之间差异。函数 g_θ 是观测模型,描述从预测状态到图像平面的投影,以及来自第 i 个相机的图像空间感知观测。f_α,G 模拟物体状态在弹簧-质量模型下的动态演化。
PhysTwin框架
鉴于定义的整体优化问题的复杂性,PhysTwin框架将其分解为两个阶段。第一阶段侧重于优化几何和物理参数,而第二阶段则致力于优化外观相关参数。如图所示:
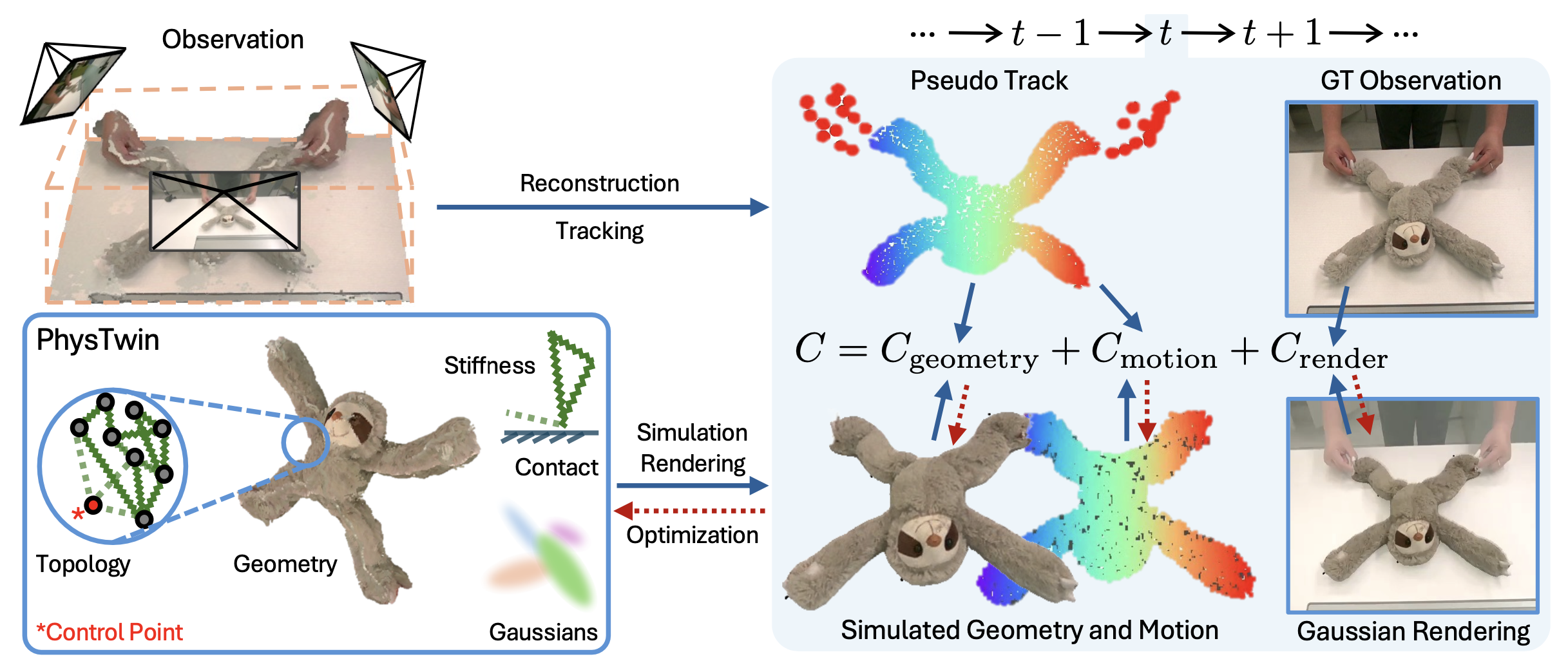
物理和几何优化
如前所述的优化代价,目标是最小化预测观测值Oˆ_t,i与实际观测值O_t,i之间的差异。首先,将每个时间帧t的深度观测值D_t转换为观测的部分3D点云X_t。在第一阶段,考虑优化目标,其中C_geometry 函数量化部分观测点云 X_t 与推断状态 Xˆ_t 之间的单向chamfer距离,而 C_motion 函数量化预测点 xˆt_i 与其对应的观测跟踪点 xt_i 之间的跟踪误差。观测跟踪点使用视觉基础模型 CoTracker3 [23] 获得,然后通过深度图反投影将其提升到 3D 空间。
第一阶段优化面临三个主要挑战:(1)来自稀疏视点的部分观测;(2)离散拓扑和物理参数的联合优化;以及(3)动态模型的不连续性,以及较长的时间跨度和稠密的参数空间,使得连续优化变得困难。为了应对这些挑战,将几何参数和其他参数分开处理。具体而言,首先利用生成式形状初始化来获取完整的几何形状,然后采用两阶段稀疏到稠密优化方法来优化剩余参数。
生成式形状先验。由于观测数据不完整,恢复完整的几何形状极具挑战性。利用图像-到-三维生成模型 TRELLIS [62] 的形状先验,基于对掩码目标的单次 RGB 观测生成完整的网格。为了提高网格质量,首先使用超分辨率模型 [48] 对 TRELLIS 的输入进行增强,该模型对分割后的前景(通过 Grounded-SAM2 [46] 获得)进行放大。虽然生成的网格与相机观测结果吻合良好,但仍然可以观察到尺度、姿态和形变方面的不一致。
为了解决这个问题,设计一个配准模块,该模块使用二维匹配进行尺度估计,并进行刚性配准和非刚性形变。首先,采用由粗到精的策略,利用 SuperGlue [50] 匹配的二维对应关系估计初始旋转,然后使用PnP [25] 算法进行细化。通过优化相机坐标系中匹配点之间的距离来解决尺度和平移歧义。应用这些变换后,物体在姿态上进行对齐,部分形变通过尽可能刚性配准 [53] 来处理。最后,光线投射对齐确保观测点与变形后的网格匹配且无遮挡。
这些步骤生成与第一帧观测值对齐的形状先验,该先验作为逆物理和外观优化阶段的关键初始化。
稀疏-到-稠密优化。弹簧-质量模型由拓扑结构(即弹簧的连接性)和定义在弹簧上的物理参数组成。还引入控制参数,用于连接控制点和目标点之间的弹簧,这些参数由半径和最大邻居数定义。类似地,对于拓扑优化,采用启发式方法连接最近邻点,这些点也由连接半径和最大邻居数参数化,从而控制弹簧的密度。为了从视频数据中提取控制点,用Grounded-SAM2 [46] 分割手部掩码区域,并使用CoTracker3 [23] 跟踪手部运动。将这些点提升到3D空间后,应用最远点采样来获得最终的控制点集。
上述所有组件构成旨在优化的参数空间。两大挑战是:(1) 部分参数不可微(例如半径和最大邻居数);(2) 为了表示各种目标,对稠密弹簧刚度进行建模,导致参数空间包含数万个弹簧。
为了应对这些挑战,引入一种分层稀疏-到-稠密的优化策略。首先,采用零阶、基于采样的优化方法来估计参数,这自然地规避不可微问题。然而,当参数空间过大时,零阶优化会变得效率低下。因此,在第一阶段,假设刚度均匀,从而使拓扑结构和其他物理参数获得良好的初始化。在第二阶段,利用自主开发的可微分弹簧-质量模拟器,通过一阶梯度下降进一步优化参数。该阶段同时优化稠密弹簧刚度和碰撞参数。
除了优化策略之外,还利用视觉基础模型中的跟踪先验信息引入额外的监督。将二维跟踪预测提升到三维空间,从而获得三维点的伪真实跟踪数据,这构成了成本函数的关键组成部分。
通过将优化策略与利用额外跟踪先验信息的成本函数相结合,PhysTwin 框架能够高效地对视频中各种可交互目标动态特性进行建模。
外观优化
在第二阶段外观优化中,为了对物体外观进行建模,构建一组由参数 θ 定义的静态 3D 高斯核。每个高斯核由一个 3D 中心位置 μ、一个由四元数 q 表示的旋转矩阵、一个由 3D 向量 s 表示的缩放矩阵、一个不透明度值 α 和颜色系数 c 定义。定义一个优化 θ的目标函数,其中 Xˆ_t 表示 t 时刻的优化系统状态,i 表示相机索引,I_i,t 和 Iˆ_i,t 分别表示 t 时刻相机视图 i 的真实图像和渲染图像。C_render 使用渲染图像和真实图像之间的 D-SSIM 项计算 L1 损失。为简单起见,设置 t = 0 以仅优化第一帧的外观。将高斯形状限制为各向同性,以防止变形过程中出现尖峰伪影。
为了确保形变下渲染效果逼真,需要根据状态 Xˆ_t 和 Xˆ_t+1 之间的转换,在每个时间步 t 动态调整每个高斯函数。为此,采用一种基于线性混合蒙皮 (LBS) 的高斯更新算法 [20, 54, 69],该算法利用相邻质量节点的运动来插值三维高斯函数的运动。
PhysTwin 的功能
构建的 PhysTwin 支持对各种运动状态下的可变形物体进行实时仿真,同时保持逼真的外观。这种实时、照片级真实感的仿真实现对物体动力学的交互式探索。
通过引入控制点并利用弹簧将其动态连接到物体上的控制点,系统可以模拟各种运动模式和交互。这些功能使 PhysTwin 成为实时交互式仿真和基于模型的机器人运动规划的强大表示方法。
实验设置
数据集。收集一个 RGBD 视频数据集,该数据集捕捉人与各种具有不同物理属性的可变形体(例如绳索、毛绒玩具、布料和快递包裹)的交互过程。用三台 RealSense-D455 RGBD 摄像机记录这些交互过程。每个视频时长为 1 至 10 秒,捕捉不同的交互动作,包括用一只或双手快速提起、伸展、推动和挤压物体。收集 22 个场景,涵盖各种物体类型、交互类型和手部姿势。对于每个场景,将 RGBD 视频按照 7:3 的比例分为训练集和测试集,其中仅使用训练集来构建 PhysTwin 模型。为每个视频手动标注 9 个真实跟踪点,并使用 [7] 中介绍的半自动工具评估跟踪性能。
任务。为了评估 PhysTwin 框架的有效性以及构建的 PhysTwin 质量,设计三个任务:(1)重建与重模拟;(2)未来预测;(3)泛化到未见动作。
对于重建与重模拟任务,目标是构建一个 PhysTwin,使其能够根据控制点位置所代表的动作,准确地重建和重模拟可变形体的运动。
对于未来预测任务,旨在评估 PhysTwin 在构建过程中能否很好地处理未见的未来帧。对于泛化到未见交互任务,目标是评估 PhysTwin 能否适应不同的交互。为了评估这一点,构建一个泛化数据集,该数据集包含对同一物体执行但运动不同的交互对,包括手部姿势和交互类型的差异。
基线。选择两个主要的研究方向作为基准,并对其进行进一步扩展,使其与设定的任务相匹配。
考虑的第一个基准是基于物理的仿真方法 Spring-Gaus [72],用于识别可变形体的材料属性。他们的工作在其原始设置中展现强大的重建、重仿真和未来预测能力。然而,他们的框架不支持外部控制输入,因此为其添加额外的控制功能。
对于 Spring-Gaus,虽然它在建模物体碰撞视频方面表现出合理的性能,但其适用范围仅限于物体主要在重力作用下变形的相对简单的情况,这限制了其支持的物体类型范围。为了使 Spring-Gaus [72] 适应本文设置,通过引入对控制点的支持对其进行扩展。具体来说,添加额外的弹簧,将控制点与其在预定义距离内的相邻物体点连接起来,从而可以直接在数据集上进行优化。此外,为了确保与稀疏视图设置兼容,将形状先验作为其静态高斯构造的初始化。由于构建的高斯函数缺乏泛化到不同初始条件的能力,仅在重建与重模拟和未来预测这两项任务上评估他们的方法。
第二个基准是基于学习的仿真方法 GS-Dynamics [69],它采用基于图神经网络 (GNN) 的神经动力学模型,直接从部分观测数据中学习系统动力学。在其原始设置中,需要使用 Dyn3DGS [34] 对视频进行预处理才能获得跟踪信息。为了进行更公平的比较,使用基于 CoTracker3 [23] 的 3D 提升跟踪器来增强模型,该跟踪器为 GS-Dynamics 使用的神经动力学模型的训练提供更高效、更精确的监督。
对于 GS-Dynamics,在所有三项任务上将方法与他们的方法进行比较。为了使基于图神经网络(GNN)的动力学模型能够生成逼真的渲染效果,采用高斯混合策略对其进行增强,从而提高其生成高质量图像的能力。
评估。为了更好地了解预测是否与观测结果相符,分别在 3D 和 2D 空间中评估预测结果。对于 3D 评估,使用单向chamfer距离(部分真实值与完整状态预测)和跟踪误差(基于手动标注的真实跟踪点)。对于 2D 评估,用 PSNR、SSIM 和 LPIPS [70] 来评估图像质量,并使用 IoU 来评估轮廓对齐情况。由于中心视点处物体可见性最佳,仅在中心视点进行 2D 评估,并将所有帧和场景的指标取平均值。特别地,对于 Spring-Gaus [72] 基线模型,由于物理建模不准确,其优化过程不稳定。因此,仅报告成功案例的上述指标。
任务。PhysTwin 仅基于每个数据点的训练集构建,其性能评估基于其在测试集中与原始视频的匹配程度。对于泛化任务,创建一个数据集,其中包含对同一物体执行的交互对。例如,基于单手提起树懒玩具的场景构建 PhysTwin,然后在双手伸展其腿部的不同场景中评估其性能。该数据集包含 11 个这样的交互对,由于每个交互对允许两种可能的迁移方向(即从一个交互到另一个交互,反之亦然),因此总共进行 22 次泛化实验。在此任务中,PhysTwin 仍然仅使用源交互的训练集构建,但应用于目标交互的整个序列。

















 1136
1136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









