







KMP算法用于解决字符串匹配的问题。
举例:aabaabaaf,模式串 aabaaf,想知道在这个文本串中是否出现了这个模式串文本串
暴力法是双重for循环,时间复杂度O(mn) ,m是文本串长度 n是模式串长度
- KMP如何解决?
得到前缀表
前缀表:模式串最长相等前后缀
前缀:包含首字母,不包含尾字母的所有子串(a, aa, aab, aaba, aabaa)
后缀:包含尾字母,不包含首字母的所有子串(f, af, aaf, baaf, abaaf)
最长相等前后缀( 实则是长度 :
a 没有前缀,也没有后缀,所以它的最长相等前后缀 = 0
aa : 1(前缀a 后缀a)
aab: 0 (前缀a aa 后缀 b ab)
aaba: 1 (前缀a、aa、aab 后缀 a、ba、aba)
aabaa : 2(前缀a、aa、aab、aaba 后缀 a、aa、baa、abaa)
aabaaf: 0
010120就是我们模式串的前缀表
a a b a a f
0 1 0 1 2 0
找到这个模式串aabaaf,每个位置的子串[0,i]的最长相等前后缀
用前缀表匹配
找到冲突位置 前面一个字符串 的最长相等前后缀 是多少

next数组
next数组告诉我们遇到冲突之后回退到哪里
next数组有很多种实现方式,比如①next数组就是前缀表②前缀表整体右移(-1 0 1 0 1 2)③整体减一(-1 0 -1 0 1 -1)
代码随想录中采用①
next数组具体代码实现JS
求字符串s的next数组
理解不了就背吧。。。。。。。。
思路:
初始化
要处理前后缀不同的情况 & 处理前后缀相同的情况。
-
初始化:
next数组长度和模式串一样
j指向前缀末尾位置,i指向后缀末尾位置
j其实还表示 i 之前(包括i)子串的最长相等前后缀长度
i 初始化:从1开始 -
前后缀不同的情况:回退直到前后缀相同 所以要用while

-
前后缀相同的情况:j++; next[i] = j;
每一次循环,都更新下标 i 的next数组
const getNext = (s) => {
const next = new Array(s.length).fill(0);
next[0] = 0;
let j = 0;
for(let i = 1; i < s.length; i++) {
while(j > 0 && s[i] !== s[j]) {
j = next[j - 1];
}
if(s[i] === s[j]) {
j++;
}
next[i] = j;
}
return next;
}
有了next怎么使用next?
- 以力扣 28题为例
/**
* @param {string} haystack
* @param {string} needle
* @return {number}
*/
const findnext = (s) => {
const next = new Array(s.length).fill(0);
next[0] = 0;
let j = 0;
for(let i = 1; i < next.length; i++) {
// if(s[i] !== s[j]) {
while(j > 0 && s[i] !== s[j]) {
j = next[j-1];
}
// }
if(s[i] === s[j]) {
j++;
}
next[i] = j;
}
return next;
}
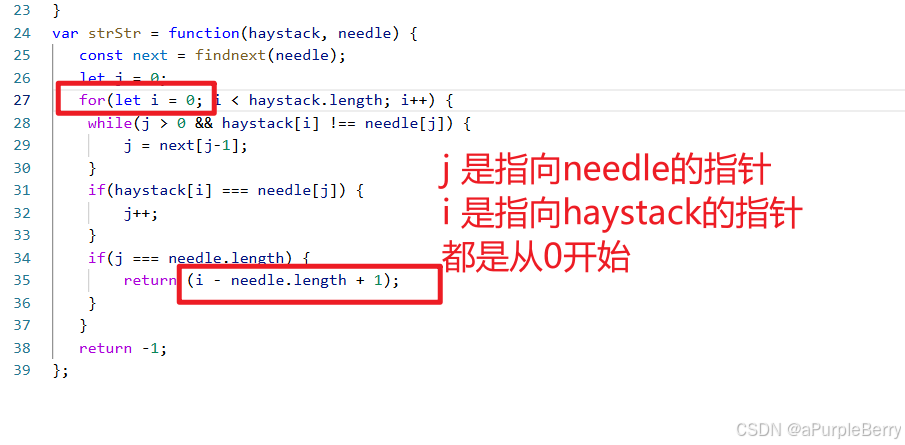
var strStr = function(haystack, needle) {
const next = findnext(needle);
let j = 0;
for(let i = 0; i < haystack.length; i++) {
while(j > 0 && haystack[i] !== needle[j]) {
j = next[j-1];
}
if(haystack[i] === needle[j]) {
j++;
}
if(j === needle.length) {
return (i - needle.length + 1);
}
}
return -1;
};
参考资料
代码随想录 BV1PD4y1o7nd
https://www.bilibili.com/video/BV1PD4y1o7nd/?vd_source=ceab44fb5c1365a19cb488ab650bab03

















 1246
1246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









