



本文阐述了LangChain结合DeepSeek API,以及本地安装Ollama的模型使用示例,代码经过修改对应的配置即可运行。
参考链接:
英文:Introduction | 🦜️🔗 LangChain
中文:introduction | LangChain中文网
一. 使用DeepSeek API, 进行问答
1.安装LangChain以及相关依赖
pip3 install langchain langchain-openai langchain-community deepseek-sdk pillow
2. 使用DeepSeek API Key
DeepSeek API Key创建DeepSeek API KeyDeepSeek API Key: DeepSeek API Key, 替换以下脚本中的sk-xxx,以及选择模型V3还是R1.
from langchain_openai import ChatOpenAI
import os
# 配置API参数
os.environ["OPENAI_API_KEY"] = "sk-xxx" # 替换为实际密钥
llm = ChatOpenAI(
base_url="https://api.deepseek.com/v1", # API地址
model="deepseek-chat", # 模型名称(支持deepseek-chat/V3或deepseek-reasoner/R1)
temperature=0.7 # 控制生成随机性
)
# 调用示例
response = llm.invoke("解释量子计算的基本原理")
print(response.content)
如果看到以下输出,则配置正常。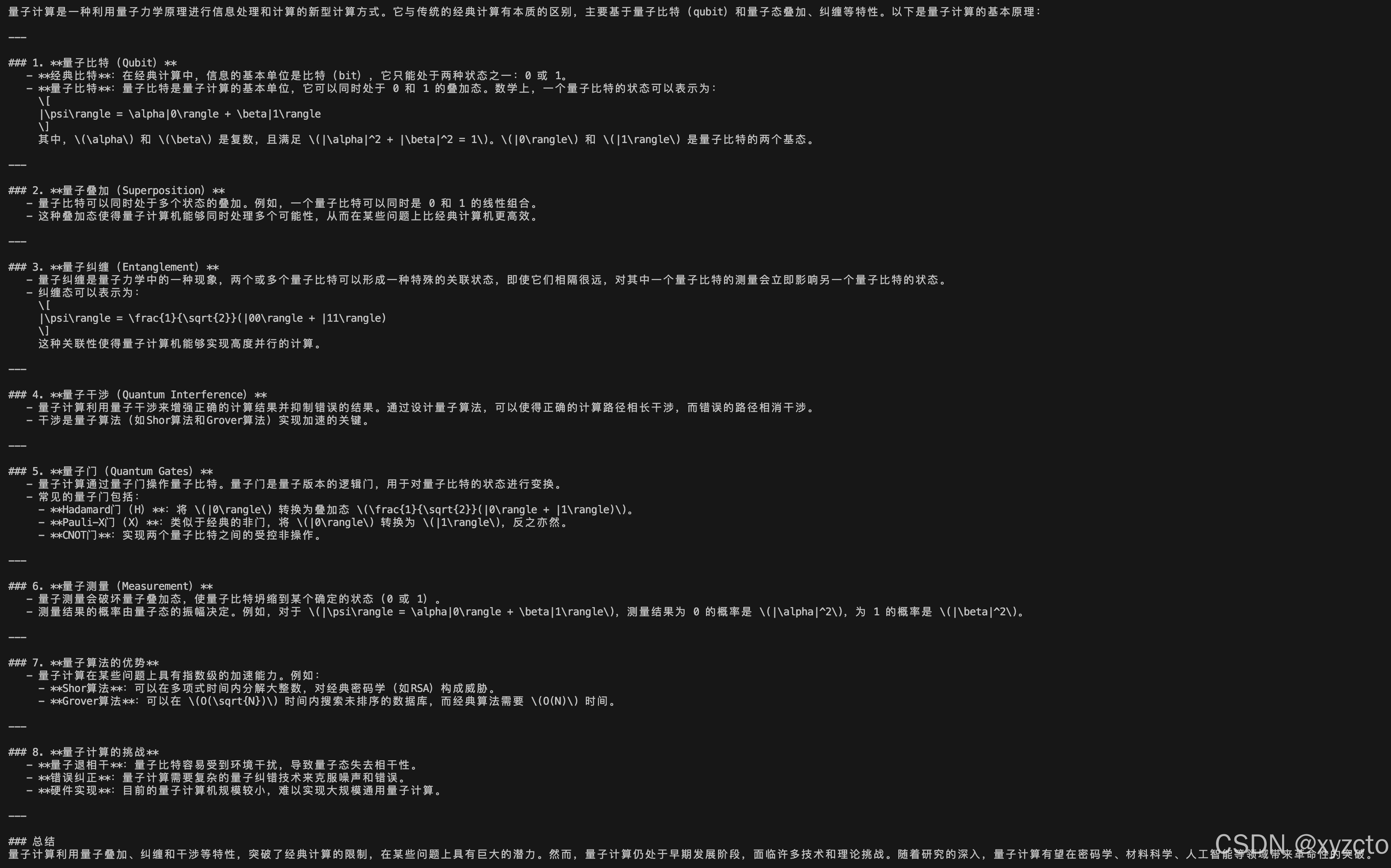
三. LangChain集成Ollama
1. 安装依赖:
pip3 install langchain_ollama 2. 使用Ollama安装的模型进行问答
以下代码是使用Ollama安装的deepseek-r1:7b模型,安装Ollama以及本地化安装deepseek-r1:7b模型请参考:
Alibaba Cloud Linux 基于Ollama部署DeepSeek R1:7B版本_linux ollama 部署7b deepseek-优快云博客
from langchain.llms.base import LLM
from typing import Optional, List, Mapping, Any
from langchain.chains import ConversationalChain
from langchain.memory import ConversationBufferMemory
import requests
import json
class OllamaLLM(LLM):
model: str = "deepseek-r1:7b" # 默认模型
temperature: float = 0.7
max_tokens: int = 256
endpoint: str = "http://localhost:11434" # Ollama API 地址
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
headers = {"Content-Type": "application/json"}
payload = {
"model": self.model,
"prompt": prompt,
"temperature": self.temperature,
"max_length": self.max_tokens,
"stop": stop # Ollama 支持 stop 参数
}
response = requests.post(
f"{self.endpoint}/api/generate",
headers=headers,
json=payload,
stream=True # 支持流式响应
)
# 处理流式响应(可选,LangChain 支持流式)
if response.status_code == 200:
full_response = ""
for chunk in response.iter_lines():
if chunk:
data = json.loads(chunk.decode())
if "response" in data:
full_response += data["response"]
return full_response
else:
raise Exception(f"Ollama API 错误:{response.status_code}")
@property
def _llm_type(self) -> str:
return "ollama"
ollama_llm = OllamaLLM(model="deepseek-r1:7b", temperature=0.5, max_tokens=500)
print(ollama_llm("写一个关于人工智能的短篇故事开头:"))四. LangChain 结合Ollama实现RAG
1. 安装依赖:
yum install -y libX11 libXext2. 使用Ollama 安装的embedding模型,将分块后的信息保存至向量数据库:
这里以安装的nomic-embed-text模型为例,模型安装参考:
AnythingLLM 结合nomic-embed-text 处理文档建立私有知识库-优快云博客
from langchain_community.embeddings import OllamaEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_community.document_loaders import TextLoader
# 初始化模型 (关键配置)
embed_model = OllamaEmbeddings(
base_url="http://localhost:11434", # Ollama 服务地址
model="nomic-embed-text:latest", # 模型名称
)
# 加载文档并切分
loader = TextLoader("test.txt")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=2000,
chunk_overlap=100
)
splits = text_splitter.split_documents(docs)
# 使用nomic模型生成向量库
vector_db = FAISS.from_documents(
splits,
embed_model
)
# 持久化存储
vector_db.save_local("./faiss_nomic")
# 打印向量数据库中的分块信息
print("向量数据库中的分块信息:")
for i, doc in enumerate(vector_db.docstore._dict.values()):
print(f"分块 {i + 1} 内容:")
print(doc.page_content)
print(f"分块 {i + 1} 元数据:{doc.metadata}")
print("-" * 50)3. 查询已有向量数据库的分块信息:
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores import FAISS
# 初始化本地Ollama嵌入模型
nomic_embeddings = OllamaEmbeddings(
model="nomic-embed-text:latest",
base_url="http://localhost:11434", # Ollama默认端口
temperature=0, # 温度参数对嵌入模型无效,保持0即可
# 模型特有参数 (参考官方文档)
model_kwargs={
"embedding_mode": "classic", # classic|new
"ntokens": 2048 # 上下文长度
}
)
# 加载已有的FAISS索引库 (必须使用相同嵌入模型创建)
vector_db = FAISS.load_local(
folder_path="./faiss_nomic",
embeddings=nomic_embeddings, # 必须与原索引的嵌入模型一致
allow_dangerous_deserialization=True # 安全反序列化开关
)
# 创建检索器配置
retriever = vector_db.as_retriever(
search_type="mmr", # mmr: 平衡相关性与多样性
search_kwargs={
"k": 5, # 返回前5个结果
"lambda_mult": 0.2, # MMR调节参数 (0: 纯相关性, 1: 纯多样性)
#"filter": { # 元数据过滤 (与原文档架构匹配)
# "source": "年度技术报告.pdf"
#}
}
)
# 打印向量数据库中的分块信息
print("向量数据库中的分块信息:")
for i, doc in enumerate(vector_db.docstore._dict.values()):
print(f"分块 {i + 1} 内容:")
print(doc.page_content)
print(f"分块 {i + 1} 元数据:{doc.metadata}")
print("-" * 50)五. 通过LangServe将LangChain发布为Restful接口
1. 安装依赖:
pip install "langserve[all]"2. 将使用本地Ollama安装的模型的服务发布为Restful接口
以编写一个主题的笑话为例:
from langchain.llms.base import LLM
from typing import Optional, List, Mapping, Any
import requests
import json
from fastapi import FastAPI
from langchain.prompts import PromptTemplate
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatAnthropic, ChatOpenAI
from langserve import add_routes
from langchain.chains import LLMChain
from pydantic import BaseModel
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple api server using Langchain's Runnable interfaces",
)
class OllamaLLM(LLM):
model: str = "deepseek-r1:7b" # 默认模型
temperature: float = 0.7
max_tokens: int = 256
endpoint: str = "http://localhost:11434" # Ollama API 地址
def _call(self, prompt: str, stop: Optional[List[str]] = None,run_manager=None) -> str:
headers = {"Content-Type": "application/json"}
payload = {
"model": self.model,
"prompt": prompt,
"temperature": self.temperature,
"max_length": self.max_tokens,
"stop": stop # Ollama 支持 stop 参数
}
response = requests.post(
f"{self.endpoint}/api/generate",
headers=headers,
json=payload,
stream=True # 支持流式响应
)
# 处理流式响应(可选,LangChain 支持流式)
if response.status_code == 200:
full_response = ""
for chunk in response.iter_lines():
if chunk:
data = json.loads(chunk.decode())
if "response" in data:
full_response += data["response"]
# 如果支持流式响应并需要回调,可以在这里调用 run_manager
if run_manager:
run_manager.on_llm_new_token(data["response"])
return full_response
else:
raise Exception(f"Ollama API 错误:{response.status_code}")
@property
def _llm_type(self) -> str:
return "ollama"
ollama_llm = OllamaLLM(model="deepseek-r1:7b", temperature=0.5, max_tokens=500)
# 定义输入模型
class JokeInput(BaseModel):
topic: str
# 定义提示模板
prompt = PromptTemplate(
input_variables=["topic"],
template="请给我讲一个关于 {topic} 的笑话。"
)
#prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
# 创建 LLMChain 实例
chain = LLMChain(llm=ollama_llm, prompt=prompt)
add_routes(
app,
chain,
path="/joke",
input_type=JokeInput
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="*", port=8000)3: 通过LangServe Playground体验:
http://ip:port/joke/playground/
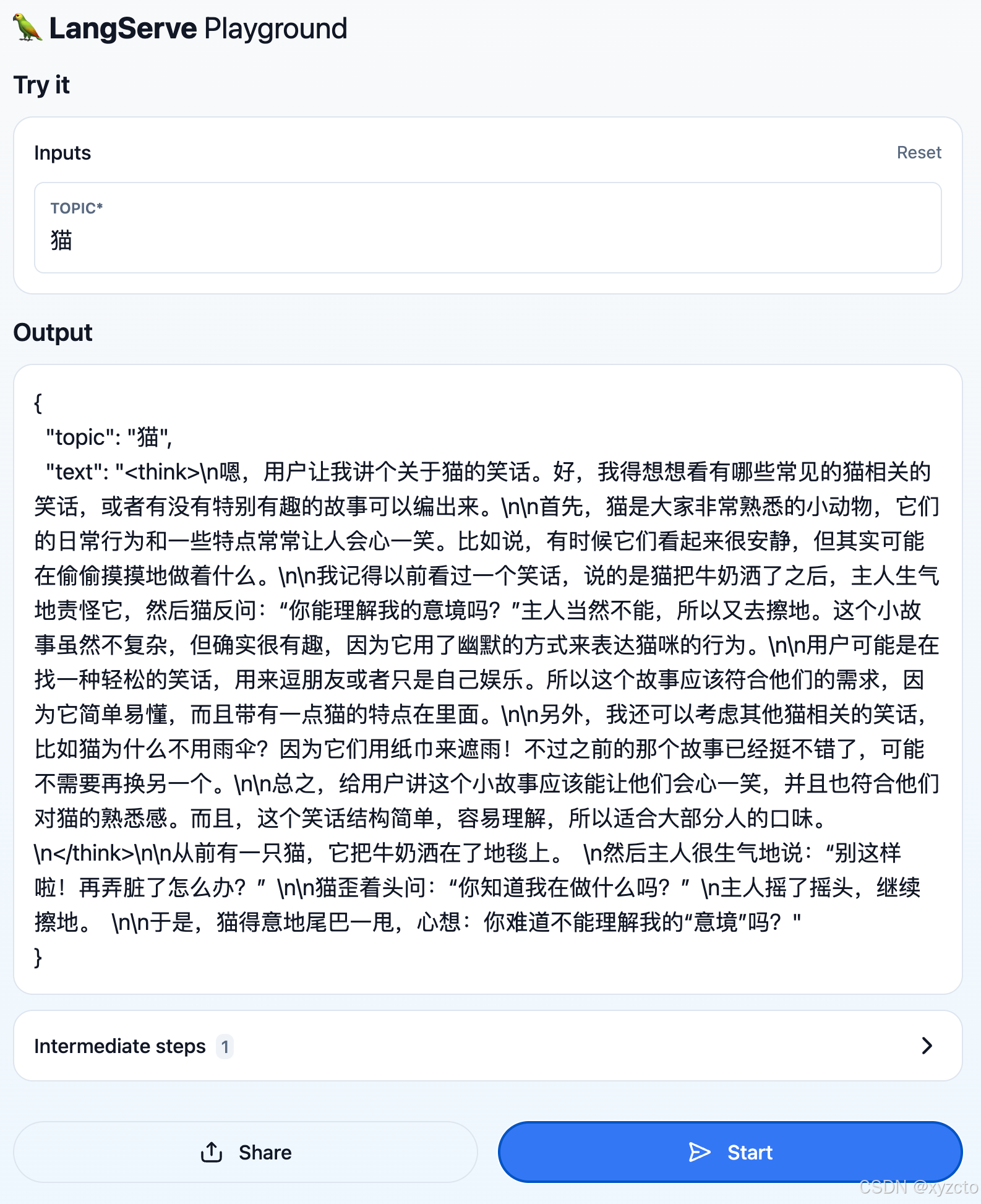
4. 使用curl命令测试Restful接口,注意其中的地址使用/joke/invoke:
curl -X POST -H "Content-Type: application/json" -d '{"input": {"topic": "猫"}}' http://localhost:8000/joke/invoke



















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











