




引言
本次测评旨在对当前主流的 AI 大模型进行客观、公正的逻辑推理能力测评。包括以下模型:
1.文心一言
2.豆包
3.通义千问
4.Kimi
5.Copilot
6.ChatGPT o1-mini
7.DeepSeek R1
8.讯飞星火
9.Grok 3
一 题目:3,10,15,26,下一个数字是多少?
1.文心一言 4.0 Turbo

结果:❌
2. 豆包
![]()
结果:✅
3.通义千问
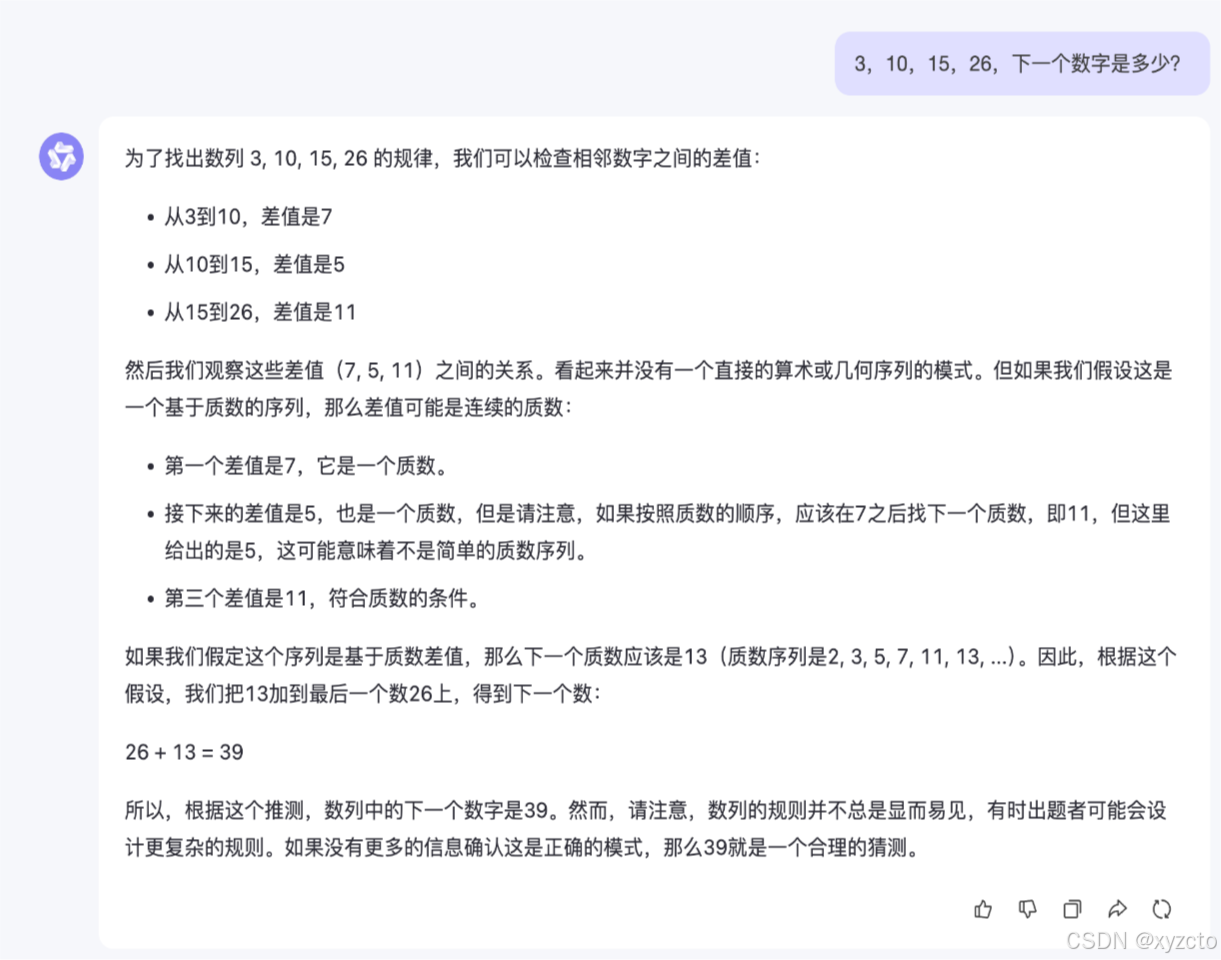
结果:❌
4. kimi
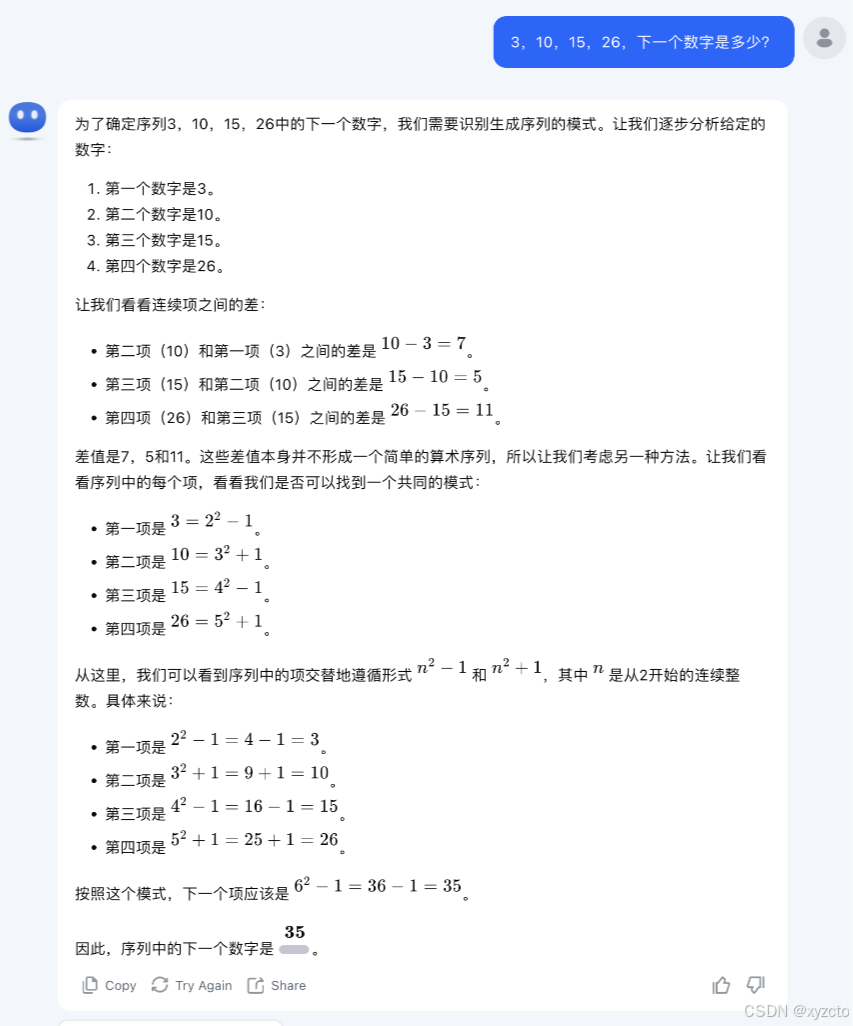
结果:❌
5.Copilot

结果:❌
6. ChatGPT o1-mini

结果:❌
7. DeepSeek R1

结果:✅
8.讯飞星火

结果:✅
9. Grok 3

结果:❌ 将n=4时,错误计算为26了,按二项式计算应该为16。
二.题目:6,9,15,21,33,下一个数字多少?
1.文心一言 4.0 Turbo

结果:❌
2. 豆包

结果:✅
3.通义千问
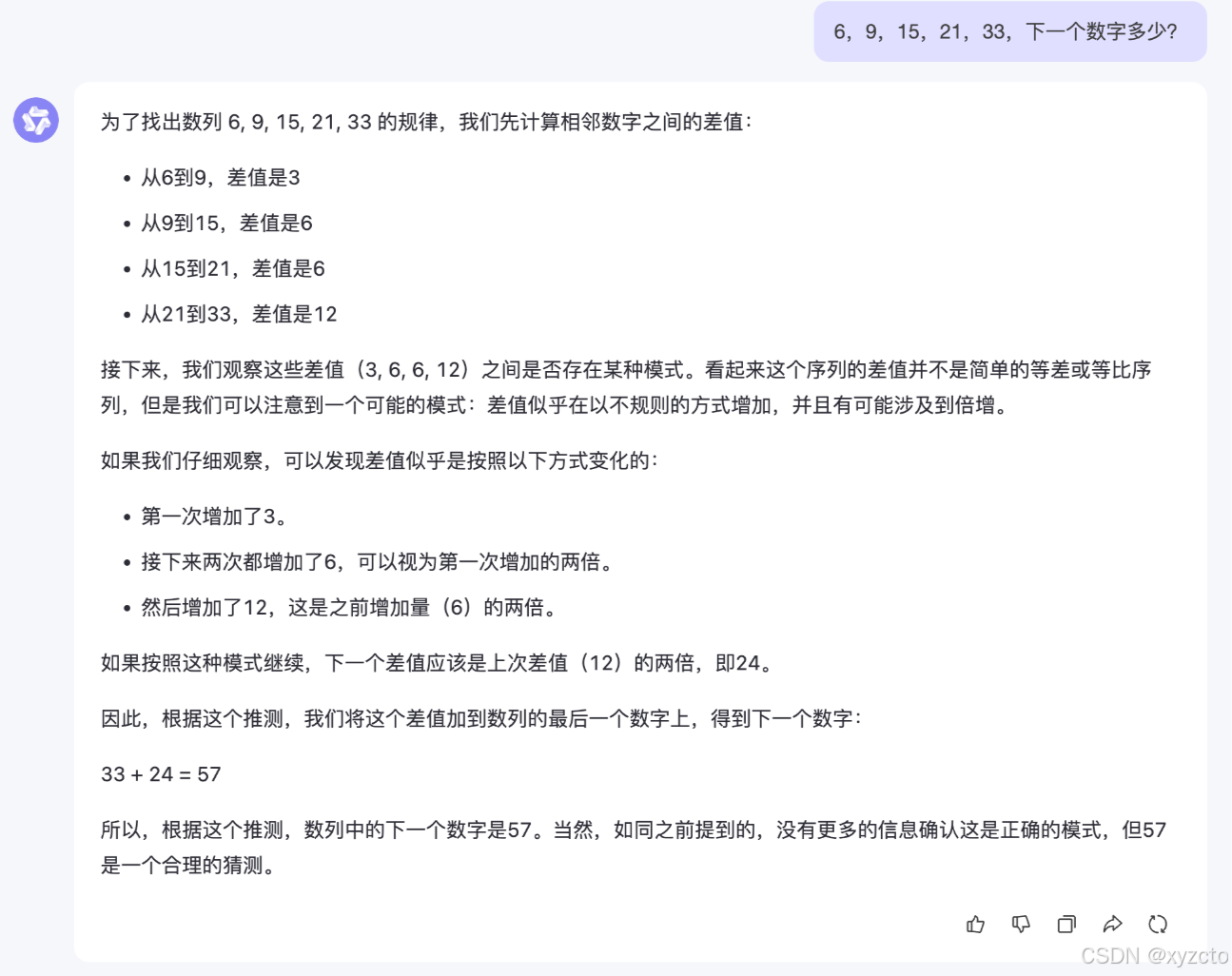
结果:❌
4.kimi
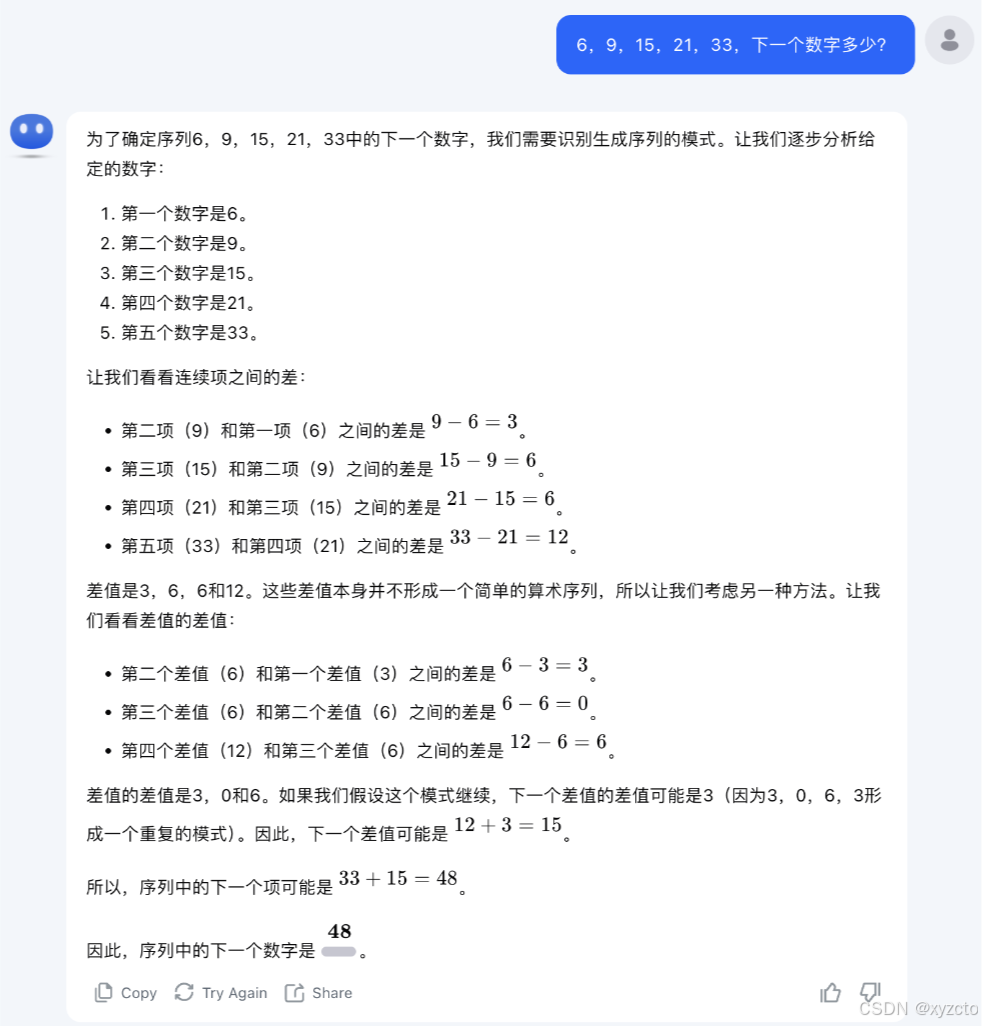
结果:❌
5.Copilot

结果:❌
6.ChatGPT o1-mini

结果:❌
7.DeepSeek




结果:✅
8. 讯飞星火

结果:✅
9. Grok 3

结果:✅
三. 题目:3968,63,8,3,下一个数字是多少?
1. 文心一言 4.0 Turbo

结果:❌
2. 豆包

结果:✅
3.通义千问

结果:❌
4.kimi

结果:❌
5.Copilot

结果:✅,方法不对
6.ChatGPT o1-mini

结果:❌
7.DeepSeek R1

结果:✅
8.讯飞星火

结果:半✅,根据规律,应该排除负数的情况
9. Grok 3

结果:答案✅,但过程不对。
三. 结论

从测试结果可以看出豆包和DeepSeek R1的表现最好,3题全对;DeepSeek给出了详细的推理过程,以及验证。 讯飞星火,三道题基本全对,只是最后一道题没有排除-2,稍逊豆包;Copilot最后一题虽然答案对了,推理过程完全错误;文心一言,通义千问,ChatGPT o1-mini 有点大跌眼镜,后续将补充上ChatGPT o1模型的结果。
鉴于DeepSeek给出详细推理过程,豆包只给出结果,针对大模型的逻辑推理能力非要排个名的话:
Grok 3 有些令人失望,第一题就错了,最后一题答案对了,并没有找到真正的规律,Grok 3的加入也没有影响排名。
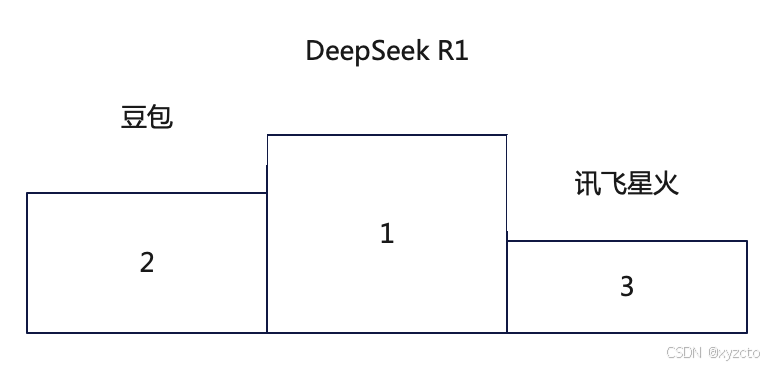
本来想用大模型文生图生成上面的图,尝试了半天,没有得到可用的图,之后将针对各大模型文生图的能力做个测评,敬请期待。



















 797
797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











