




1回顾
前面的几章内容探讨了aclgraph运行过程中的涉及到的关键模块和技术。本章节将前面涉及到的模块串联起来,对aclgraph形成一个端到端的了解。
先给出端到端运行的代码,如下:
import torch
import torch_npu
import torchair
import logging
from torchair import logger
logger.setLevel(logging.INFO)
torch._logging.set_logs(dynamo=logging.DEBUG,aot=logging.DEBUG,output_code=True,graph_code=True)
# Patch方式实现集合通信入图(可选)
from torchair import patch_for_hcom
patch_for_hcom()
# 定义模型Model
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x, y):
return torch.add(x, y)
# 实例化模型model
model = Model().npu()
# 获取TorchAir提供的默认npu backend,自行配置config功能
config = torchair.CompilerConfig()
config.mode = "reduce-overhead"
npu_backend = torchair.get_npu_backend(compiler_config=config) // 关注点1
# 使用npu backend进行compile
opt_model = torch.compile(model, backend=npu_backend) // 关注点2
# 使用编译后的model去执行
x = torch.randn(2, 2).npu()
y = torch.randn(2, 2).npu()
out = opt_model(x, y) // 关注点3
pring(out)
config.mode = "reduce-overhead"配置了aclgraph的模式。该代码在CANN8.1rc1(https://www.hiascend.com/document/detail/zh/canncommercial/81RC1/quickstart/index/index.html),torch_npu插件版本 7.0.0(https://www.hiascend.com/document/detail/zh/Pytorch/700/configandinstg/instg/insg_0004.html)以后的版本上aclgraph模式才得以支持,是可以运行起来的。
关注上述代码的3个主要部分。
2 torchair.get_npu_backend
def get_npu_backend(*, compiler_config: CompilerConfig = None, custom_decompositions: Dict = {
}):
if compiler_config is None:
compiler_config = CompilerConfig()
decompositions = get_npu_default_decompositions()
decompositions.update(custom_decompositions)
add_npu_patch(decompositions, compiler_config)
return functools.partial(_npu_backend, compiler_config=compiler_config, decompositions=decompositions)
从Ascend的aclgraph(一)aclgraph是什么?torchair又是怎么成图的?中可知。该函数最终返回的是_npu_backend在固定参数compiler_config和decompositions下返回的一个新的函数。
def _npu_backend(gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor],
compiler_config: CompilerConfig = None, decompositions: Dict = {
}):
if compiler_config is None:
compiler_config = CompilerConfig()
compiler = get_compiler(compiler_config)
input_dim_gears = dict()
for i, t in enumerate(example_inputs):
dim_gears = get_dim_gears(t)
if dim_gears is not None:
input_dim_gears[i - len(example_inputs)] = dim_gears
fw_compiler, inference_compiler, joint_compiler = _wrap_compiler(compiler, compiler_config)
fw_compiler = _set_gear_to_compiler(fw_compiler, compiler_config, input_dim_gears)
inference_compiler = _set_gear_to_compiler(inference_compiler, compiler_config, input_dim_gears)
partition_fn = _get_partition_fn(compiler_config)
if compiler_config.experimental_config.aot_config_enable_joint_graph:
output_loss_index = int(compiler_config.experimental_config.aot_config_output_loss_index.value)
return aot_module_simplified_joint(gm, example_inputs,
compiler=joint_compiler, decompositions=decompositions,
output_loss_index=output_loss_index)
keep_inference_input_mutations = bool(compiler_config.experimental_config.keep_inference_input_mutations)
# TO DO: fix me in master
if compiler_config.mode.value == "reduce-overhead":
keep_inference_input_mutations = False
logger.debug(f"To temporarily avoid some precision problem in AclGraph, "
f"keep_inference_input_mutations config is set to {
keep_inference_input_mutations}.")
return aot_module_simplified(gm, example_inputs, fw_compiler=fw_compiler, bw_compiler=compiler,
decompositions=decompositions, partition_fn=partition_fn,
keep_inference_input_mutations=keep_inference_input_mutations,
inference_compiler=inference_compiler)
_npu_backend中最终返回的是aot_module_simplified。_npu_backend的解析请参照Ascend的aclgraph(一)aclgraph是什么?torchair又是怎么成图的?和Ascend的aclgraph(二)_npu_backend中还有些什么秘密?。
aot_module_simplified 作用在前文中可知是:通常用于简化将一个 PyTorch 模型准备好进行 AOT 编译的过程,简单理解就是AOT编译前的预操作。
写个示例:
import torch
from torch.compile import aot_module_simplified
# 假设有一个简单的模型
class SimpleModel(torch.nn.Module):
def forward(self, x):
return torch.relu(x)
model = SimpleModel()
# 使用 aot_module_simplified 进行 AOT 编译
compiled_model = aot_module_simplified(model)
# 现在可以使用 compiled_model 进行推理
input_tensor = torch.randn(5)
output_tensor = compiled_model(input_tensor)
print(output_tensor)
在这个示例中,compiled_model 就是经过 aot_module_simplified 编译优化后的模型。你可以像使用普通 PyTorch 模型那样调用它的方法来进行推理。
回到代码中的关注1,那么npu_backend 返回的就是一个可以执行的model对象torch.nn.Module
接着看关注2。
3 torch.compile(model, backend=npu_backend)
通过Ascend的aclgraph(二)_npu_backend中还有些什么秘密?可知backend是一个回调函数(可调用的对象)
def _optimize(
rebuild_ctx: Callable[[], Union[OptimizeContext, _NullDecorator]],
backend="inductor",
*,
nopython=False,
guard_export_fn=None,
guard_fail_fn=None,
disable=False,
dynamic=None,
) -> Union[OptimizeContext, _NullDecorator]:
# 中间代码省略...
return _optimize_catch_errors(
convert_frame.convert_frame(backend, hooks=hooks), // backend,回调函数
hooks,
backend_ctx_ctor,
dynamic=dynamic,
compiler_config=backend.get_compiler_config()
if hasattr(backend, "get_compiler_config")
else None,
rebuild_ctx=rebuild_ctx,
)
# ---------------------------------------------------------------------------------------------------------------------------------------
def _optimize_catch_errors(
compile_fn,
hooks: Hooks,
backend_ctx_ctor=null_context,
export=False,
dynamic=None,
compiler_config=None,
rebuild_ctx=None,
):
return OptimizeContext(
convert_frame.catch_errors_wrapper(compile_fn, hooks), // 回调函数
backend_ctx_ctor=backend_ctx_ctor,
first_ctx=True,
export=export,
dynamic=dynamic,
compiler_config=compiler_config,
rebuild_ctx=rebuild_ctx,
)
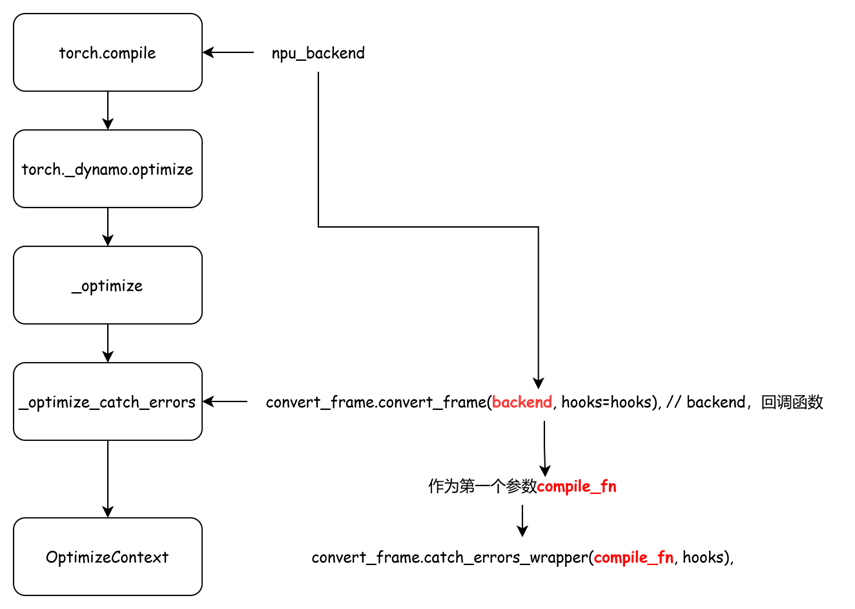
上述这些 ,都是pytorch代码中的标准流程。在npu上却有些不一样。
3.1 npu上的torch._dynamo.optimize
首先还是从代码torch.compile开始
def compile(model: Optional[Callable] = None, *, # Module/function to optimize
fullgraph: builtins.bool = False, #If False (default), torch.compile attempts to discover compileable regions in the function that it will optimize. If True, then we require that the entire function be capturable into a single graph. If this is not possible (that is, if there are graph breaks), then this will raise an error.
dynamic: Optional[builtins.bool] = None, # dynamic shape
backend: Union[str, Callable] = "inductor", # backend to be used
mode: Union[str, None] = None, # Can be either "default", "reduce-overhead", "max-autotune" or "max-autotune-no-cudagraphs"
options: Optional[Dict[str, Union[str, builtins.int, builtins.bool]]] = None, # A dictionary of options to pass to the backend. Some notable ones to try out are
disable: builtins.bool = False) # Turn torch.compile() into a no-op for testing
-> Callable:
# 中间代码省略...
return torch._dynamo.optimize(backend=backend, nopython=fullgraph, dynamic=dynamic, disable=disable)(model)
compile中调用的是torch._dynamo.optimize函数。而npu上的torch._dynamo.optimize是被重新赋值的。
函数调用流程如下:

def patch_dynamo_optimize():
src_optimize = optimize
def npu_optimize(*args, **kwargs):
backend = None
if 'backend' in kwargs.keys():
backend = kwargs['backend']
elif len(args) == 1:
backend = args[0]
backend_name = None
if isinstance(backend, str):
backend_name = backend
elif isinstance(backend, _TorchCompileWrapper):
backend_name = backend.compiler_name
if backend_name == 'npu':
# Init torchair ahead of running model.
_get_global_npu_backend()
return src_optimize(*args, **kwargs)
torch._dynamo.optimize = npu_optimize
可以看到,torch._dynamo.optimize = npu_optimize已经被重新赋值了。依旧从代码的角度,看下是如何一步步执行下去的。
_get_global_npu_backend返回的是torchair.get_npu_backend()获取的对象,和关注点1加粗样式调用的接口相同,但是这里却是没有传入congfig参数,一切都是默认的。
def _get_global_npu_backend():
global _global_npu_backend
if _global_npu_backend is not None:
return _global_npu_backend
if 'torchair' not in sys.modules:
raise AssertionError("Could not find module torchair. "
"Please check if torchair is removed from sys.modules." + pta_error(ErrCode.NOT_FOUND))
import torchair
_global_npu_backend = torchair.get_npu_backend()
return _global_npu_backend
接下来调用的函数是src_optimize,而src_optimize是通过_dynamo.py中的optimize赋值的。
src_optimize = optimize
看下完整的optimize函数
def optimize(
backend="inductor",
*,
nopython=False,
guard_export_fn=None,
guard_fail_fn=None,
disable=False,
dynamic=None,
):
"""
The main entrypoint of TorchDynamo. Do graph capture and call
backend() to optimize extracted graphs.
Args:
backend: One of the two things:
- Either, a function/callable taking a torch.fx.GraphModule and
example_inputs and returning a python callable that runs the
graph faster.
One can also provide additional context for the backend, like
torch.jit.fuser("fuser2"), by setting the backend_ctx_ctor attribute.
See AOTAutogradMemoryEfficientFusionWithContext for the usage.
- Or, a string backend name in `torch._dynamo.list_backends()`
nopython: If True, graph breaks will be errors and there will
be a single whole-program graph.
disable: If True, turn this decorator into a no-op
dynamic: If True, upfront compile as dynamic a kernel as possible. If False,
disable all dynamic shapes support (always specialize). If None, automatically
detect when sizes vary and generate dynamic kernels upon recompile.
Example Usage::
@torch._dynamo.optimize()
def toy_example(a, b):
...
"""
其中backend的注释
backend:可以是以下两种情况之一:
- 要么,它是一个函数或可调用对象,接收一个 torch.fx.GraphModule 和 example_inputs,并返回一个能够更快执行该计算图的 Python 可调用对象。
你也可以通过设置 backend_ctx_ctor 属性,为 backend 提供额外的上下文信息,例如:torch.jit.fuser(“fuser2”)。
使用方式请参见:AOTAutogradMemoryEfficientFusionWithContext。- 要么,它是一个字符串,表示后端名称,这个名称必须在 torch._dynamo.list_backends() 返回的列表中。
当前npu下,属于第一种情况的backend。补充完整调用栈:
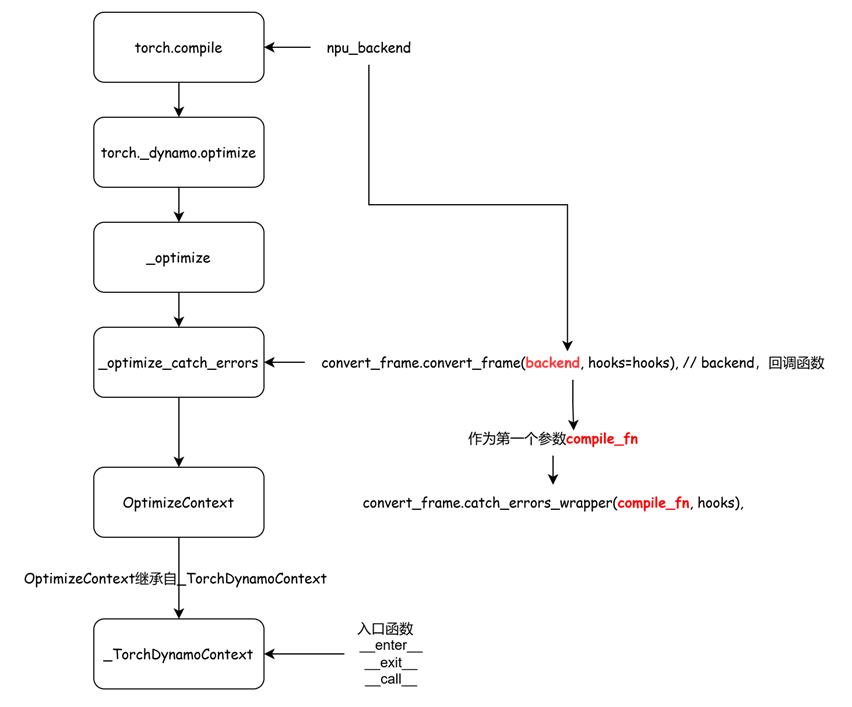
optimize最终使能到的对象是_TorchDynamoContext。
torch._dynamo.optimize的流程就走完了。再回到
return torch._dynamo.optimize(backend=backend, nopython=fullgraph, dynamic=dynamic, disable=disable)(model)
关注最后一个参数model,意思也就是给_TorchDynamoContext传入参数model,会触发调用_TorchDynamoContext的__call__方法。由于例子中的Model()是个fn, torch.nn.Module对象,因此走到下面的代码分支
... 省略
if isinstance(fn, torch.nn.Module):
mod = fn
new_mod = OptimizedModule(mod, self)
# Save the function pointer to find the original callable while nesting
# of decorators.
new_mod._torchdynamo_orig_callable = mod.forward
# when compiling torch.nn.Module,
# provide public api OptimizedModule.get_compiler_config()
assert not hasattr(new_mod, "get_compiler_config")
new_mod.get_compiler_config = get_compiler_config
return new_mod
... 省略
返回的是一个OptimizedModule实例对象。
new_mod = OptimizedModule(mod, self)
特别要注意OptimizedModule对象,实例创建的过程其实包含一段执行逻辑,先看流程图
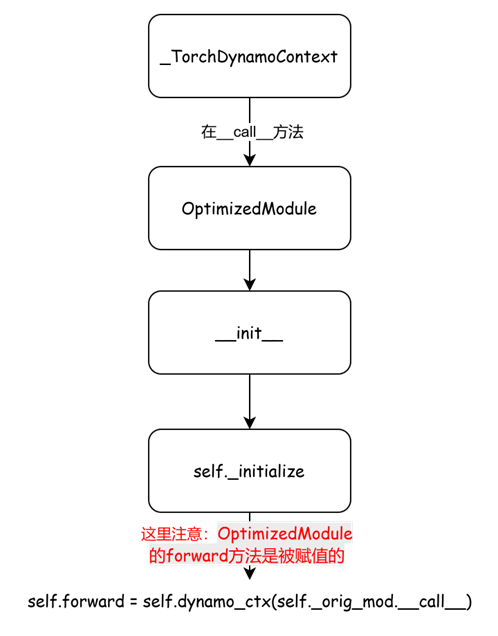
再给出代码:
class OptimizedModule(torch.nn.Module):
"""
Wraps the original nn.Module object and later patches its
forward method to optimized self.forward method.
"""
_torchdynamo_orig_callable: Callable[..., Any]
get_compiler_config: Callable[[], Any]
def __init__(self, mod: torch.nn.Module, dynamo_ctx):
super().__init__()
# Installs the params/buffer
self._orig_mod = mod
self.dynamo_ctx = dynamo_ctx
self._initialize()
def _initialize(self):
# Do this stuff in constructor to lower overhead slightly
if isinstance(self._orig_mod.forward, types.MethodType) and trace_rules.check(
self._orig_mod.forward
):
# This may be a torch.nn.* instance in trace_rules.py which
# won't trigger a frame evaluation workaround to add an extra
# frame we can capture
self.forward = self.dynamo_ctx(external_utils.wrap_inline(self._orig_mod))
else:
# Invoke hooks outside of dynamo then pickup the inner frame
self.forward = self.dynamo_ctx(self._orig_mod.__call__)
if hasattr(self._orig_mod, "_initialize_hook"):
self 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2994
2994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









