



本文主要是对官网中一些难以理解和混淆的内容做一些分析和记录。
1 AscendC编程接口
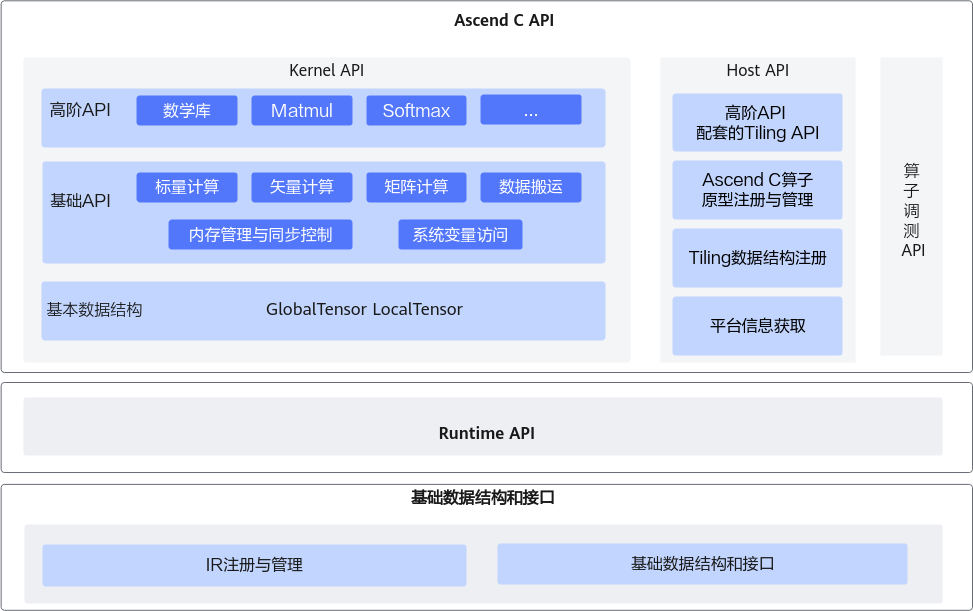
Ascend C提供一组类库API,开发者使用标准C++语法和类库API进行编程。Ascend C编程类库API示意图如下所示,分为:
- Kernel API:用于实现算子核函数的API接口。包括:
- 基本数据结构:kernel API中使用到的基本数据结构,比如GlobalTensor和LocalTensor。
- 基础API:实现对硬件能力的抽象,开放芯片的能力,保证完备性和兼容性。标注为ISASI(Instruction Set Architecture Special Interface,硬件体系结构相关的接口)类别的API,不能保证跨硬件版本兼容。
- 高阶API:实现一些常用的计算算法,用于提高编程开发效率,通常会调用多种基础API实现。高阶API包括数学库、Matmul、Softmax等API。高阶API可以保证兼容性。
- Host API:
- 高阶API配套的Tiling API:kernel侧高阶API配套的Tiling API,方便开发者获取kernel计算时所需的Tiling参数。
- Ascend C算子原型注册与管理API:用于Ascend C算子原型定义和注册的API。
- Tiling数据结构注册API:用于Ascend C算子TilingData数据结构定义和注册的API。
- 平台信息获取API:在实现Host侧的Tiling函数时,可能需要获取一些硬件平台的信息,来支撑Tiling的计算,比如获取硬件平台的核数等信息。平台信息获取API提供获取这些平台信息的功能。
- 算子调测API:用于算子调测的API,包括孪生调试,性能调测等。
进行Ascend C算子Host侧编程时,需要使用基础数据结构和API,请参考基础数据结构与接口;完成算子开发后,需要使用Runtime API完成算子的调用,请参考“AscendCL API(C)”。
说明
Ascend C API所在头文件目录为:
基础API:${INSTALL_DIR}/include/ascendc/basic_api/interface
高阶API:(注意,如下目录头文件中包含的接口如果未在资料中声明,属于间接调用接口,开发者无需关注)
- ${INSTALL_DIR}/include/ascendc/highlevel_api/lib
- ${INSTALL_DIR}/include/tiling
${INSTALL_DIR}请替换为CANN软件安装后文件存储路径。若安装的Ascend-cann-toolkit软件包,以root安装举例,则安装后文件存储路径为:/usr/local/Ascend/ascend-toolkit/latest。
全量的API接口,可以参考:Ascend C API列表
2 基础API概述
对于基础API,主要分为以下几类:
- 标量计算API,实现调用Scalar计算单元执行计算的功能。
- 矢量计算API,实现调用Vector计算单元执行计算的功能。
- 矩阵计算API,实现调用Cube计算单元执行计算的功能。
- 数据搬运API,计算API基于Local Memory数据进行计算,所以数据需要先从Global Memory搬运至Local Memory,再使用计算API完成计算,最后从Local Memory搬出至Global Memory。执行搬运过程的接口称之为数据搬运API,比如DataCopy接口。
- 内存管理与同步控制API
- 内存管理API,用于分配管理内存,比如AllocTensor、FreeTensor接口;
- 同步控制API,完成任务间的通信和同步,比如EnQue、DeQue接口。不同的API指令间有可能存在依赖关系,从抽象硬件架构可知,不同的指令异步并行执行,为了保证不同指令队列间的指令按照正确的逻辑关系执行,需要向不同的组件发送同步指令。同步控制API内部即完成这个发送同步指令的过程,开发者无需关注内部实现逻辑,使用简单的API接口即可完成。
对于基础API中的计算API,根据对数据操作方法的不同,分为以下几种计算方式:
- 整个tensor参与计算:通过运算符重载的方式实现,支持“+, -, *, /, |, &, <, >, <=, >=, ==, !=”,实现计算的简化表达。例如:
dst=src1+src2 - tensor前n个数据计算:针对源操作数的连续n个数据进行计算并连续写入目的操作数,解决一维tensor的连续计算问题。例如:
Add(dst, src1, src2, n); - tensor高维切分计算:功能灵活的计算API,充分发挥硬件优势,支持对每个操作数的DataBlock Stride,Repeat Stride,Mask等参数的操作。
下图以矢量加法为例,展示了几种计算方式的特点。
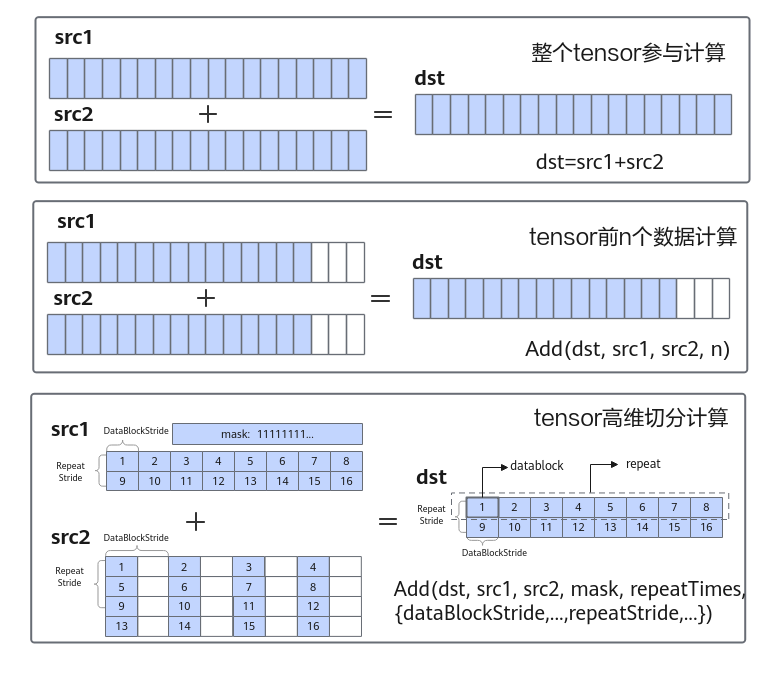
针对tensor高维切分计算进行打开理解。
2.1 tensor高维切分计算
使用tensor高维切分计算API可充分发挥硬件优势,支持开发者控制指令的迭代执行和操作数的地址间隔,功能更加灵活。
矢量计算通过Vector计算单元完成,矢量计算的源操作数和目的操作数均通过Unified Buffer(UB)来进行存储。Vector计算单元每个迭代会从UB中取出8个datablock(每个datablock数据块内部地址连续,长度32Byte,总共256Byte),进行计算,并写入对应的8个datablock中。
本文主要对mask参数进行理解说明
mask参数
mask用于控制每次迭代内参与计算的元素。可通过连续模式和逐bit模式两种方式进行设置。
- 连续模式:表示前面连续的多少个元素参与计算。数据类型为uint64_t。取值范围和源操作数的数据类型有关,数据类型不同,每次迭代内能够处理的元素个数最大值不同(当前数据类型单次迭代时能处理的元素个数最大值为:256 / sizeof(数据类型))。当操作数的数据类型占bit位16位时(如half/uint16_t),mask∈[1, 128];当操作数为32位时(如float/int32_t),mask∈[1, 64]。
具体样例如下:
// int16_t数据类型单次迭代能处理的元素个数最大值为256/sizeof(int16_t) = 128,mask = 64,mask∈[1, 128],所以是合法输入
// repeatTimes = 1, 共128个元素,单次迭代能处理128个元素,故repeatTimes = 1
// dstBlkStride, src0BlkStride, src1BlkStride = 1, 单次迭代内连续读取和写入数据
// dstRepStride, src0RepStride, src1RepStride = 8, 迭代间的数据连续读取和写入
uint64_t mask = 64;
AscendC::Add(dstLocal, src0Local, src1Local, mask, 1, { 1, 1, 1, 8, 8, 8 });
结果示例如下:
输入数据(src0Local): [1 2 3 ... 64 ...128]
输入数据(src1Local): [1 2 3 ... 64 ...128]
输出数据(dstLocal): [2 4 6 ... 128 undefined...undefined]
上述示例中,只有64个元素参与计算,65~128的元素是没有参与计算的,所以是undefined。
// int32_t数据类型单次迭代能处理的元素个数最大值为256/sizeof(int32_t) = 64,mask = 64,mask∈[1, 64],所以是合法输入
// repeatTimes = 1, 共64个元素,单次迭代能处理64个元素,故repeatTimes = 1
// dstBlkStride, src0BlkStride, src1BlkStride = 1, 单次迭代内连续读取和写入数据
// dstRepStride, src0RepStride, src1RepStride = 8, 迭代间的数据连续读取和写入(8个表示连续,是根据UB每次取8个dataBlock)
uint64_t mask = 64;
AscendC::Add(dstLocal, src0Local, src1Local, mask, 1, { 1, 1, 1, 8, 8, 8 });
结果示例如下:
输入数据(src0Local): [1 2 3 ... 64]
输入数据(src1Local): [1 2 3 ... 64]
输出数据(dstLocal): [2 4 6 ... 128]
- 逐bit模式:可以按位控制哪些元素参与计算,bit位的值为1表示参与计算,0表示不参与。
mask为数组形式,数组长度和数组元素的取值范围和操作数的数据类型有关。当操作数为16位时,数组长度为2,mask[0]、mask[1]∈[0, 2^64-1]并且不同时为0;当操作数为32位时,数组长度为1,mask[0]∈(0, 2^64-1];当操作数为64位时,数组长度为1,mask[0]∈(0, 2^32-1]。
具体样例如下:
// 数据类型为int16_t
uint64_t mask[2] = {6148914691236517205, 6148914691236517205};
// repeatTimes = 1, 共128个元素,单次迭代能处理128个元素,故repeatTimes = 1。
// dstBlkStride, src0BlkStride, src1BlkStride = 1, 单次迭代内连续读取和写入数据。
// dstRepStride, src0RepStride, src1RepStride = 8, 迭代间的数据连续读取和写入。
AscendC::Add(dstLocal, src0Local, src1Local, mask, 1, { 1, 1, 1, 8, 8, 8 });
结果示例如下:
输入数据(src0Local): [1 2 3 ... 64 ...127 128]
输入数据(src1Local): [1 2 3 ... 64 ...127 128]
输出数据(dstLocal): [2 undefined 6 ... undefined ...254 undefined]
mask过程如下:
mask={6148914691236517205, 6148914691236517205}(注:6148914691236517205表示64位二进制数0b010101…01,mask按照低位到高位的顺序排布)

这里有没想过,为什么16位时,数组长度为2?
分析:当数据是16位,也就是2Byte,ub一次处理256Byte,也就是能处理128个数;那么掩码mask也就需要128个数,一个mask用64位表示,那么128个数,总共就需要2个这样的mask。
// 数据类型为int32_t
uint64_t mask[1] = {6148914691236517205};
// repeatTimes = 1, 共64个元素,单次迭代能处理64个元素,故repeatTimes = 1。
// dstBlkStride, src0BlkStride, src1BlkStride = 1, 单次迭代内连续读取和写入数据。
// dstRepStride, src0RepStride, src1RepStride = 8, 迭代间的数据连续读取和写入。
AscendC::Add(dstLocal, src0Local, src1Local, mask, 1, { 1, 1, 1, 8, 8, 8 });
结果示例如下:
输入数据(src0Local): [1 2 3 … 63 64]
输入数据(src1Local): [1 2 3 … 63 64]
输出数据(dstLocal): [2 undefined 6 … 126 undefined]
mask过程如下:
mask={6148914691236517205, 0}(注:6148914691236517205表示64位二进制数0b010101…01)

分析:当数据是32位,也就是4Byte,ub一次处理256Byte,也就是能处理64个数;那么掩码mask也就需要64个数,那么只需要一个mask用64位表示即可。
那么当操作数为64位时,数组长度为1,mask[0]∈(0, 2^32-1],这又如何分析呢?
分析见文章底部。
3 高阶API概述
高阶API一般是基于单核对常见算法的抽象和封装,用于提高编程开发效率,通常会调用多种基础API实现。高阶API包括数学库、Matmul、Softmax等API。
如下图所示,实现一个矩阵乘操作,使用基础API需要的步骤较多,需要关注格式转换、数据切分等逻辑;使用高阶API则无需关注这些逻辑,可以快速实现功能。
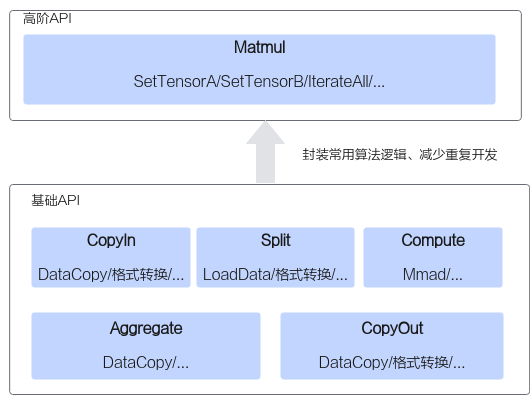
由于AI处理器的Scalar计算单元执行能力有限,为减少算子Kernel侧的Scalar计算,将部分计算在Host端执行,这需要编写Host端Tiling代码。注意,在程序中调用高阶API的Tiling接口或者使用高阶API的Tiling结构体参数时,需要引入依赖的头文件,示例如下:
#include "tiling/tiling_api.h"
问题:当操作数为64位时,数组长度为1,mask[0]∈(0, 2^32-1]?
分析:当数据是64位,也就是8Byte,ub一次处理256Byte,也就是能处理32个数;那么掩码mask也就需要32个数,那么只需要一个mask用32位表示即可。

















 412
412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









