







 文章介绍了PositionalEncoding类在Transformer模型中的作用,包括噪声添加和位置编码生成过程。同时提到了U-Net中skip_unet与unet的区别,主要在于上采样时的特征连接方式:unet使用cat连接,而skip_unet采用add连接。
文章介绍了PositionalEncoding类在Transformer模型中的作用,包括噪声添加和位置编码生成过程。同时提到了U-Net中skip_unet与unet的区别,主要在于上采样时的特征连接方式:unet使用cat连接,而skip_unet采用add连接。
代码:https://gitcode.com/geovectormatrix/dif-fusion/tree/main?utm_source=csdn_github_accelerator&isLogin=1
第一步:运行train_ddpm.py以训练红外和可见光图像的扩散模型。
第二步:运行train_fusion_head.py来训练融合模型。
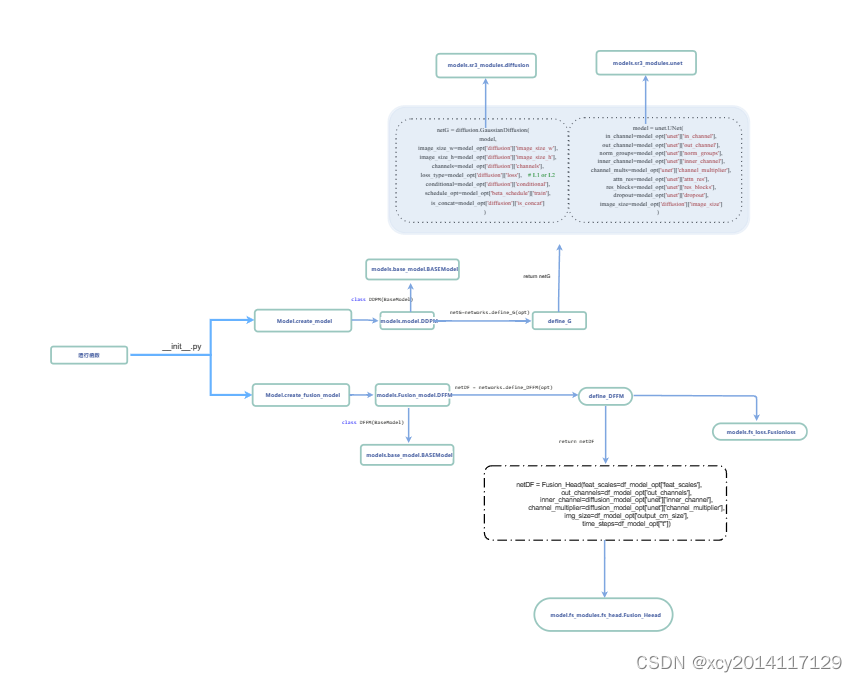
先将文件夹中各个函数之间的关系捋清楚
关于添加的噪声
class PositionalEncoding(nn.Module):
def init(self, dim):
super().init()
self.dim = dim
def forward(self, noise_level):
count = self.dim // 2
step = torch.arange(count, dtype=noise_level.dtype,
device=noise_level.device) / count
encoding = noise_level.unsqueeze(
1) * torch.exp(-math.log(1e4) * step.unsqueeze(0))
encoding = torch.cat(
[torch.sin(encoding), torch.cos(encoding)], dim=-1)
return encoding
这段代码定义了一个名为 PositionalEncoding 的类,它是一个继承自 nn.Module 的神经网络模块,通常用于在自然语言处理(NLP)中的Transformer模型中。这个类的主要目的是为了生成位置编码,这一技术是Transformer架构的一个关键部分,用于给模型提供单词在句子中位置的信息。由于Transformer模型本身不包含循环(如RNN)或卷积操作,因此需要这样的机制来理解单词顺序或位置关系。在这里,是为了添加噪声用的。
首先 构造函数 init:
参数 dim 表示每个位置编码的维度,即每个位置编码向量的大小。这里是每个随机要添加噪声的维度。
super().init() 调用是用来初始化继承自 nn.Module 的父类。
前向传播函数 forward:
输入参数 noise_level 通常是一个表示噪声水平的张量。
函数首先计算半维数 count(因为位置编码将由正弦和余弦函数的值组成,每个函数占一半的维度)。
接着,使用torch.arange函数创建一个范围从0到 count 的等差数列 step,参数 dtype=noise_level.dtype 指定生成的数列应该具有与 noise_level 张量相同的数据类型。参数 device=noise_level.device 确保生成的数列位于与 noise_level 相同的设备上(比如CPU或GPU),这样做是为了确保操作的兼容性和效率。/ count: 将上一步生成的等差数列中的每个元素除以 count,这一操作的目的是归一化数列中的值到0和1之间。这种归一化是生成位置编码比例因子的重要步骤,因为这些比例因子随后会用于通过指数衰减来调整位置编码的频率,使得模型可以有效地捕捉到位置信息。最终通过这个数列生成每个维度的位置编码的比例因子。
随后它通过将噪声水平 noise_level 调整形状并与指数衰减后的步长 step 相乘,来创建位置编码。具体过程为:
noise_level.unsqueeze(1):unsqueeze(1) 方法的作用是在 noise_level 张量的第1个维度(从0开始计数)处增加一个维度,即将其形状从 [n] 转变为 [n, 1],其中 n 是 noise_level 的原始长度。
torch.exp(-math.log(1e4) * step.unsqueeze(0)):
step.unsqueeze(0) 方法是在 step 张量的第0个维度增加一个维度,即从 [count] 转变为 [1, count]。*这一操作是为了使 step 张量**的形状与 noise_level.unsqueeze(1) 保持一致,即满足矩阵的要求[n,1]×[1.count],这样 noise_level的每个元素都能乘一个衰减因子。其中还乘了一个-math.log(1e4) 是一个负的对数操作,用于计算指数衰减的基础。这里 1e4 是一个常数,选择这个值是为了控制位置编码的衰减速率。torch.exp(…) 函数计算指数函数,用于生成每个位置的衰减因子。这里,衰减因子是通过对 -math.log(1e4) * step 的结果应用指数函数得到的,这样可以保证位置编码随位置的增加而指数级衰减。这样做的目的是在不同的位置编码之间创造足够的区分度,同时保持较远位置之间的相对关系稳定。
最后,使用正弦和余弦函数对这些编码进行变换,并将它们拼接在一起,形成完整的位置编码。位置编码通过正弦和余弦函数生成,这使得模型能够很容易地通过编码学习到位置信息,并且能够处理比训练时见过的句子更长的句子。这种编码方法的一个优点是相对位置信息的编码方式,使得模型能够更好地捕捉到序列中元素之间的位置关系。
这里可以理解为对图像当前位置所需要添加的噪声方式,离这里位置越近,添加的噪声水平越高,相反亦然。
U-Net
该代码部分有个skip_unet和unet,下面简述两者的区别:(这里直接画的是流程图)
在我理解unet网络使用的是cat连接,在上采样的时候,将下采样的特征cat进来
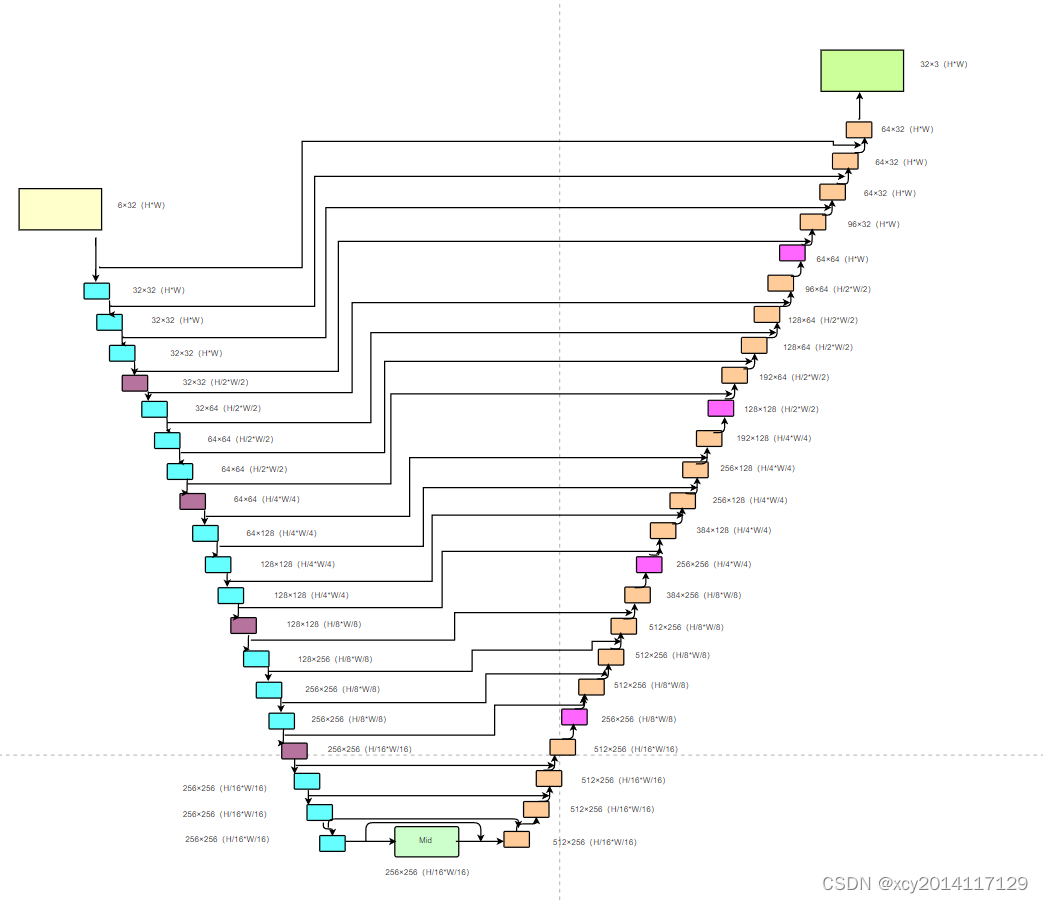
skip_unett网络使用的是add连接,在上采样的时候,将下采样的特征cat进来。


















 54
54

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









