




本文提到一些方法使用共享编码器从源图像中提取特征,并且采取手工制作的融合策略。我们的目的是让编码器从源图像中提取出不同的特征,因此我们在编码器中引入了类嵌入分支,对不同模态的特征进行建模,并根据输入模态自适应缩放中间特征。融合策略方面,使用了通道和空间注意力机制对不同模态的特征图进行加权。
训练思路与RFN-NEST相同,两阶段训练,损失不同。
代码不公开
发表自Neurocomputing 2023
作者的想法应该是让编码器学习不同模态图像独特的特征,因此使用了一个类嵌入向量,通过第一阶段的训练,迫使编码器对不同图像建模,使用了一个交叉熵损失,所以这里的训练数据作者应该进行了修改,比如手动标注类别。
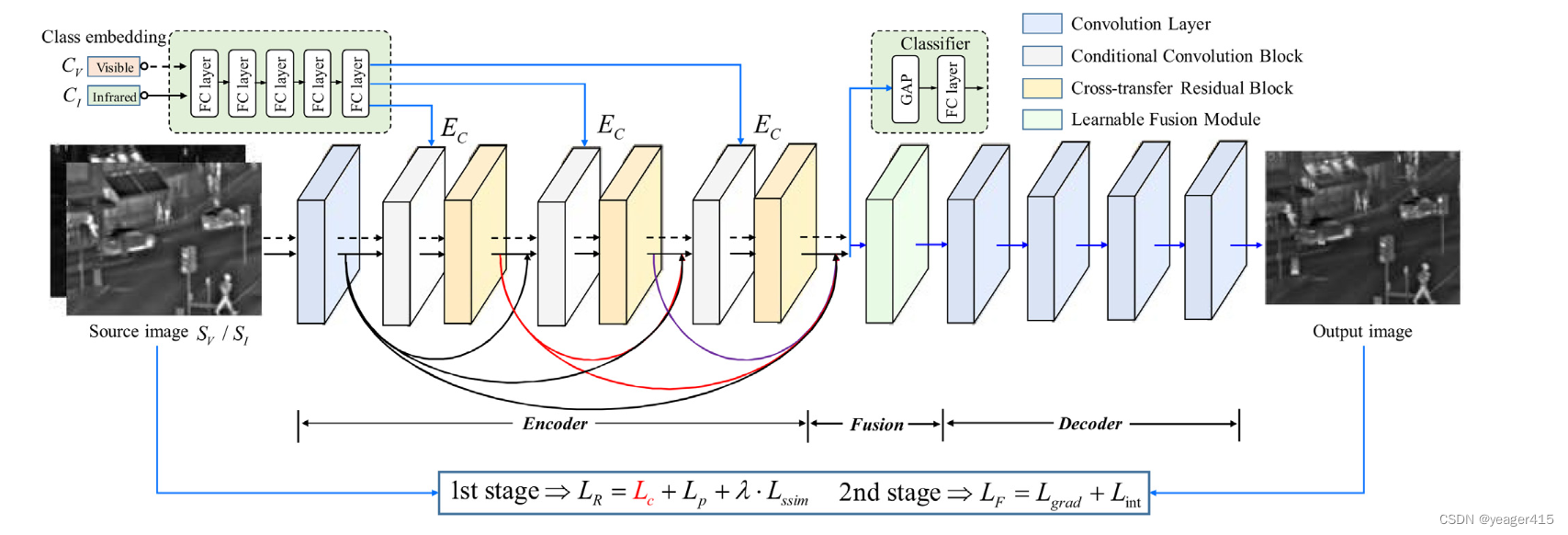
第一阶段训练:
IR和VIS分别提取特征,就是双分支
没有融合层,初始化类嵌入向量
(训练后就与encoder一起固定了)
这两个初始化的向量经过5个全连接层得到Ec,然后注入网络部分的3个CCB
每一层的结果concat起来送入classifier
编码器通过密集连接将调整后的特征进行连接并发送到小分类器头部进行模态分类任务,该任务隐式引导编码器对不同模态进行不同的特征提取。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









