




 本文详细解析了DeeperBottleneck(简称DBA)架构在网络中的应用,特别是其在50层网络中的实现细节。文章介绍了DBA前的简单网络结构,包括卷积层、BN层、ReLU层及池化层,并深入探讨了conv2_x层的DBA结构,展示了从输入到输出的全过程。
本文详细解析了DeeperBottleneck(简称DBA)架构在网络中的应用,特别是其在50层网络中的实现细节。文章介绍了DBA前的简单网络结构,包括卷积层、BN层、ReLU层及池化层,并深入探讨了conv2_x层的DBA结构,展示了从输入到输出的全过程。
Deeper Bottleneck(瓶颈) Architectures
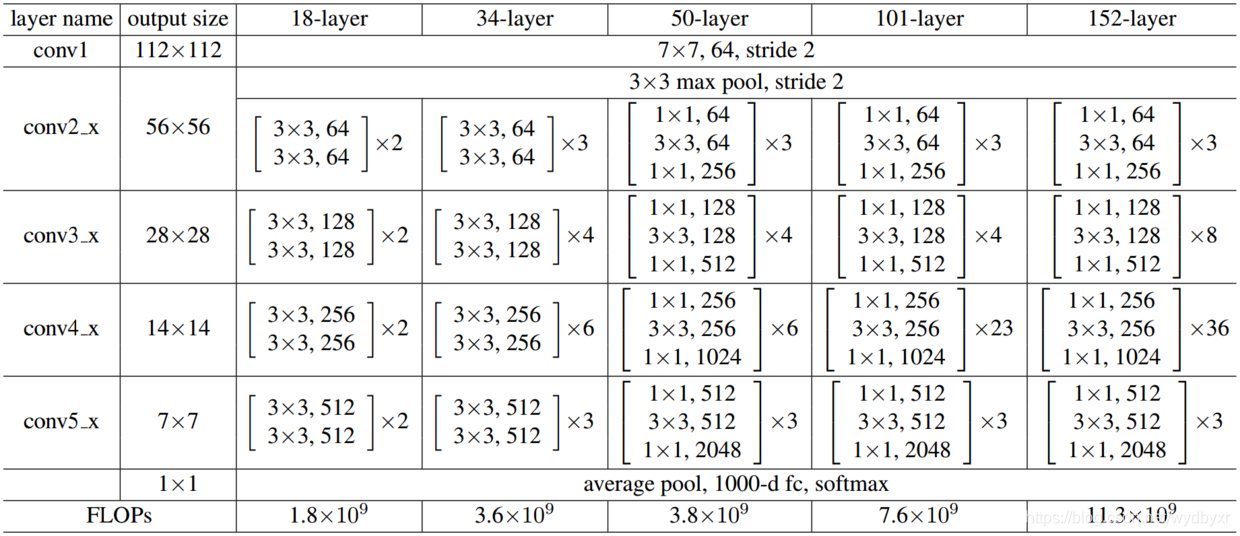
看50-layer那一栏,在进入到DBA层之前的网络比较简单,分别是:①卷积层"7×7, 64, stride 2"、②BN层、③ReLU层、④池化层"3×3 max pool, stride 2",最终的输出结果是一个大小为 [batch_size, height, width, kernels] 矩阵。
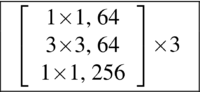
再看conv2_x层(即第一个bottleneck),该结构总共3×3=9层,可是原作毕竟篇幅有限,网络实现的细节不是很清楚,于是我就参考了Ryan Dahl的tensorflow-resnet程序源码,按照Ryan Dahl实现的ResNet,画出了DBA内部网络的具体实现,这个DBA是全网络中第一个DBA的前三层,输入的image大小为[batch_size,56,56,64],输出大小为[batch_size,56,56,256],如下图是DBA的结构(Bottleneck V1 ):


















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









