 开源MoE模型:GPT4背后的计算效率秘密
开源MoE模型:GPT4背后的计算效率秘密





 本文探讨了开源MoE模型如何通过动态选择专家模型来降低训练和推理的计算需求,如GPT4所示,这不仅节省了GPU资源,而且有助于超大模型的训练。作者还指出,尽管与集成学习有相似之处,MoE的核心目标是解决资源效率问题而非幻觉问题。
本文探讨了开源MoE模型如何通过动态选择专家模型来降低训练和推理的计算需求,如GPT4所示,这不仅节省了GPU资源,而且有助于超大模型的训练。作者还指出,尽管与集成学习有相似之处,MoE的核心目标是解决资源效率问题而非幻觉问题。
最近由于一些开源MoE模型的出现,带火了开源社区,为何?因为它开源了最有名气的GPT4的模型结构(OPEN AI),GPT4为何那么强大呢?看看MoE模型的你就知道了。
MoE模型结构:
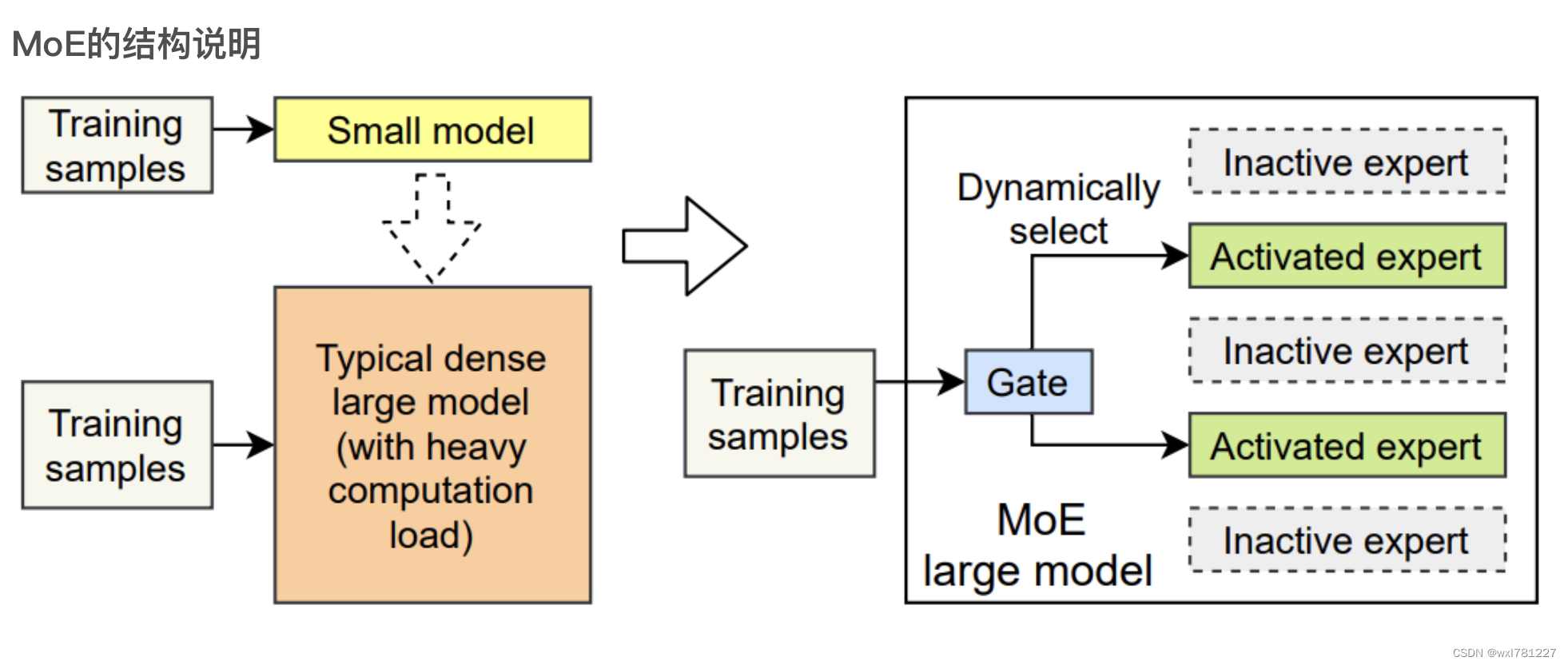
图中,显示了3类模型的结构,小模型,典型的稠密大模型和MoE模型。
MoE模型在训练的时候,是动态选择专家模型的,即有些专家模型是不被激活的。因此就会减少训练的计算量,降低计算所需要的GPU(8B*7的模型,本应该需要56B模型所需的GPU,使用专家模型结构后,装载模型需要47B模型所需的GPU,训练时只需要14B模型的GPU)同时参数是共享的,也会进一步的减少GPU(减少到12B模型的GPU占用)。
模型在推理时,并不是所有的专家模型被激活,降低了GPU的占用。
模型越大,能力更强是共识,因为参数越多,拟合能力越强。此类模型容易过拟合。
有人可能会说了,这不就是集成学习的思想吗?是的。下面来看看与集成学习的差异。 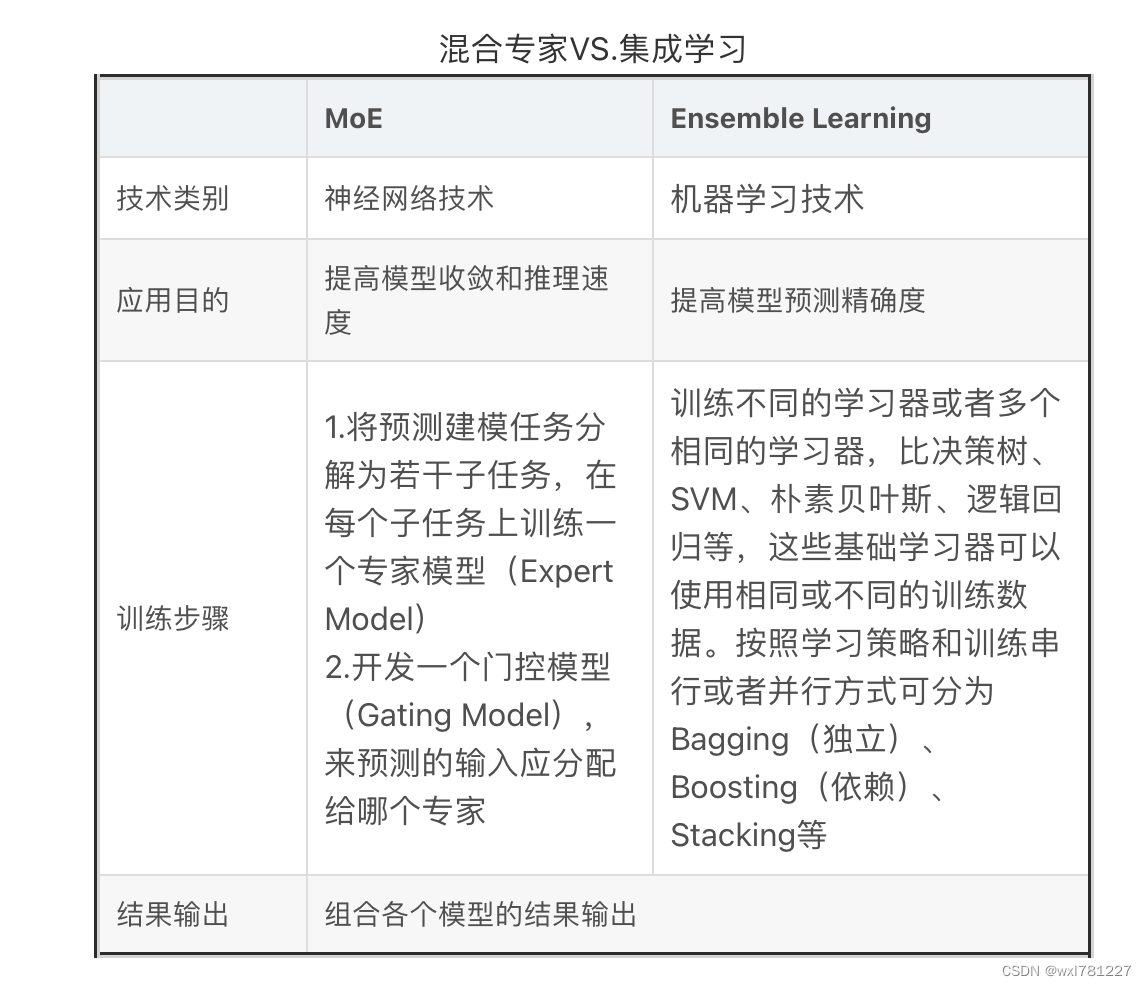
从上图可以看到,虽然使用的技术不同,目的不同,训练步骤不同,但结果都是组合各个模型的结果进行输出。这个就是集成学习的核心思想。
那么它核心解决什么问题呢?
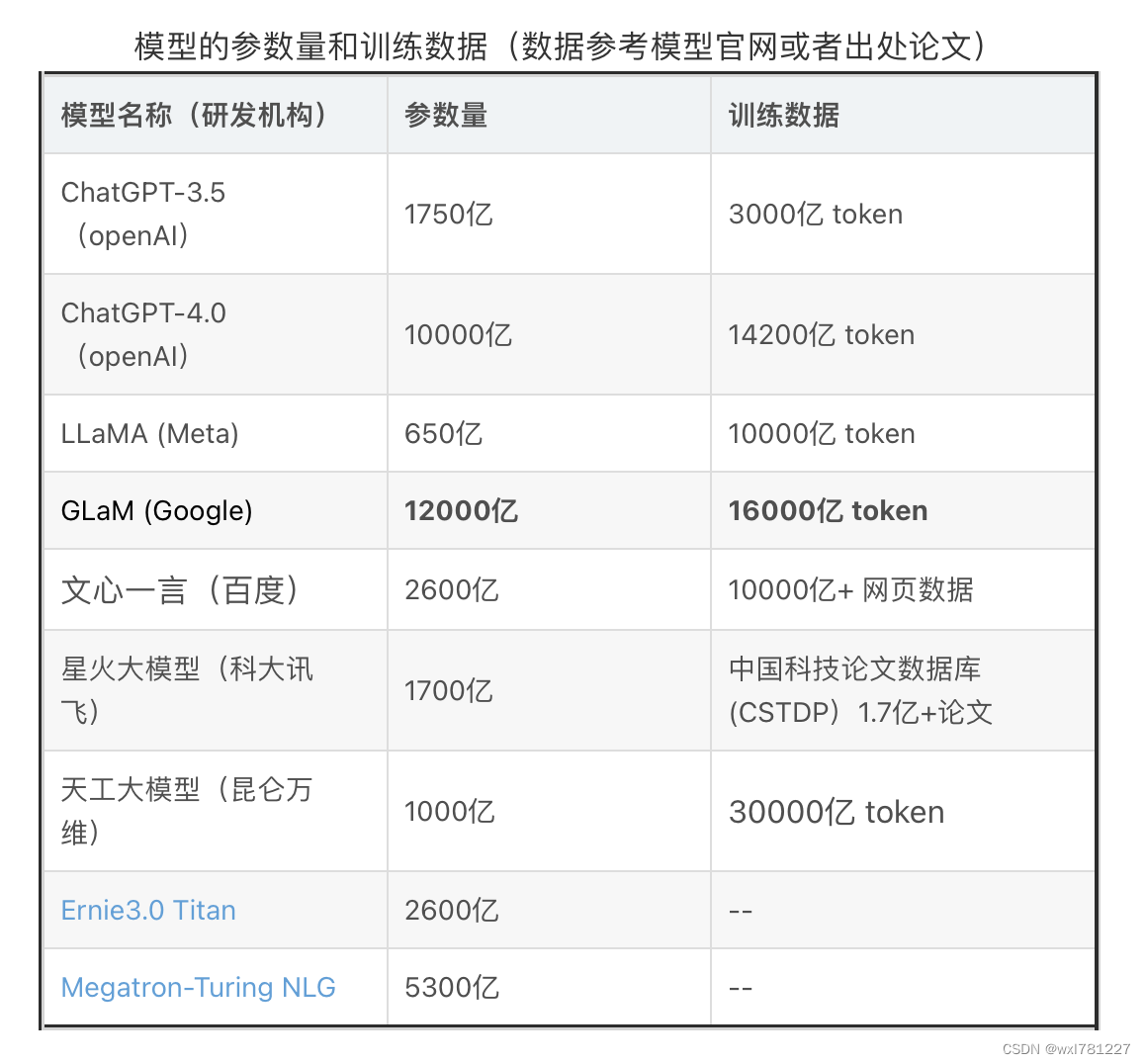
它是一种为了搞超大模型时降低资源的有效方法。GPT4和GLaM都是MoE结构的模型,MoE模型并没有解决幻觉的问题,只是在超大的模型上,减少了训练和推理的计算,降低了训练和推理的成本,让专家模型更专注。


















 2704
2704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











