









 本文介绍了一种基于图卷积网络的非线性方法,用于将3D人脸形状和表情特征进行分离。该方法通过使用VAE结构实现特征分解,并通过融合模块重构原始网格。
本文介绍了一种基于图卷积网络的非线性方法,用于将3D人脸形状和表情特征进行分离。该方法通过使用VAE结构实现特征分解,并通过融合模块重构原始网格。
标题:Disentangled Representation Learning for 3D Face Shape
这篇文章处理的主要问题就是将3D人脸分解成形状和表情特征。现有的处理方法大都是基于欧几里得表示的线性方法,但是事实上面部变化的特征并不是线性的,因此本文提出了一种基于非线性的表示表情和面部形状的方法。这个方法是基于图卷积网络的。
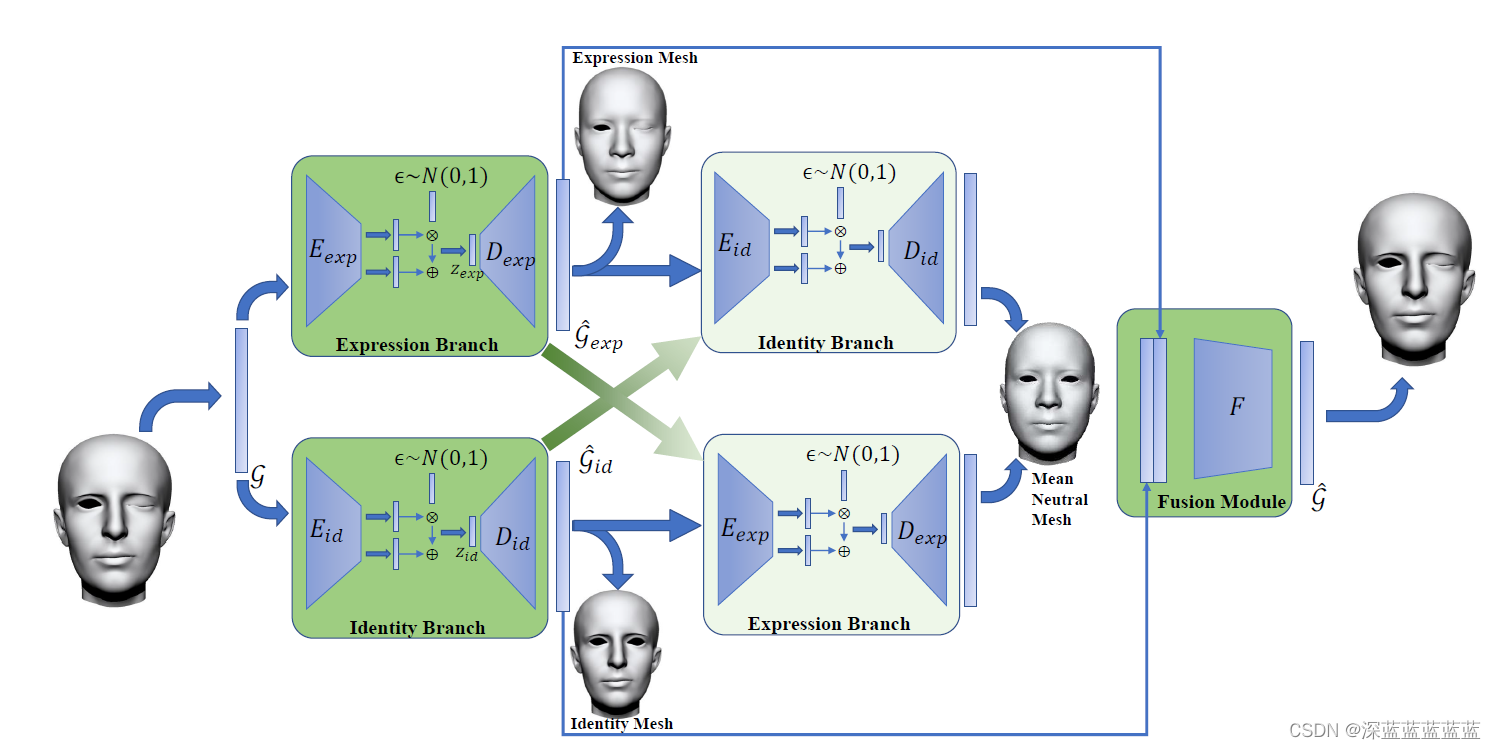
整体流程如图所示,分为两个部分:decomposition network和fusion network
decomposition network就是为了把表情和形状特征分离开来。这里用了一个VAE的结构,形状分支出来的就是只留有形状的表示,而没有表情的。表情分支出来的就是只留有表情形状而脸是平均的。
因此可以看到decomposition network每个分支都会走两遍VAE,第一遍是将特征分离出来,第二遍是将没分离的那个特征给提取出来(对于expression branch来说就是shape,对于identity branch来说就是expression),这时候提取出来的理应就是mean face和netural expression,因此ground truth就是mean netural mesh。
fusion network就更简单了,就是将提取出来的feature拼接之后丢到fusion module里,和原始的mesh做个重构损失即可。
参考链接:人脸识别-3D:Disentangled Representation Laerning for 3D Face Shape_alfred_torres的博客-优快云博客

















 52
52

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









