








目录
深度学习是什么?
1、监督学习
所有输入数据都有确定的对应输出数据,在各种网络架构中,输入数据和输出数据的节点层都位于网络的两端,训练过程就是不断地调整它们之间的网络连接权重。
- 标准的神经网络(NN)可用于训练房子特征和房价之间的函数,卷积神经网络(CNN)可用于训练图像和类别之间的函数,循环神经网络(RNN)可用于训练语音和文本之间的函数。
- 深度学习依赖于大数据的出现,神经网络的训练需要大量的数据;而大数据本身也反过来促进了更大型网络的出现。
- 深度学习研究的一大突破是新型激活函数的出现,用 ReLU 函数替换sigmoid 函数可以在反向传播中保持快速的梯度下降过程,sigmoid 函数在正无穷处和负无穷处会出现趋于零的导数,这正是梯度消失导致训练缓慢甚至失败的主要原因。要研究深度学习,需要学会「idea—代码—实验—idea」的良性循环。
2、浅层网络特点
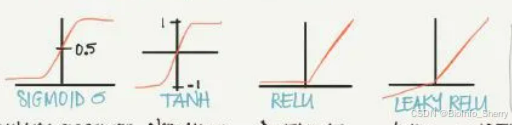
- 这里介绍了不同激活函数的特点:
- ①sigmoid:sigmoid 函数常用于二分分类问题,或者多分类问题的最后一层,主要是由于其归一化特性。sigmoid 函数在两侧会出现梯度趋于零的情况,会导致训练缓慢。
- ②tanh:相对于 sigmoid,tanh 函数的优点是梯度值更大,可以使训练速度变快。
- ③ReLU常用:可以理解为阈值激活(spiking model 的特例,类似生物神经的工作方式),该函数很常用,基本是默认选择的激活函数,优点是不会导致训练缓慢的问题,并且由于激活值为零的节点不会参与反向传播,该函数还有稀疏化网络的效果。
- ④Leaky ReLU:避免了零激活值的结果,使得反向传播过程始终执行,但在实践中很少用。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1207
1207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









