



摘要
| 该团队提出了一种名为“Prototype Antithesis (PA)”的小样本增量学习方法,旨在解决生物识别领域中模型对新旧物种混淆的问题。PA方法通过分层级的特征学习,使模型能够同时捕捉物种独有的特征和家族共享的特征。 具体来说,PA包含两个核心模块:残差类别原型学习(RPL)和残差类别原型混合(RPM)。RPL在元学习阶段优化物种独有的特征和家族共享特征的分类器,而RPM在增量学习阶段通过混合新物种特征与残差类别原型生成合成样本,驱使模型关注新旧物种的差异化特征。 实验结果表明,PA方法在多个公开数据集(如CUB200、PlantVillage和Tree-of-Life)上显著减少了新旧类别错误分类的情况,提升了模型的泛化能力和抗遗忘能力,为生物分析和小样本增量学习领域提供了重要启发。 论文地址: https://openreview.net/pdf?id=bRqaHn3J5I |

研究背景
深度学习已经广泛应用于各个领域的识别任务中,通常做法是利用领域的数据训练一个分类模型,使得模型能够对输入的数据进行准确的分类。但是在生物识别领域,会有新的或者变异的物种(species)出现,这些物种可能会和已有物种非常相似,特别是当它们属于同一个大家族(family)时。这就会导致一个问题,在已有物种上训练好的模型,在面对这些新物种的时候,往往会将其与相似的旧物种混淆,而新物种样本量通常比较少,这进一步加剧了模型学习的困难。

方法概述
为了解决以上问题,此论文提出了一种叫做 prototype antithesis 的小样本增量学习方法,该方法由 Residual Prototype Learning (RPL) 和 Residual Prototype Mixing (RPM) 两部分组成。
RPL驱使模型在元学习阶段,同时学习每个物种(species)独有的特征,以及大家族(family)中不同物种共有的特征;RPM在模型增量学习新物种的时候,将之前学习到的共有特征与新物种特征进行混合,在生成更多样本的同时,驱使模型更加关注新旧物种之间差异化的特征部分。
通过将 RPL 和 RPM 有机结合,能够使模型在持续进化的同时,更加准确地区分相似的新旧物种。论文同时从理论和实验的角度验证了方法的有效性,并在多个数据集上取得了领先现有方法的性能。

方法亮点
此论文提出了一种多层级的表征学习方法,名为“Prototype Antithesis”,巧妙利用“species-level”和“family-level”的标签,驱使网络学习更加精细且差异化的特征,并将其与新类别的学习相结合,提升模型学习效果的同时降低模型遗忘。它主要由 RPL 和 RPM 两部分组成,如图1所示。其中 RPL 是在元学习阶段进行的,RPM是在增量学习阶段进行的,具体步骤如下:
step1:在元学习阶段,此方法采用“残差类别原型学习策略”(RPL)来进行模型的训练。残差类别原型学习可以进一步分为两个步骤,在第一步骤,给定充足的基础物种数据
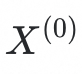
,我们采用特征提取器对这些数据进行特征提取,得到特征
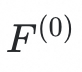
,这些特征被送入类别原型分类器

进行分类,得到分类结果
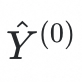
并计算其与“species-level”标签
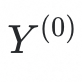
的交叉熵损失进行梯度反传,优化特征提取器和类别原型分类器的参数;
step2:在残差类别原型学习的第二步骤,会计算特征
与分类器中相应类别原型的差值,得到残差特征R,这些残差特征被输入残差类别原型分类器
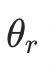
中进行分类,得到分类结果
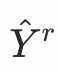
并计算其与“family-level”标签
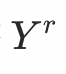
的交叉熵损失,同时进行step1中的过程,将step1和step2中的损失函数相加后进行梯度反传,优化特征提取器和残差类别原型分类器的参数;通过step1和step2的同时双向优化,类别原型
和残差类别原型
将分别向“物种独有”和“家族共享”的特征收敛;
step3:在增量学习阶段,此方法采用“残差类别原型混合策略”来进行新物种的学习。给定少量新物种训练样本
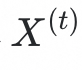
,在对这些样本进行特征提取之后,将其与step2中优化得到的残差类别原型通过线性相加的方式进行混合,得到混合后的特征用于模型训练,而其分类标签为原始特征的“species-level”标签。这种学习模式能够驱使网络关注新旧物种之前最具差异性的部分,高效学习新物种数据的同时减少类别混淆,降低模型遗忘。并且通过特征混合生成的样本能够减少模型由于样本量过少带来的过拟合问题;
step4:经过step1,2,3后,模型在新旧物种上均进行了训练,优化得到的模型可直接用于新旧物种数据的处理分析。处理流程如下:将输入数据通过特征提取器提取特征,然后将特征输入类别原型分类器,输出预测结果。
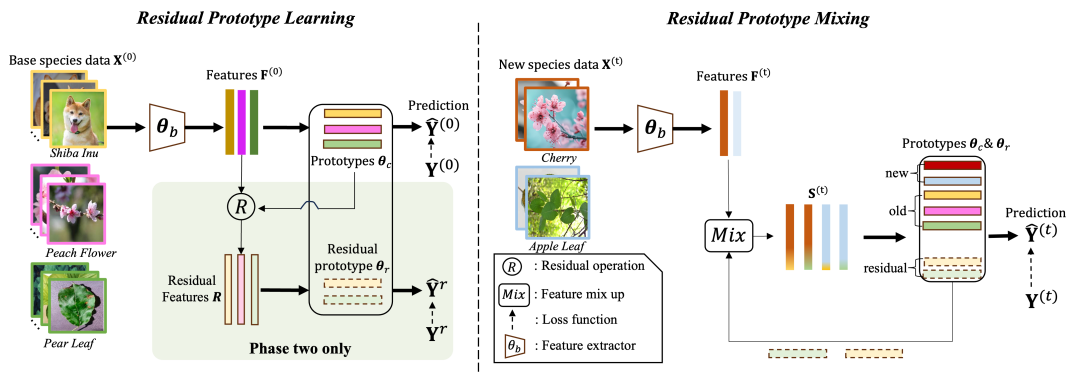
图1. Prototype Antithesis方法框架图

实验结果
此方法在多个公开数据集(例如CUB200,PlantVillage,Tree-of-Life)上均取得了不错的性能,且显著减少了新旧类别错误分类的情况。具体可见表1和图2。
表1. 在CUB200数据集上的性能对比
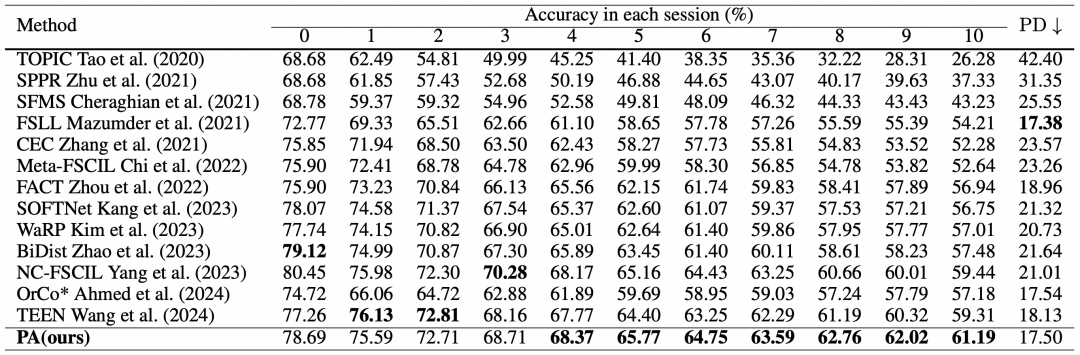
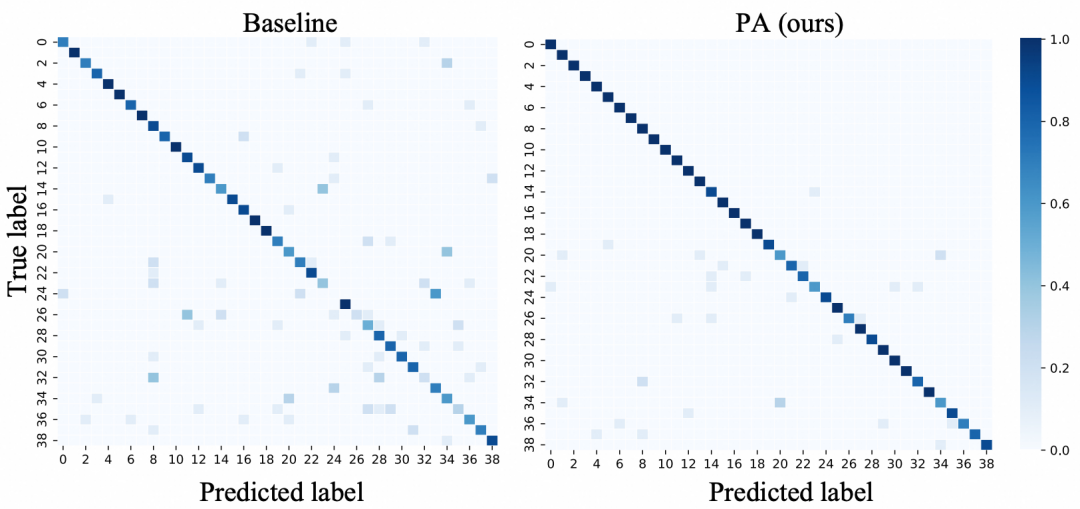
图2. 新旧类别分类结果混淆矩阵对比,相比Baseline显著减少了新旧类别错误分类的情况
此论文提出了一种“Prototype Antithesis”的小样本增量学习方法,通过分层式的表征学习,驱使模型同时学习“物种独有”与“家族共享”的特征,并将其与新类别学习有机结合,提升模型泛化能力的同时减少模型遗忘,对生物分析及小样本增量学习领域都具有不错的启发效果。

















 3034
3034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









