



摘要
| 大型语言模型(LLM)在自然语言处理领域取得了显著进步,但要深入理解这些模型的工作机制仍然是一项挑战。目前,许多研究都使用“相似性分析”方法来探讨模型内部的表征特征,但这些方法通常忽略了直接分析权重矩阵的重要性。 我们的研究则直接聚焦于权重矩阵本身,而不仅仅是表征特征。因为在 Transformer架构中,表征相似并不意味着权重矩阵也一定相似。特别是由于残差连接的存在,每个层的输出直接依赖于输入,这会造成不同层之间表征的相关性,即便这些层的权重矩阵本质上可能不同。因此,仅靠表征分析无法完全揭示模型内部真实的结构特性。此外,现有的一些相似性测量方法,比如CCA、SVCCA或线性CKA,对于正交矩阵并不敏感。这意味着,即使权重矩阵之间存在明显差异,这些方法也可能给出相似甚至相同的测量结果,这限制了我们对模型结构的准确理解。 针对这些问题,我们提出了一种新的权重矩阵相似性测量方法DOCS。DOCS能够有效地区分不同权重矩阵之间的差异,尤其克服了传统方法在面对正交矩阵时的局限性。通过广泛的实验,我们验证了 DOCS 在分析 LLM 权重矩阵时的有效性和可靠性,进一步利用 DOCS 方法,我们在多个开源LLM中发现了一些有趣的现象。 |

Method
下面展示的是我们的 DOCS 方法


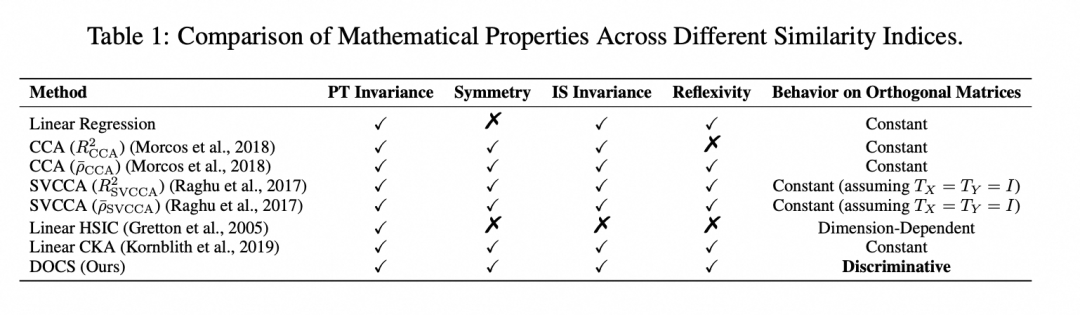
Mathematical properties characterization
一些相关研究表明,LLM权重矩阵 往往具备高度的正交特性。因此,一个有效的相似性指标必须能有效地区分正交矩阵。
根据相似性指标在正交矩阵上的表现,我们将其行为分为三种类型:
-
第一种是对正交矩阵呈现“常数性”:也就是无论正交矩阵如何变化,指标始终输出同一个常数。
-
第二种是“依赖于维度”:指标输出的数值仅与矩阵的维度相关,而与具体矩阵内容无关。
-
第三种,也是我们最期望的特性,叫做“可区分性”:即指标能够有效地区分不同的正交矩阵,输出不同的数值,从而体现权重矩阵之间的本质差异。
此外,我们还刻画了其他几个重要的数学性质:

我们的理论结果总结如下表:

Numerical experiments
Comparison of different methods
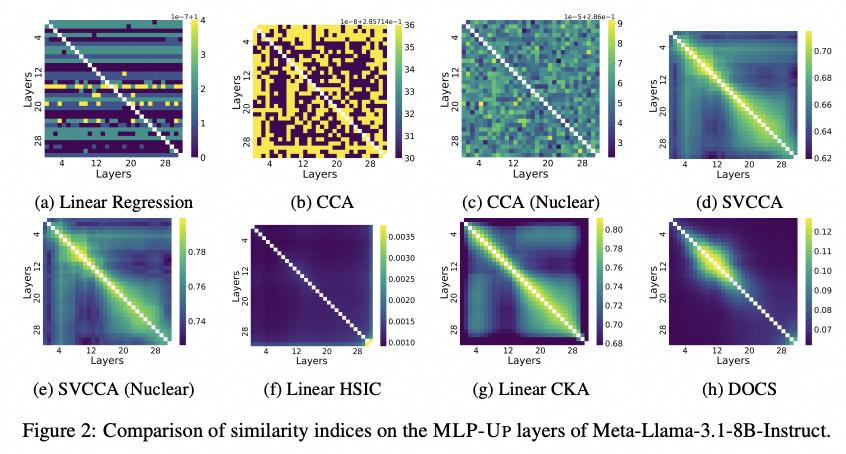
我们首先对集中方法进行了实验比较。我们对 Meta-Llama-3.1-8B-Instruct 模型的\textsc{MLP-Up}层,应用了八种不同的相似度指标进行比较。从结果的热力图中我们可以观察到,Linear Regression,CCA和CCA (Nuclear)等指标表现出明显的噪声,没有清晰的结构特征。而SVCCA、SVCCA (Nuclear)和Linear CKA则显示出更清晰的结构,尤其表现为明显的块对角结构,说明相邻层之间存在较高的参数相似性。
这种结果符合我们的预期,因为 Transformer 模型中相邻的层通常由于信息处理的连续性而表现出更强的参数相关性。然而,这些方法也存在一些离散的小区块和条纹,且这些相似性在数值上相差较小,这可能源自方法本身对于正交矩阵区分能力的不足。相比之下,DOCS方法的热力图在主对角线上展现出了清晰且明确的结构,显著减少了噪声和不相关信号的干扰。这表明DOCS在识别相似层方面表现更为突出。
Neighboring Layers Exhibit Similar Weights
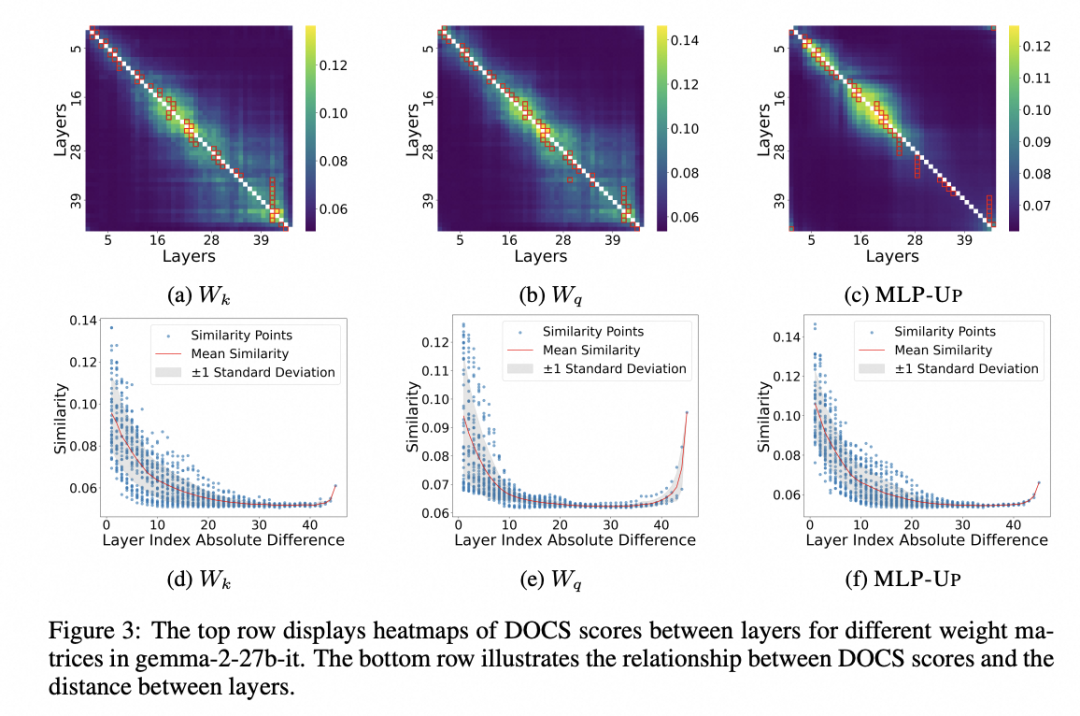
我们对不同大型语言模型(LLMs)的相邻 Transformer 层进行了权重矩阵的相似性分析,包括 \(W_v\)、\(W_k\)、\(W_q\)、\(W_o\)、\textsc{MLP-Up} 和 \textsc{MLP-Down} 等多个矩阵。
我们采用 DOCS 方法计算并可视化了这些矩阵之间的相似性。以gemma-2-27b-it模型为例,从展示的 \(W_k\)、\(W_q\) 和 \textsc{MLP-Up} 权重矩阵热力图中,可以清晰地看出,相邻层之间具有明显更高的相似度。进一步从散点图分析中,我们观察到,随着层之间距离的增加,相似度呈现出明显下降趋势。散点图中阴影部分表示相似度的平均值上下一个标准差的范围,这也进一步强化了我们刚才的观察。在其他的权重矩阵以及其他不同的大型语言模型中也有类似的发现。
我们还发现了一个有趣现象:最靠近输入端的第一层与最靠近输出端的最后一层这两个位置非常远的层次,反而也表现出了较高的相似度。这在散点图的两端表现为明显的上升趋势。我们推测,这可能是因为这两层都靠近输入输出层。
Clusters of Similar Layers
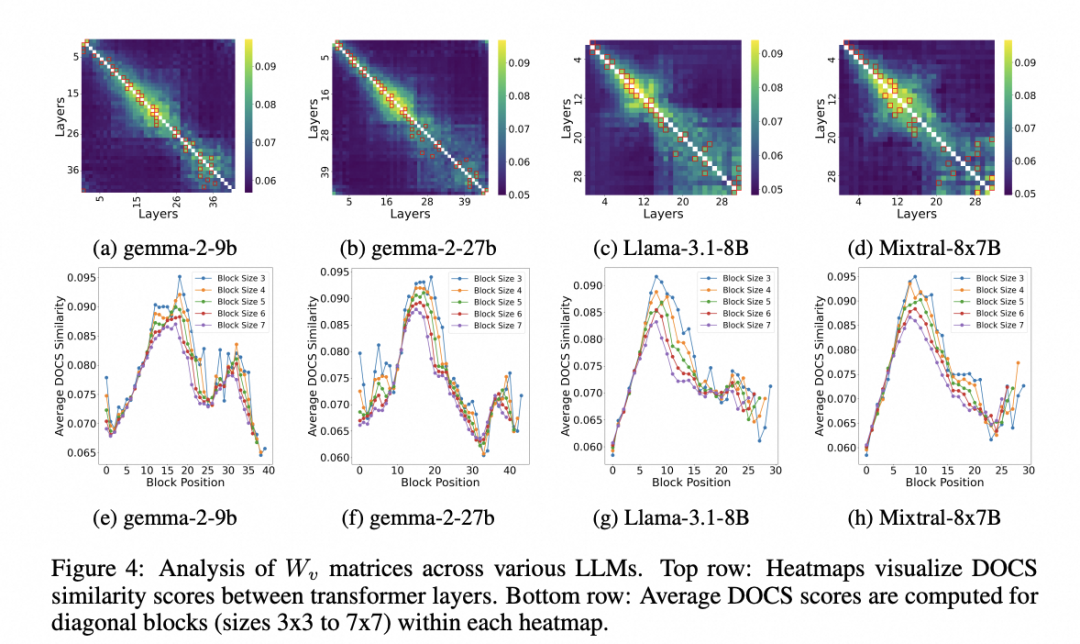
我们进一步发现了 LLM 模型内部层之间存在的相似层簇现象。首先,从各个模型的热力图中可以明显看到,有一些连续的层形成了高相似度的簇,这些簇表现为图中的浅色区域。为了更清楚地展示这种簇状结构,我们计算了热力图对角区域内尺寸从3×3到7×7不等的矩阵块的平均相似度。这种方式帮助我们更精确地定位了层簇的位置和相似度的具体水平。不同的模型在具体簇的数量和结构上可能会有所不同,比如我们发现Llama-3.1-70B模型中甚至包含更多的簇结构。
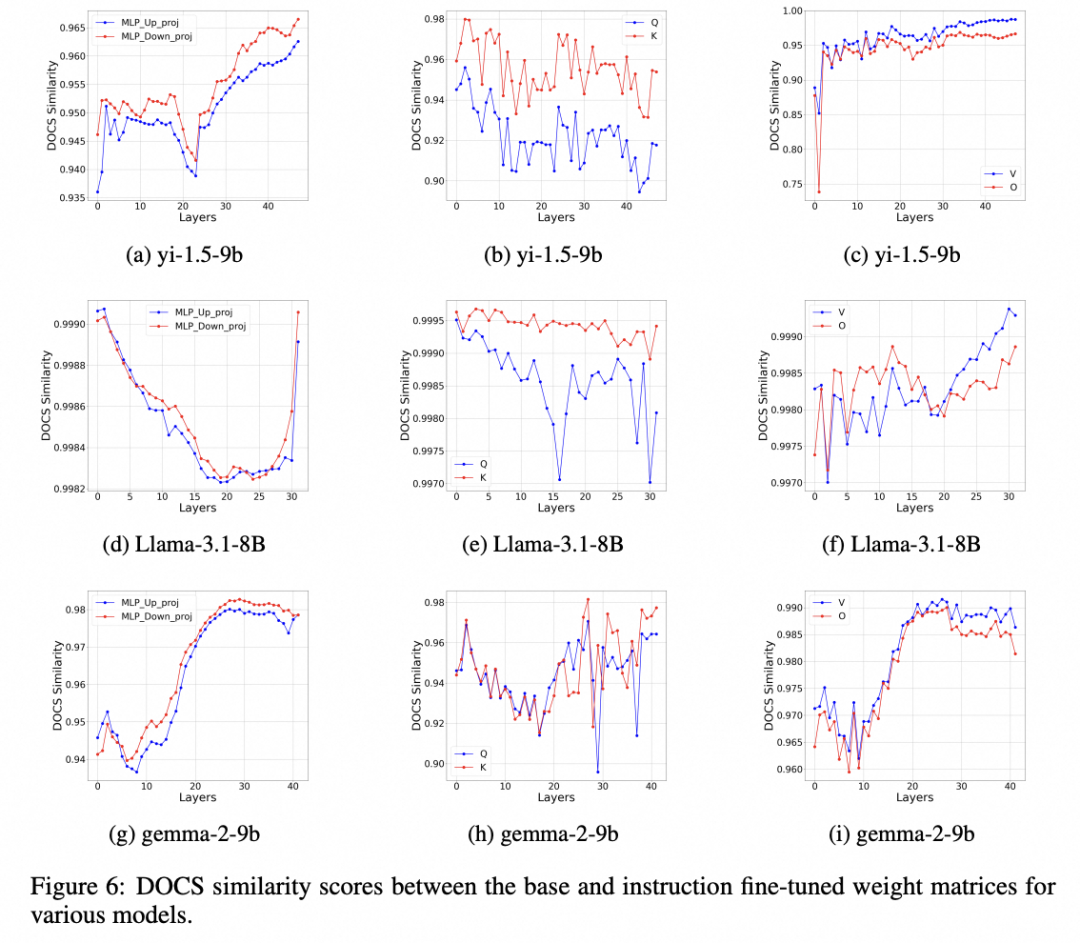
Base vs. Instruct Models
我们使用 DOCS 指标,对比分析了基础模型与指令微调模型之间的权重变化情况,涉及yi-1.5、Llama-3.1和gemma-2等多个大型语言模型系列。从分析结果中我们可以清楚地看到,基础模型和指令微调模型之间,各种权重矩阵的DOCS相似度均非常高,均超过了0.7。这说明经过指令微调之后,这些模型在很大程度上仍保留了原有的基础知识。
此外,我们还观察到一个明显的现象:权重矩阵按照DOCS相似度的趋势,呈现出了明显的三类分组。这三类具体为:第一组是\textsc{MLP-Up}和\textsc{MLP-Down}矩阵;第二组是$W_q$和$W_k$矩阵;第三组则是$W_v$和$W_o$矩阵。这种分组的出现可能源自模型架构中这些矩阵本身的功能相似性。

Conclusion
我们在本次研究中提出了一个全新的相似度指标——DOCS,用以量化大型语言模型中权重矩阵之间的相似性。相比于已有方法,DOCS能够有效地区分正交矩阵,克服了现有相似度指标的关键局限,使我们能够更加深入地理解模型内部结构。
在实验中,我们发现了一些有意义的结构特征,例如相邻层之间明显的高相似性,以及连续层所形成的相似簇群。我们识别出的相似簇结构能够为参数高效的微调阶段提供有效的归纳偏置,从而更好地引导模型训练。
在传统的微调方法中,每个参数通常独立调整,容易导致参数空间过于庞大且存在冗余。而利用提前发现模型中冗余和共享的参数模式,一种可能更高效的方案是在微调时对属于同一簇群的参数进行协同优化。这种基于簇的微调方式不仅可以减少待优化参数的总量,还能增强模型训练过程中的稳定性和泛化性能。
其次,这些结构信息还能帮助我们实施更高效的知识蒸馏策略。在传统的知识蒸馏框架下,学生模型通常需要逐层、逐参数地全面模仿教师模型,以期获得相似的性能。这种方式往往计算资源和时间成本较高。而借助 DOCS 识别的相似簇结构,一种可能更高效的方案是首先更加精确地判断哪些层具有较高的信息代表性,哪些层则相对冗余且可以被略过。学生模型可能只需优先模仿每个簇群中最具代表性和关键性的少数层即可捕获教师模型的大部分知识结构特征,从而避免对教师模型所有结构的完全复制。这种方法有潜力提高蒸馏过程的效率,同时也减少因过度模仿而产生的信息冗余和性能瓶颈。


















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









