



摘要
|
机器人的具身场景是伴随多模态技术发展的热点方向,如何根据用户语言指令完成机器人的抓取动作成为了研究的核心议题。以多模态模型为核心的算法设计,依赖高质量的人工标注数据,在具身场景是一个严峻的挑战。 本文针对数据的标注问题,设计一套让机器人自主从无标注数据中进行操作概念挖掘的框架,从而提升机器人在各种抓取中更优的效果。 |
在机器人技术领域,让机器人完成复杂的操作任务一直是研究的核心目标。
传统方法依赖人类标注的预定义技能(如抓取、移动等),但这种方式存在显著局限性:一方面,人类标注成本高且主观性强,难以覆盖环境变化带来的多样性;另一方面,机器人在动态环境中执行长时任务时,误差累积会导致性能下降。
随着自监督学习和扩散模型的发展,研究者开始探索如何让机器人自主从无标签演示中提取操作概念。这些操作概念类似于人类的运动技能(如抓取、推动),可以分解复杂任务为子任务,提升学习效率和泛化能力。
然而,现有方法要么依赖启发式设计,要么缺乏物理接地,难以适应真实环境的动态变化。Automatic Concept-Guided Policy (自主概念发现引导)的提出正是为了解决这些痛点。它通过自监督学习框架,让机器人从本体感受状态中自主发现操作概念,并构建动态调整的闭环策略,从而在复杂任务中实现更稳定、高效的表现。

上图对比了人工通过自然语言定义的操作概念(如 “抓取”“运输”)与 Automatic Concept-Guided Policy 自主发现的操作概念。人工通过语义标签指导任务分解(如 “抓取→运输→放置”),而Automatic Concept-Guided Policy 通过自监督学习从机器人本体运动状态中提取离散特征向量(α₁, α₂,...,α_K),动态选择概念并利用扩散模型生成动作。
人工方法依赖标注,而Automatic Concept-Guided Policy 无需标注,通过闭环策略实现更贴合机器人物理特性与环境变化的自主操作。
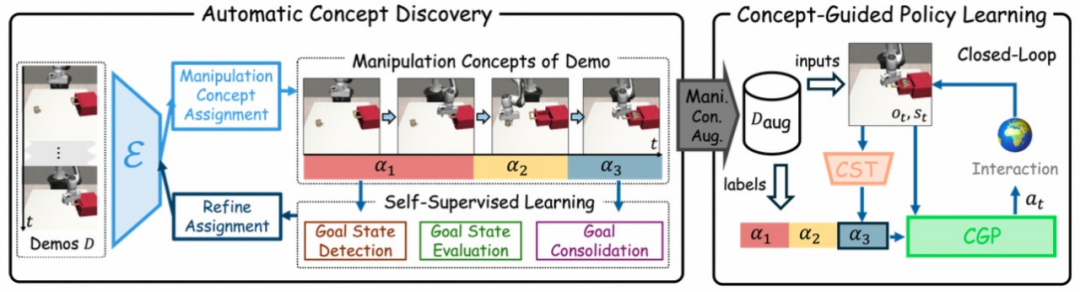
上图展示了Automatic Concept-Guided Policy 从无标签演示中学习闭环概念引导策略的完整流程,整体分为两大模块:自动概念发现和概念引导策略学习,通过数据标注与策略训练形成闭环。
左侧的自动概念发现模块从原始演示数据中提取操作概念,右侧的策略学习模块利用这些概念生成动态调整的动作。两者通过自监督学习实现端到端优化,无需人类标注。
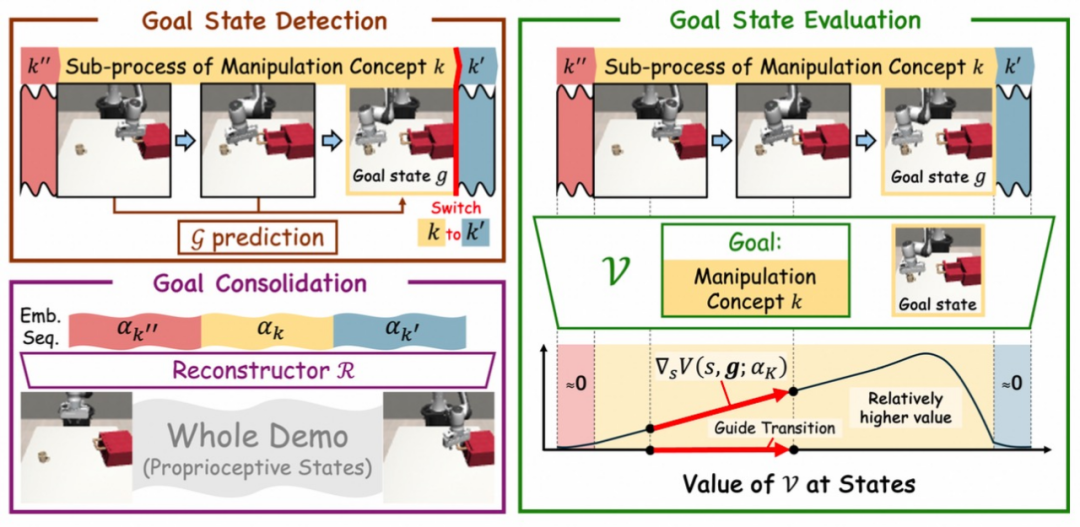
其中,自动概念发现模块如上图所示,通过三个核心策略提取操作概念。第一个为目标状态检测(Goal State Detection),采用 VQ-VAE 架构将连续的本体感受状态离散化为 K 个概念嵌入(α₁,…,α_K),并通过检测概念切换点确定子任务目标状态(如抓取动作的结束点)。
第二个为目标状态评估(Goal State Evaluation),训练值函数的评估状态与目标的对齐度(如是否处于当前概念的有效区间)和完成度(如梯度方向是否指向目标),确保概念的有效性。第三个为目标巩固(Goal Consolidation),通过重构网络将概念嵌入映射回本体感受状态,增强同一概念下子序列的一致性,避免概念歧义。
在概念引导策略学习模块中,策略学习模块通过概念选择(Concept-Selection Transformer: CST)和概念引导策略(Concept-Guided Policy: CGP)实现动态决策。其中概念选择模块根据实时观测(视觉 + 本体感受)动态选择最优操作概念,输出概率分布,采用交叉熵损失训练,确保概念选择与环境状态匹配。而CGP模块基于扩散模型生成高维动作,结合 CST 的概念分布预测,通过 扩散模型DDPM 框架优化动作生成,提升策略对动态环境的适应性。最后进行联合训练,CST 与 CGP 通过联合损失函数协同优化,形成闭环反馈。CST 的概念选择指导动作生成,而 CGP 的动作预测误差又反向优化概念选择,最终实现长时任务中的稳定执行。
Automatic Concept-Guided Policy 在 Robosuite 仿真环境中针对多种复杂操作任务(咖啡制作、锤子收纳等)进行了验证,涵盖 3 种环境复杂度。
实验结果表明,Automatic Concept-Guided Policy 在成功率上显著优于基线方法(扩散策略 Diffusion Policy)和前序工作(InfoCon、XSkill 等),例如在高难度的咖啡制作任务中成功率达 72%,较基线提升 32%。消融实验显示,目标状态检测、评估和巩固模块的缺失均导致性能下降,验证了各组件的必要性。

上图展示了Automatic Concept-Guided Policy 在真实世界数据集BridgeData V2中通过自主概念发现模块提取的操作概念。实验采用CodeBook大小为10的VQ-VAE,成功发现了四类具有物理意义的操作概念:Concept #2(机械臂移动至目标位置)、Concept #4(闭合夹爪抓取物体)、Concept #8(将物体放置到目标点)和 Concept #9(张开夹爪释放物体)。这些概念体现了 Automatic Concept-Guided Policy 在真实场景中自主抽象概念挖掘的能力,验证了其从无标签数据中学习可复用操作技能的可行性。
下面为一些可视化的效果对比,体现出发掘的自主概念,帮助 Automatic Concept-Guided Policy 在具身场景中的取得优异的效果。
|
咖啡制作 | |
|
Diffusion Policy |
|
|
锤头收纳 | |
|
Diffusion Policy |
|
|
堆叠物体 | |
|
Diffusion Policy |
|
|
装配物体 | |
|
Diffusion Policy |
|








本文提出的 Automatic Concept-Guided Policy 框架通过无监督学习实现了机器人从无标签演示中自主发现操作概念并生成闭环策略,突破了传统方法依赖人类标注和静态策略的局限。其核心创新在于双模块架构:自动概念发现模块利用 VQ-VAE 和目标状态检测 / 评估 / 巩固策略,从本体感受状态中提取离散操作概念,通过概念引导策略学习模块,形成闭环反馈系统。
实验在 Robosuite 仿真环境中验证了其在 复杂任务中的显著优势,且概念发现表现出跨任务的一致性。该研究为机器人在动态环境中执行长时操作提供了高效解决方案,对智能家居、工业自动化等领域具有重要应用价值。在未来我们会结合不同模态的输入信息,将视觉信号和机械臂的运动轨迹进行结合,为操作概念的发现进行更有效的提取,从而进一步提升具身场景的泛化能力。
参考文献:
[1] AutoCGP(Automatic Concept-Guided Policy 自主概念发现引导): Closed-Loop Concept-Guided Policies from Unlabeled Demonstrations. ICLR 2025
[2] InfoCon: Concept discovery with generative and discriminative informativeness. ICLR 2024
[3] Xskill: Cross embodiment skill discovery. CoRL 2023

















 2976
2976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









