



【ICLR 2025预讲会】系列内容
ICLR 2025预讲会系列文章来源于 DAMO 开发者矩阵与 AI Time 联合举办 ICLR 2025预讲会整理成稿,旨在帮助大家率先了解深度学习领域的最新研究方向和成果。本文为文章作者的观点/研究数据,仅供参考,不代表本账号的观点和研究内容。
摘要
LLM 测评是行业热点研究方向,传统研究一般采用图片、表格、时空数据来进行测评。Graph 图数据也是测评 LLM 的一类优秀数据,解决图任务需要 LLM 解读关系信息或结构化知识,处理非序列或非欧几里得数据,一些困难的图任务还需要 LLM 进行多步骤推理。然而现有的基于图的 LLM 测评存在一些问题:测评数据为人工合成的数据,缺乏现实场景数据;测评图任务较简单(如判断两个节点是否可达,图遍历等);测评只看推理结果,忽视结果正确但中间步骤出错的情况等。
针对上述问题,香港科技大学团队提出了一种新的图任务测评框架,名为 GraphArena,解决了上述问题,具备真实世界图数据、多样化图问题、严格测评框架与全面测评体系的优势。
论文链接:https://arxiv.org/abs/2407.00379
代码仓库:https://github.com/squareroot3/grapharena
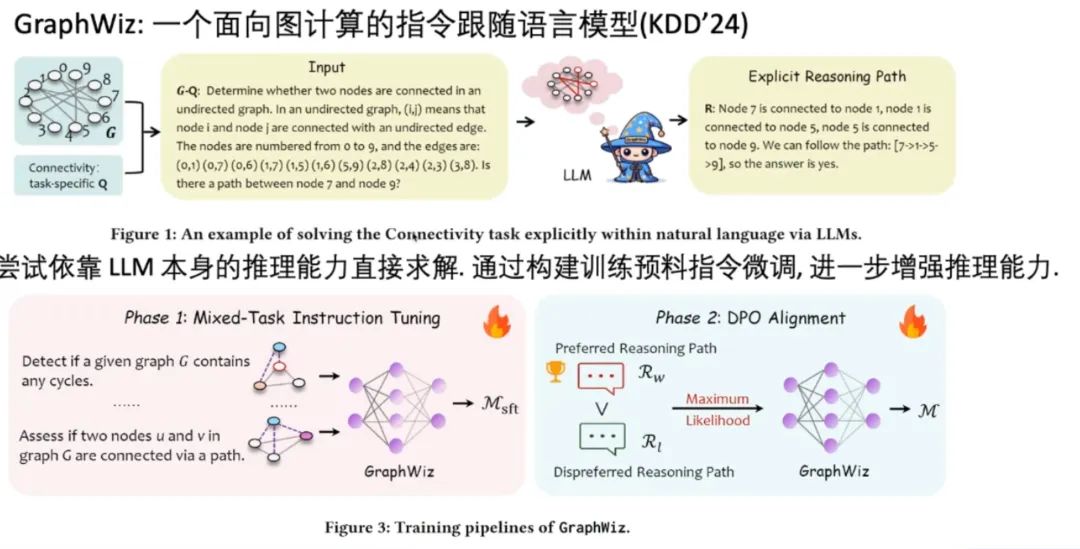
与该工作相关的一项工作名为 GraphWiz,这是一个面向图计算的指令跟随语言模型,论文发表在 KDD24 上。它尝试依靠 LLM 本身的推理能力直接求解图问题。
论文链接:https://arxiv.org/abs/2402.16029
代码仓库:https://graph-wiz.github.io/
另一项相关工作名为 GCoder,其理念是让 LLM 写代码/调用工具来求解图问题。
论文链接:https://arxiv.org/abs/2410.19084

问题构造及测评方法
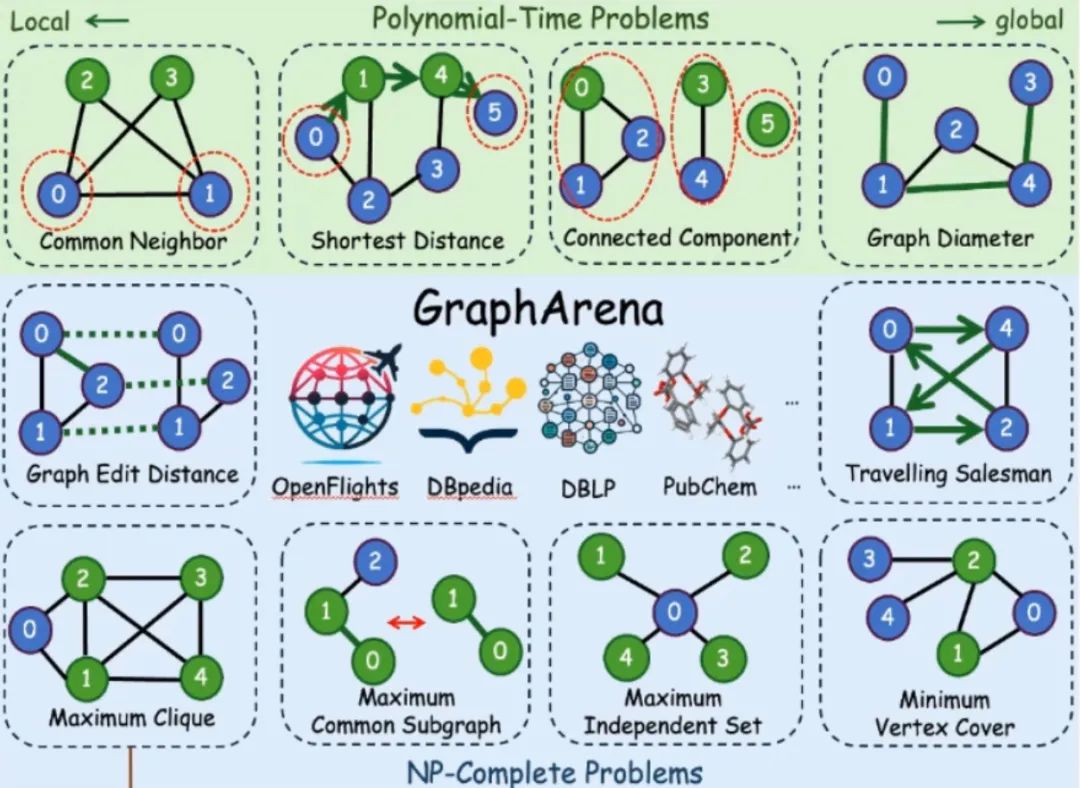
如下图上部所示,GraphArena 框架选择了四个多项式复杂度问题,还有六个 NP 难问题,如图下部所示。框架的数据源取自五个真实世界数据源,涵盖知识图谱、社交网络、分子结构和飞机航线图。
对于测评方法,该框架将任务的输出答案评价指标分为三种,分别是 Correct、Suboptimal 和 Hallucinatory,依次表示 LLM 生成的解可行且最优、可行但非最优、不可行三种情况。例如,下图对一个图求解 maximum clique 时,不同 LLM 分别给出三种回答的情况:
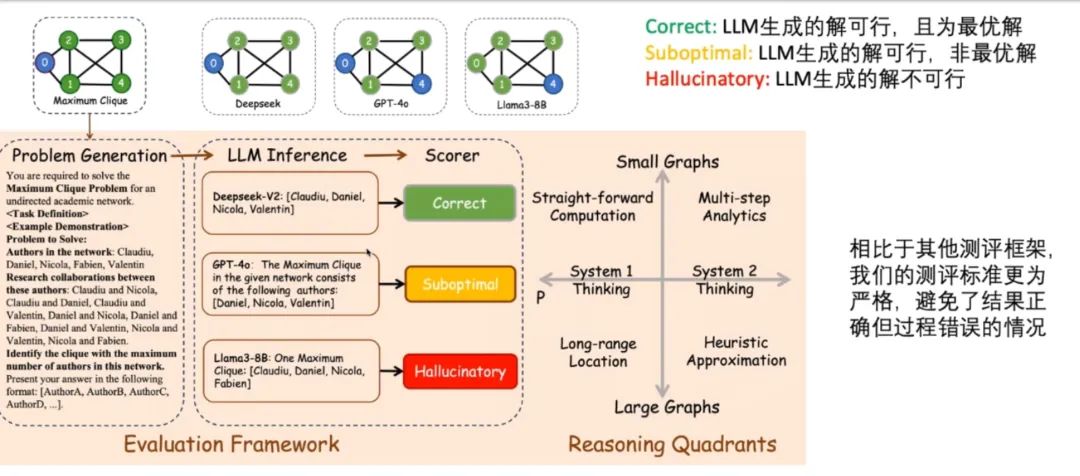
可以看到 Llama3-8B 给出的答案甚至不是 clique,GPT-4o 给出的答案虽然是 clique 但并非最大,DeepSeek 给出的答案才是最大 clique,区分这三种答案类型的这种测评方法是更加严格的。

实验对比
实验中,团队使用该框架测评了四个闭源 LLM 与六个开源 LLM:
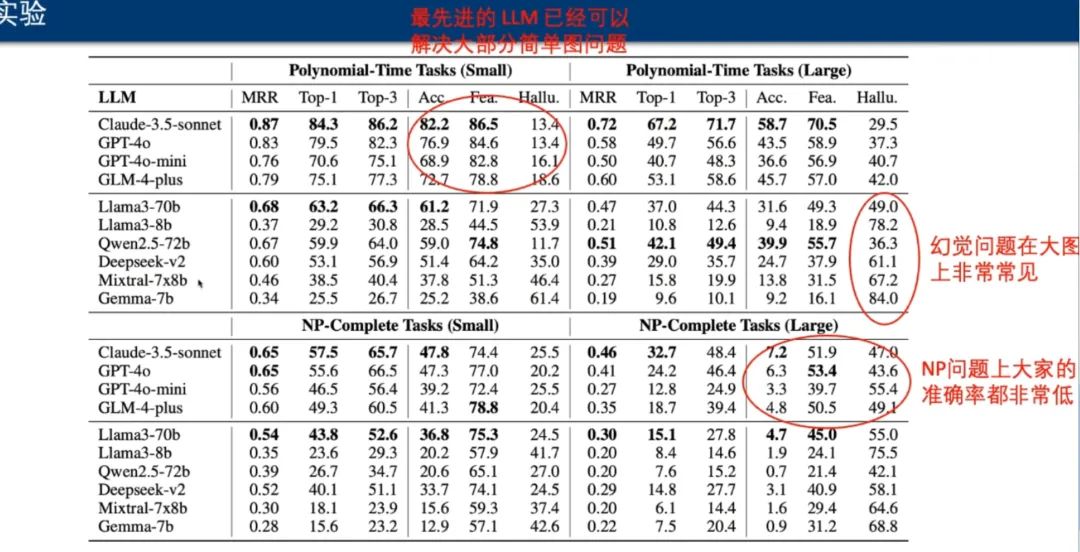
测评分为多项式时间和 NP 问题两部分,也分别测评了小图和大图的情况。测评结果显示,最先进的 LLM 已经可以解决大部分简单图问题,但 LLM 在大图上表现出了明显的幻觉问题。对于较困难的 NP 完全问题,模型的准确率都很低。
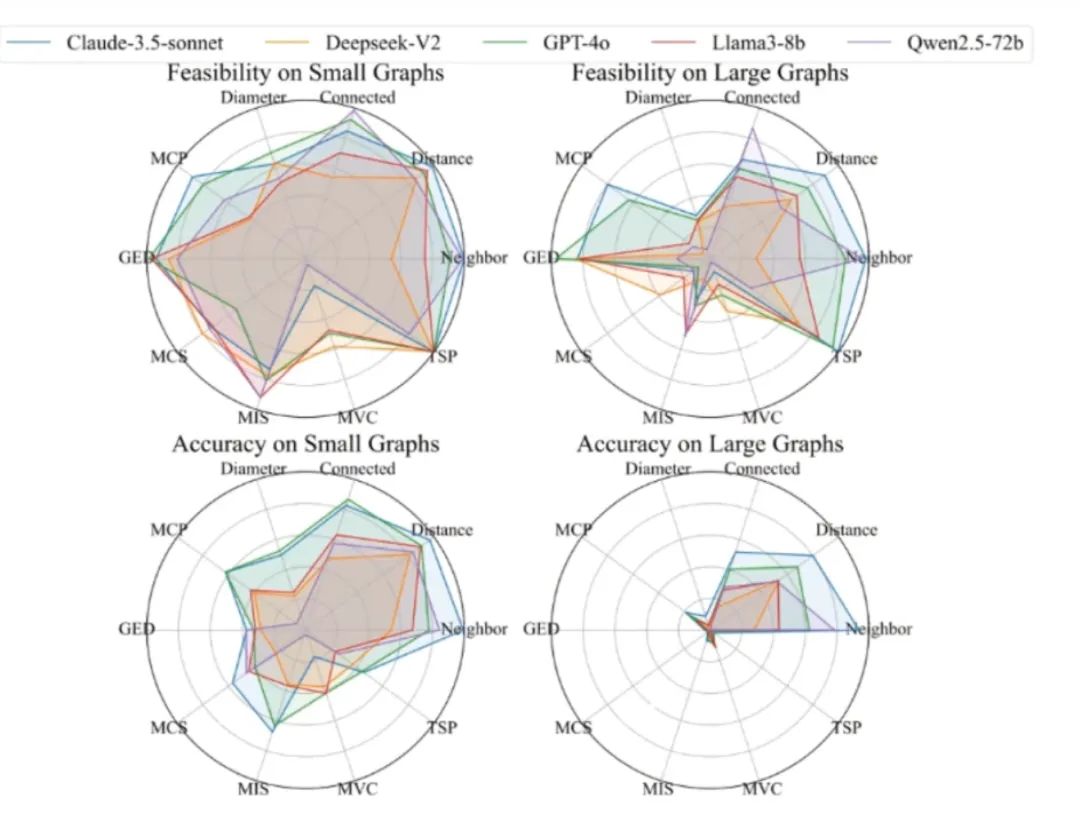
第二项实验是对不同任务来测评 LLM,结果显示在所有多项式复杂度任务中,所有 LLM 在求图直径的任务上表现更不理想;在所有 NP 任务中,所有 LLM 在最大顶点覆盖的任务上更容易产生幻觉:
第三项实验对比了 GPT-4o 和传统图算法的表现,抽取了四个任务,每个任务两个难度,对比三种图算法:
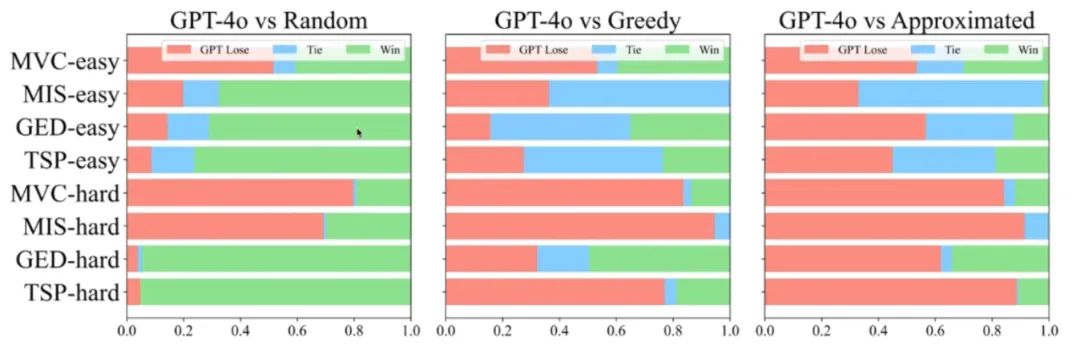
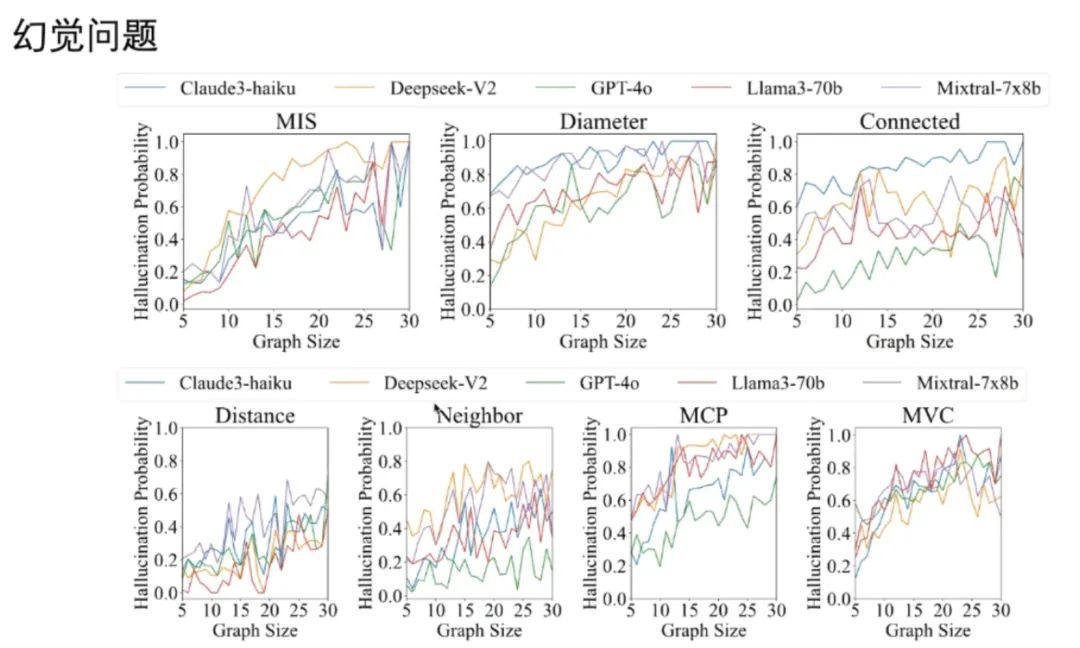
结果显示 GPT-4o 一般和贪心算法表现相当,不如近似算法,不过少数情况也能超越近似算法。使用不同问题来测评不同 LLM 的幻觉表现发现,图尺寸越大,模型幻觉越严重:
团队也探索了减少幻觉的可能解决方案,包括提示工程、指令微调、工具调用和多模态模型。结果发现给出的例子越多,模型幻觉越少,可见提示工程是有效的。SFT 指令微调方法在实测中也表现出了更低的幻觉率。如果让 LLM 通过写代码的方式解决问题,在多数测试中也能减少幻觉。
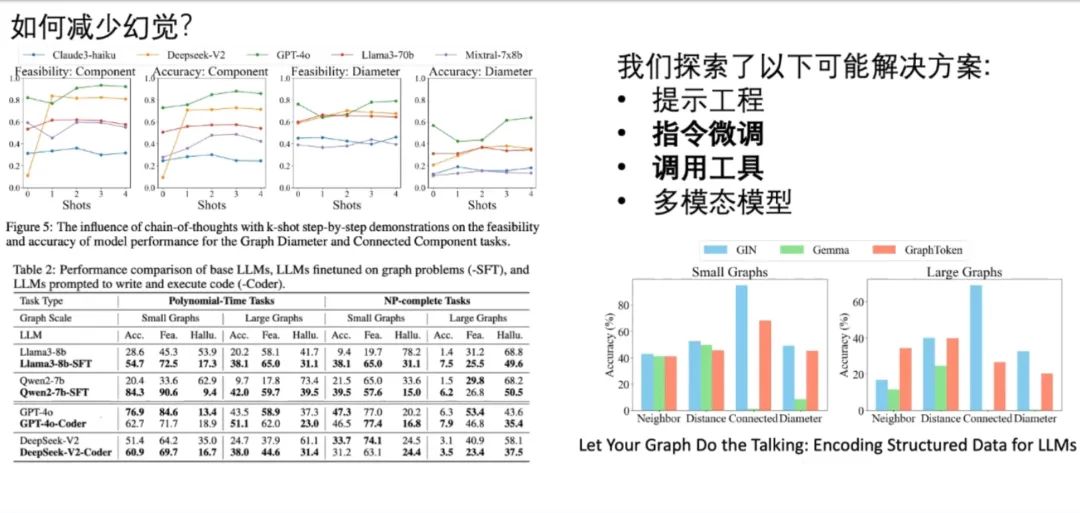
对于多模态模型,这里使用了谷歌论文《Let Your Graph Do the Talking》中使用的 GraphToken 模型,该模型分离了图和文本,分别进行编码后再交会 LLM 进行推理。对比发现多模态模型的推理能力也有所提升。

相关工作
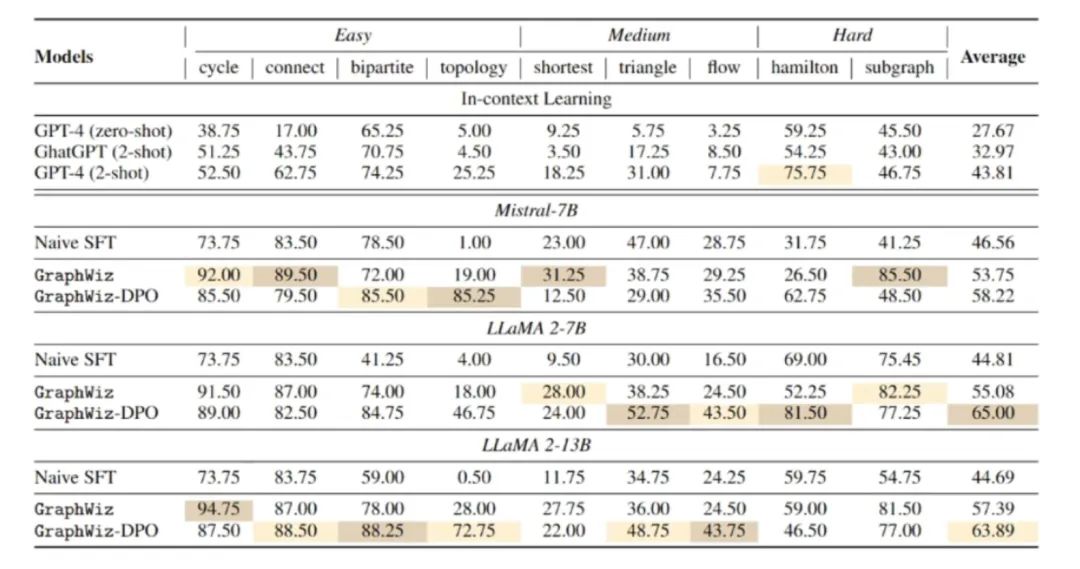
与上述工作相关的一项工作名为 GraphWiz。它使用 SFT 增强 LLM 推理能力,这里的 SFT 将答案包装成了推理路径的形式,让 LLM 通过这些路径求解。其训练过程是传统的 SFT-DPO 两步训练。
实验结果表明,这种推理模型只需 7B 规模就能击败 GPT-4:
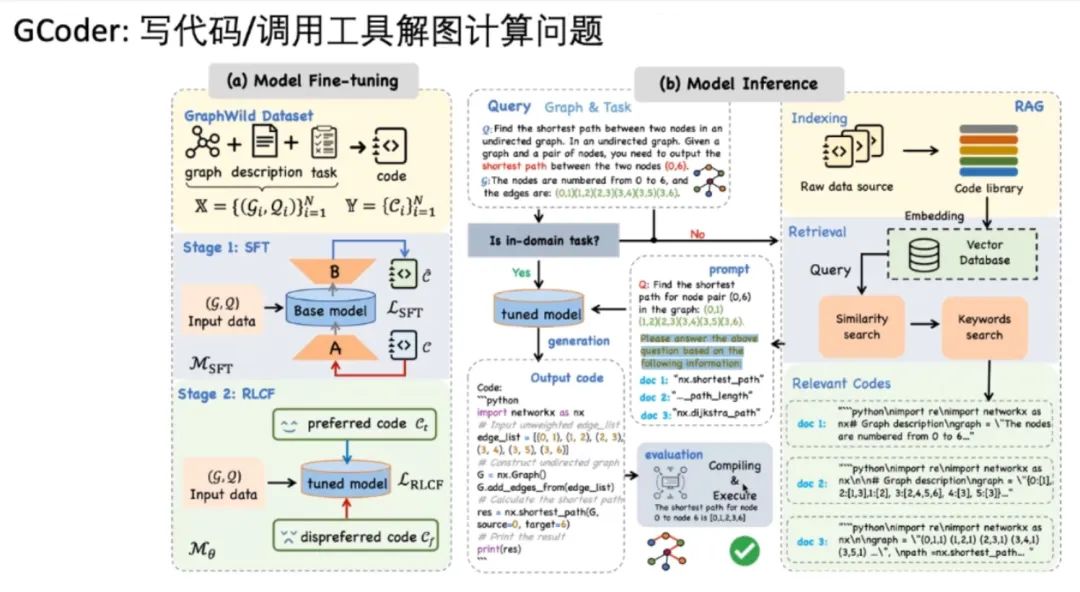
另一项工作名为 GCoder,其理念是用 LLM 写代码/调用工具解决图问题。其训练分为 SFT-RLCF 两步过程,而模型推理时会将任务分解为 In-domain(问题存在于训练语料中)和 Out-of-domain(不在语料中)两类。对于前者使用直接推理处理,对于后者使用 RAG 方式处理。两者都会输出代码,输入编辑器执行并得到结果:
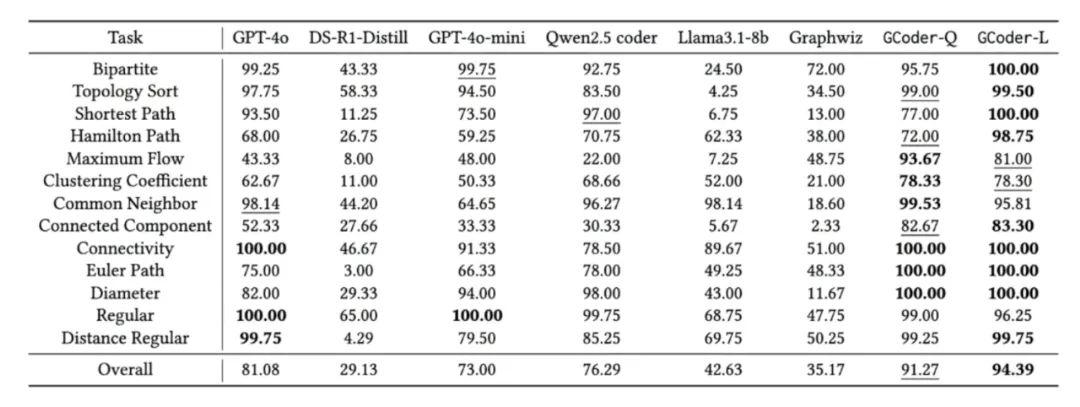
实验结果发现该模型在不同难度任务上的平均准确率超过 90%,写代码能力超越了 GPT-4o 和 DeepSeek R1-Distill:

















 1061
1061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









