







5.1 用户历史行为序列建模
把用户行为序列叫做 last-n,指用户最近交互过的n个物品的ID。
适用于召回双塔模型、粗排三塔模型、精排模型
取平均是早期的做法,但是现在也很常用,更好的方法是引入Attention机制
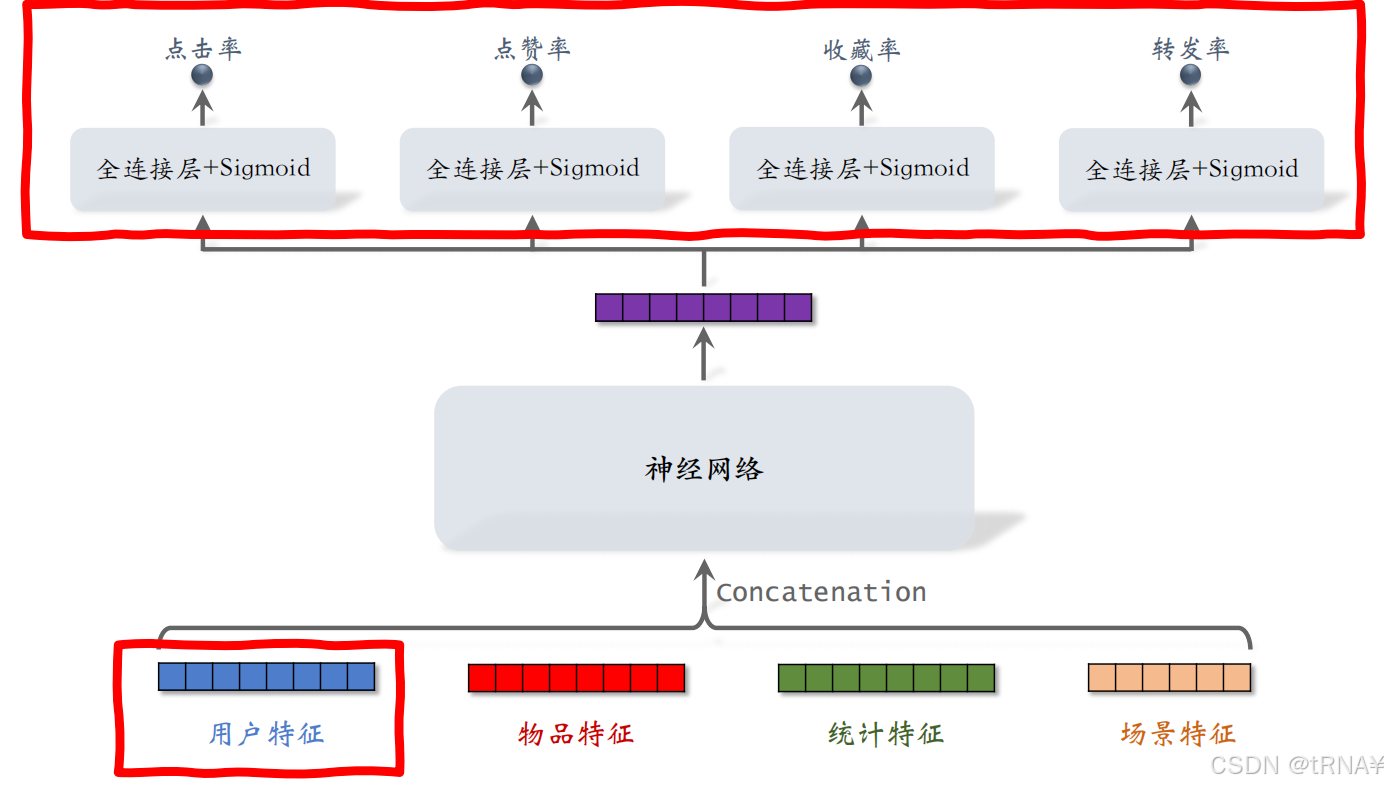
多目标排序模型
我们将last-n作为特征输入多目标模型,可以提高模型的预估效果
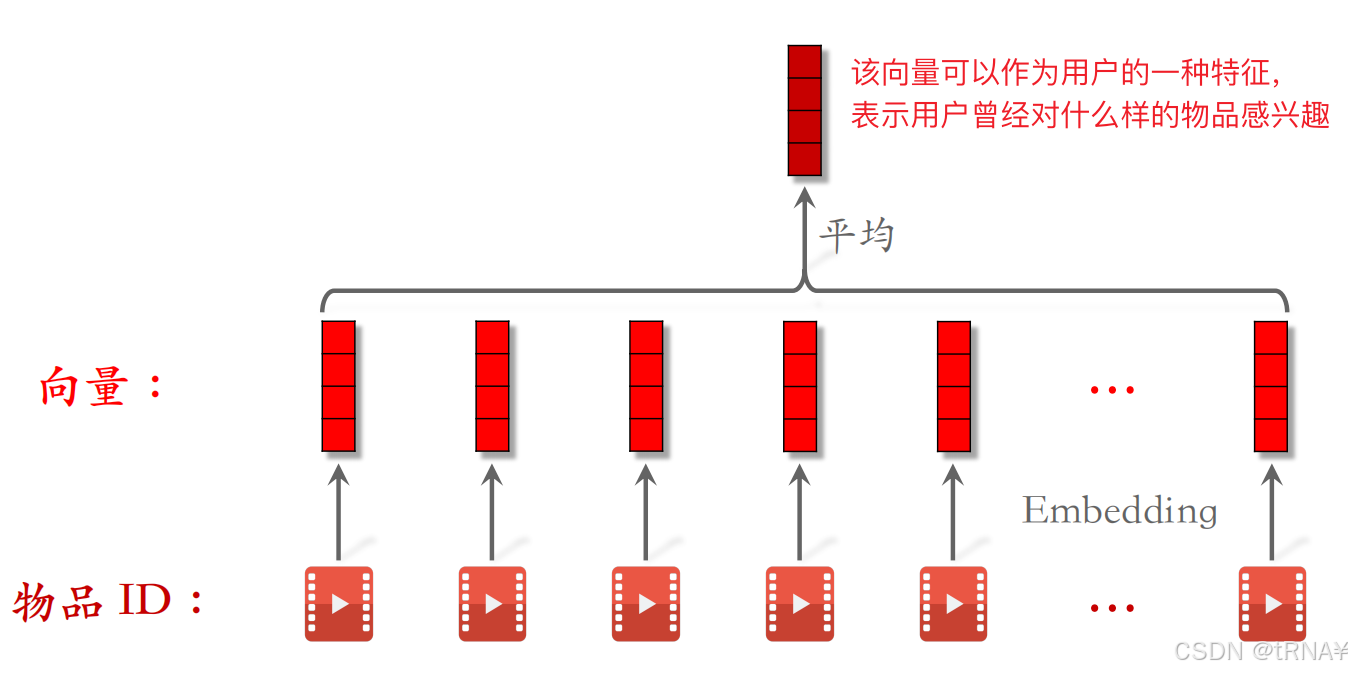
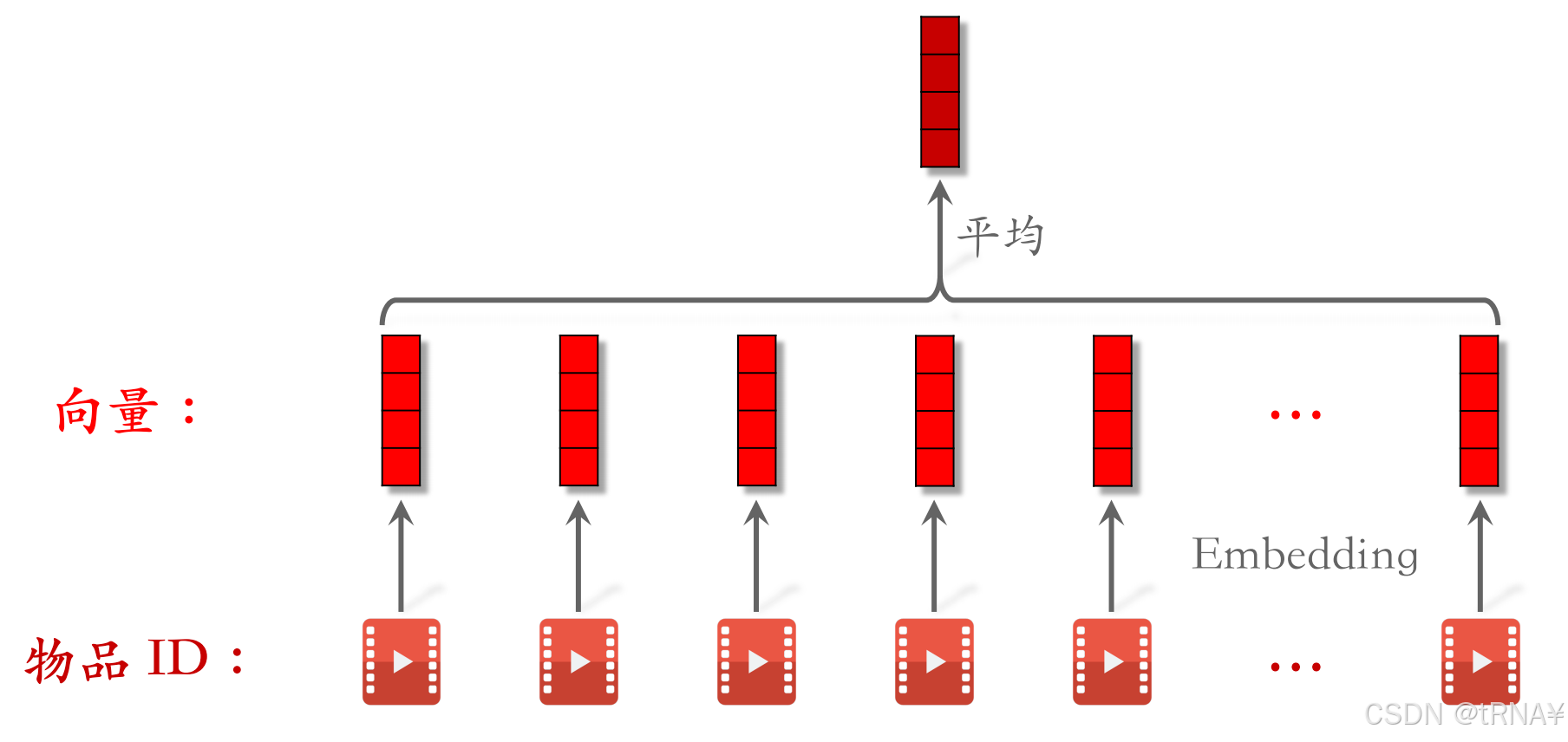
用户lastN序列特征
LastN:用户最近n次交互(点击、点赞、收藏、转发等行为)的物品ID
- 对LastN物品ID做embedding,得到n个向量
- 把n个向量取平均,作为用户的一种特征
- 注意,用户还有其他的很多特征,比如用户ID、离散特征、连续特征等,把所有这些特征拼起来,作为用户特征输入神经网络
小红书的实践
小红书的召回、粗精排都用到了LastN行为序列
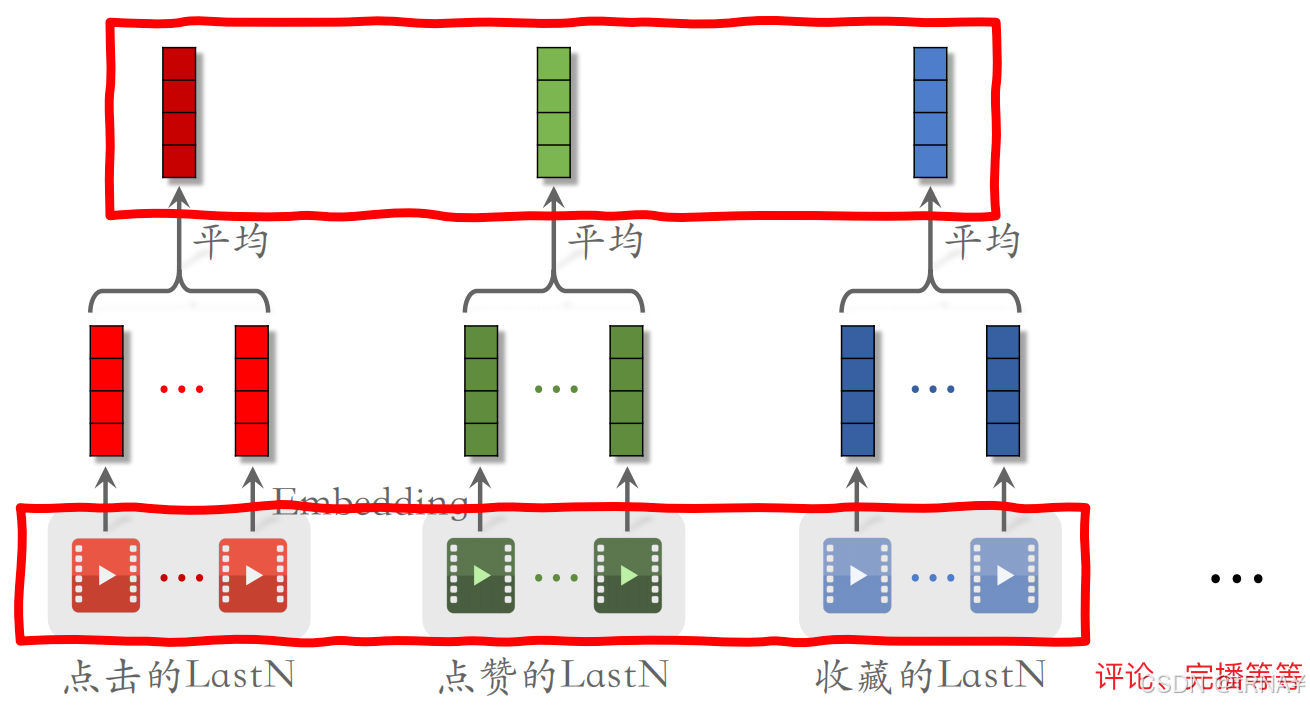
- 对同一种行为的向量取平均,得到点击、点赞、收藏等行为的LastN向量表征
- 把这些向量拼起来,作为一种用户特征
- 实践中不止用物品ID,还用物品的其他特征,如物品类目。把物品ID Embedding和物品其他特征Embedding拼在一起
5.2 DIN模型(注意力机制)
DIN模型是对 LastN序列建模 的一种方法,效果优于简单的平均。用于精排
上一小节我们讲过,用Attention机制代替平均效果会更好,现在我们来讲述它的原理
DIN原理
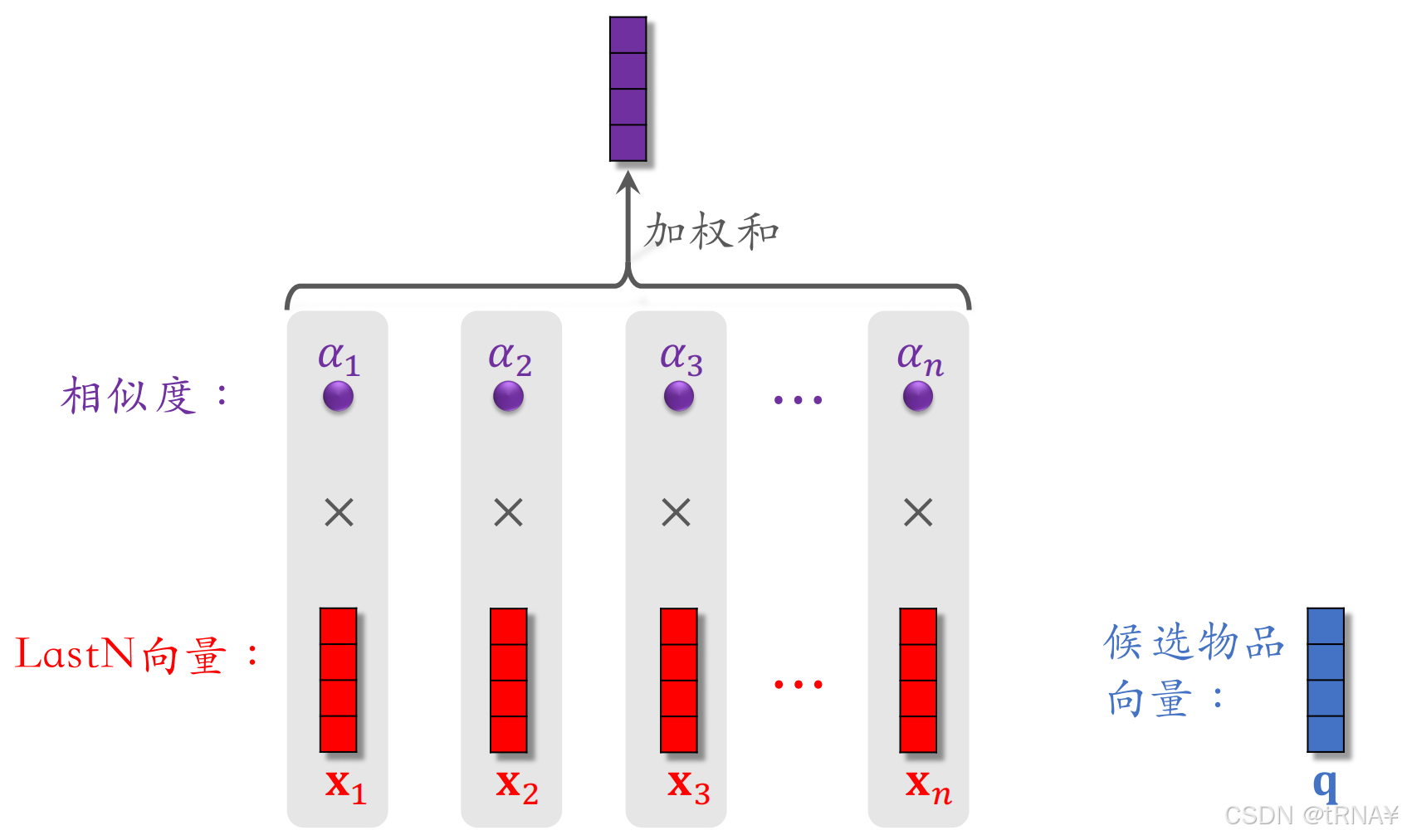
DIN本质就是(候选物品与用户LastN物品的相似度)= 权重 与(LastN物品)的加权和
- 权重指候选物品与用户LastN物品的相似度(实数α)。哪个LastN物品与候选物品越相似,它的权重就越高
- 比如粗排选出了500个物品,它们就是精排的候选物品。精排模型要给每个候选物品打分,分数表示用户对候选物品的兴趣,最后根据分数的高低给这500个候选物品排序,保留分数最高的几十个展示给用户
- 计算相似度的方法有很多,比如内积、cos
Attention机制的原理介绍大家可以看我这篇文章:第四章 预训练语言模型 Seq2Seq,Attention,Transformer-优快云博客
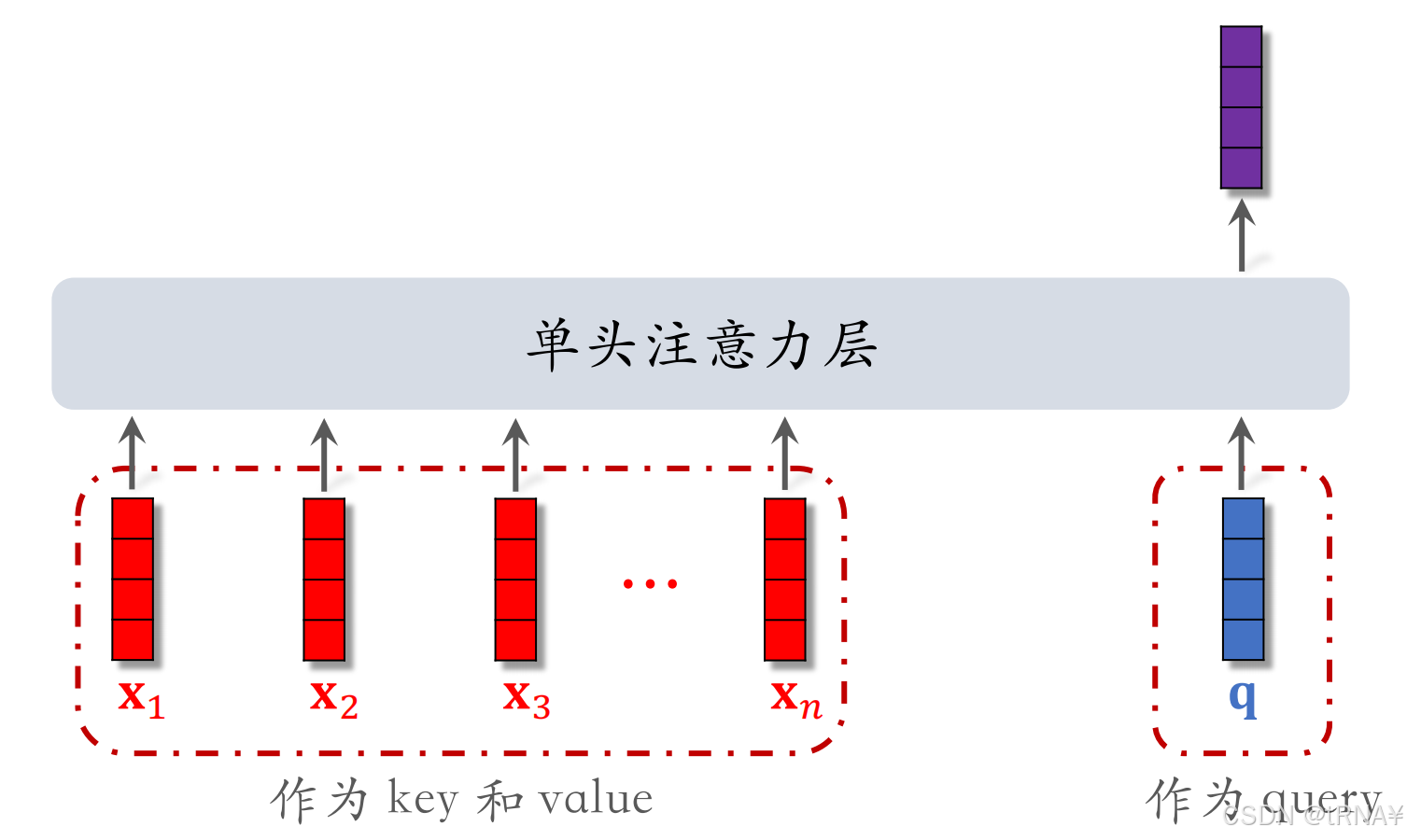
看完大家就可以发现DIN其实就是注意力机制,不过DIN用的是软注意力机制。
软注意力机制可以看下图来理解。其实就是用X直接代替了K,V
简单平均 vs 注意力机制
简单平均 和 注意力机制 都适用于精排模型
简单平均还适用于召回的双塔模型、粗排的三塔模型
- 简单平均只需要用到LastN,属于用户自身的特征,跟候选物品无关
- 把LastN向量的平均作为用户塔的输入
注意力机制不适用于双塔模型、三塔模型
- 注意力机制需要用到 LastN + 候选物品
- 用户塔看不到候选物品(比如双塔召回时,有上亿候选物品,用户只能看到用户特征,看不到候选物品特征),故不能把注意力机制用在用户塔
DIN模型的缺点
- 注意力层的计算量 ∝ n(用户行为序列的长度)
- 只能记录最近几百个物品(一般一两百个物品),否则计算量太大
- 缺点:关注短期兴趣,遗忘长期兴趣
5.3 SIM模型(长序列建模)
主要目的是保存用户的长期兴趣--长期行为序列(n很大)
SIM模型是改进版的DIN,减少了注意力层计算量
改进DIN
- DIN对LastN向量做加权平均,权重是相似度
- 如果某LastN物品与候选物品差异很大,则权重接近0
- 如果把不相关的物品从LastN物品中排除掉,几乎不会影响DIN加权平均的结果
- 只把相关物品输入注意力层,快速排除掉与候选物品无关的LastN物品,降低注意力层的计算量
第一步:查找
Hard Search
- 根据候选物品的类目(规则),保留LastN物品中类目相同的
- 简单、容易实现、快速、无需训练
Soft Search
- 把LastN物品和候选物品都做Embedding,变成向量
- 把候选物品向量作为query,做k近邻查找,保留LastN物品中最接近的k个
- 效果更好,用于预估点击率等业务指标时AUC更高
- 编程实现更复杂,计算代价更高,性价比不高,一般使用hard search
- 类似于最近邻查找
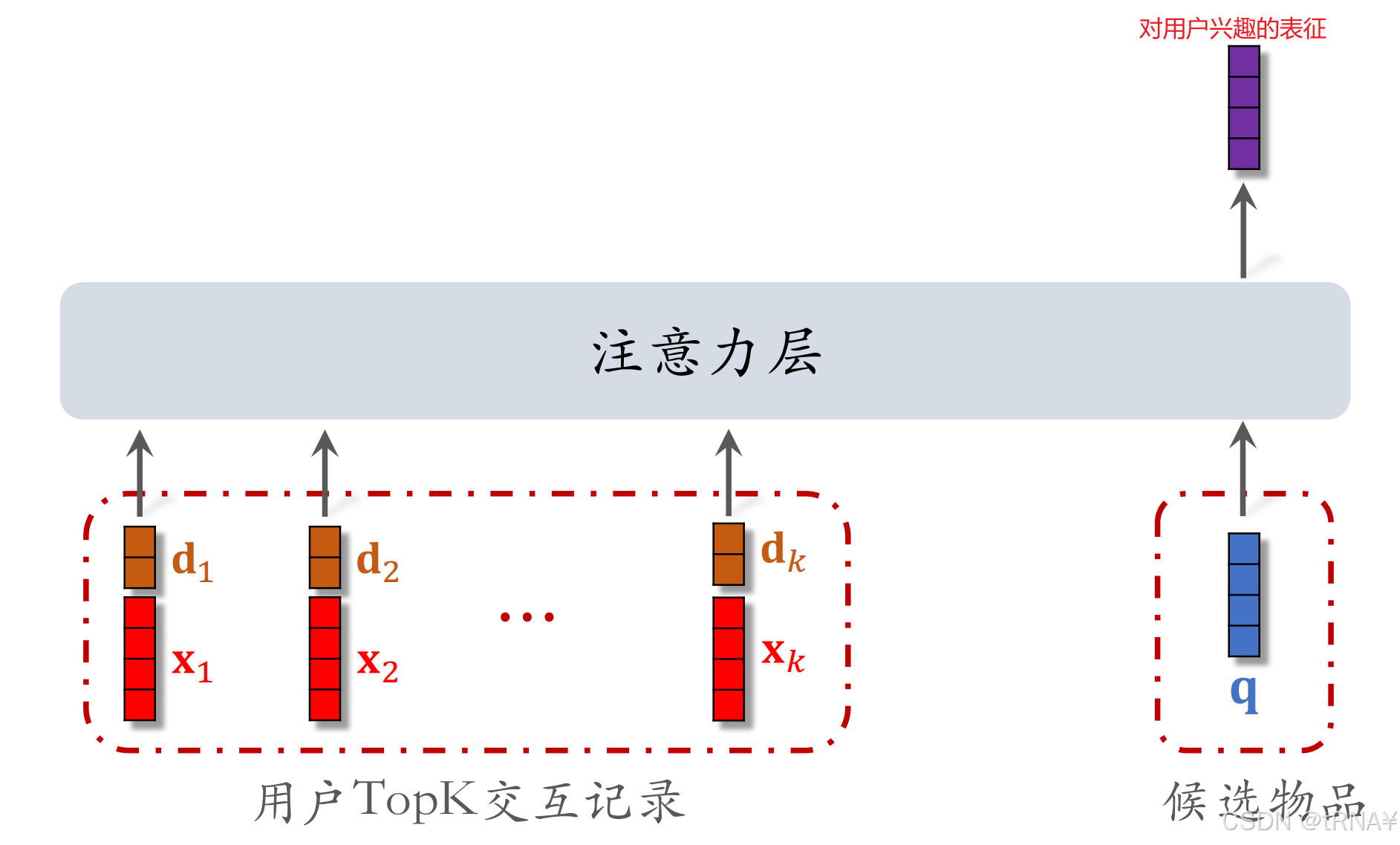
第二步:注意力机制
trick:使用时间信息,即记录用户与每个物品交互发生的时刻d
- 用户与某个LastN物品的交互时刻距今为δ。比如发生在1000h前,δ=1000
- δ是连续值,对其做离散化(划分为很多区间,比如发生在最近1/7/30天/1年/1年以上),再做embedding,变成向量d
- 把两个向量做concatenation,表征一个LastN物品
- 向量x是物品embedding
- 向量d是时间的embedding
- 候选物品不需要对其时间做Embedding
WHY SIM使用时间信息?
- DIN的序列短,记录用户近期行为(只记录用户最近交互过的100~200个物品),无需考虑时间信息
- SIM的序列长,记录用户长期行为。LastN列表中的物品可能是一年前,或十分钟前的交互,重要性不同(时间越久远,重要性越低)
结论
- 长序列(长期兴趣) 优于 短序列(近期兴趣)
- 论文对比了两种机制:先做查找再做平均 or 先做查找再使用注意力
- 结论:注意力机制 优于 简单平均
- 使用时间信息有提升
5.4思考问题(复习回顾)
用户last-n序列特征是什么?有哪两种方法处理last-n序列特征?
平均后的last-n序列特征可以用于训练那些模型?
DIN的原理?本质?和平均有什么不同?哪个效果更好?
DIN有什么缺点?
DIN的缺点如何改进?
SIM的原理?步骤?
查找有那两种方法?各有什么特点?原理是什么?

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









