







4.1FM因式分解机
在模型的基础上加了交叉特征,可以让模型的效果更好,预测结果更准确
线性模型
d个特征之间只有相加、没有相乘,也就是说特征之间没有交叉
W是一个参数矩阵

二阶交叉特征
- xixj是两个特征的交叉,uij是交叉特征的权重
- 大多数参数是模型交叉特征的权重u。如果d很大,参数数量太大,计算代价大,且容易出现overfitting
用特征交叉的话,两个特征不仅能相加,还能相乘,这样可以提升模型的表达能力
我们用一个现实的例子来理解,比如我们要预估一个二手房的价格,单用面积和地理位置都不能很好的预测结果,将两个特征交叉之后会有较准确的预测。结果

question:如何解决参数量过大的问题呢?
原理:矩阵分解,将u转化为两个矩阵相乘之后的值
前面我们提到了u是一个权重矩阵,我们知道矩阵是可以线性变换的,也就是通过矩阵乘法来预估u
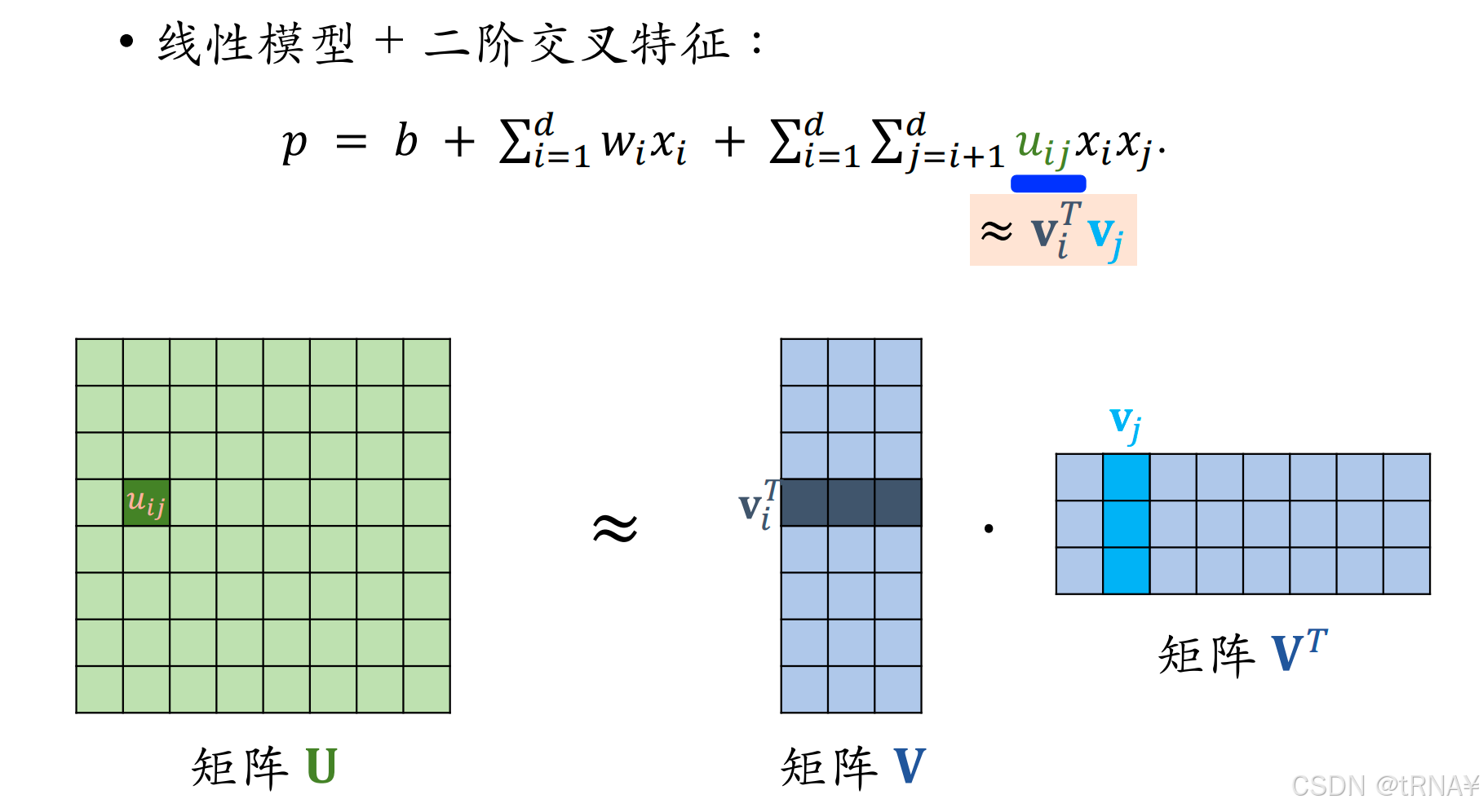
U矩阵有d行d列(d是参数数量),是个对称矩阵,可以对其做低秩近似:
- k << d,k是个超参数,由我们自己设置。k越大,矩阵V * V^T 就越接近矩阵U
- 此时 uij 就可以近似为 vi 和 vj 的内积
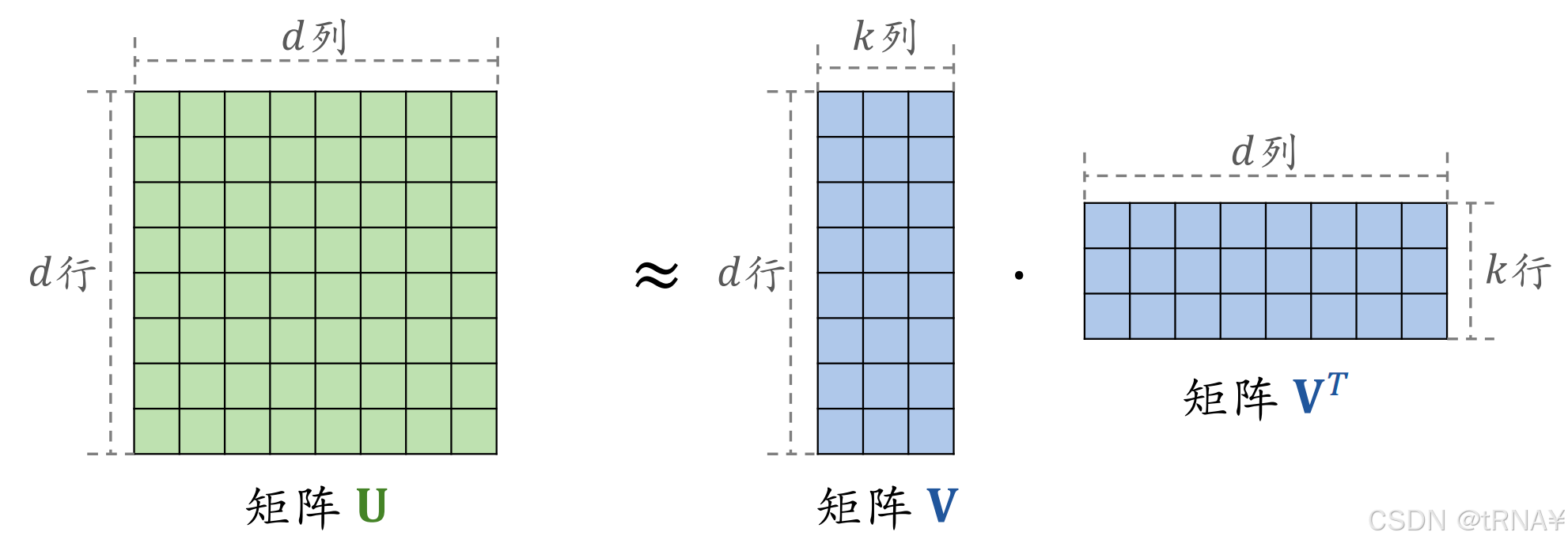
原问题转化为:

这样线性表达能力更强,减少了参数数量,可以避免过拟合
FM的优点

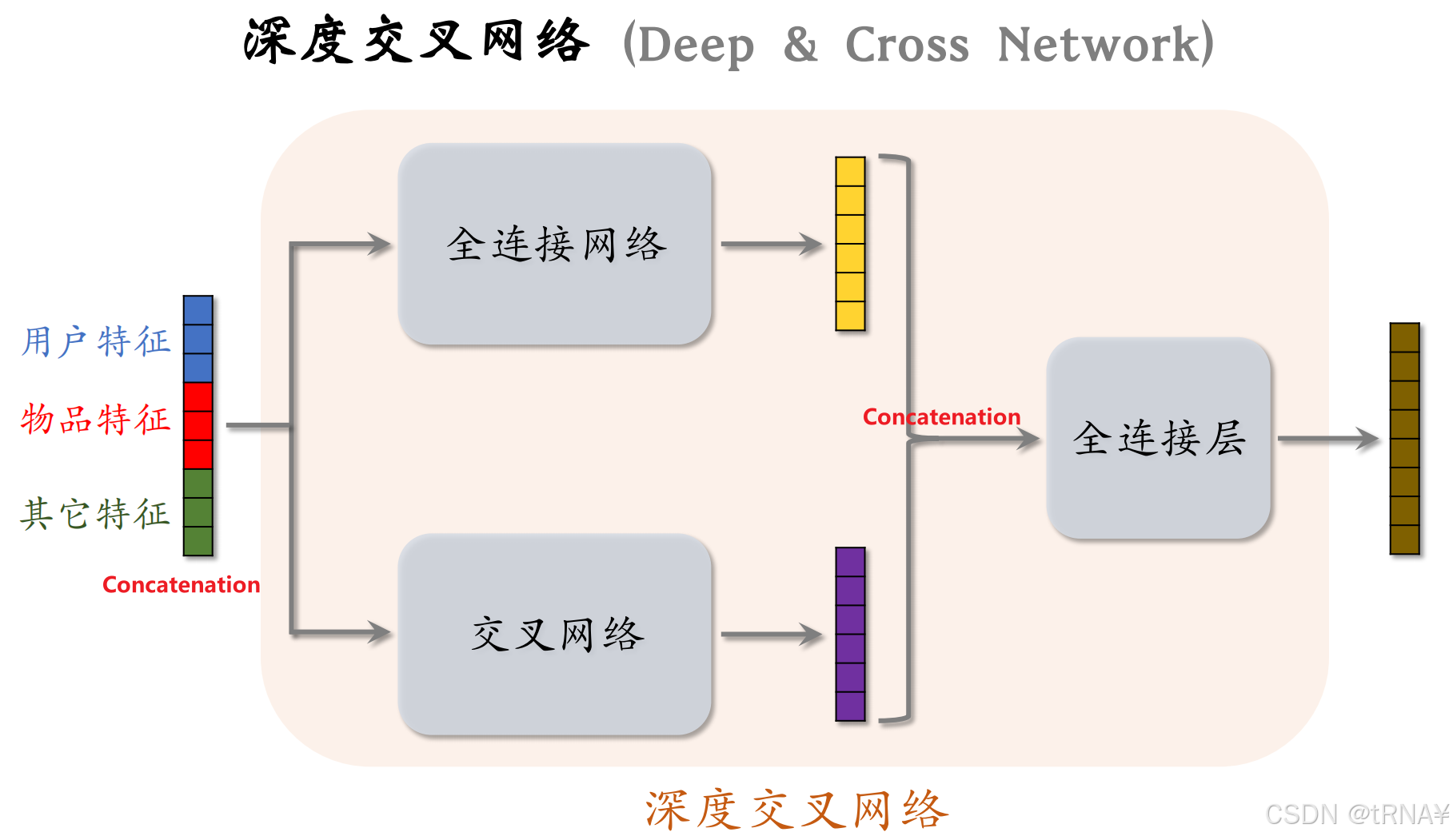
4.2DCN深度交叉网络
用来代替简单的全连接网络,既可以用来召回,也可以排序。
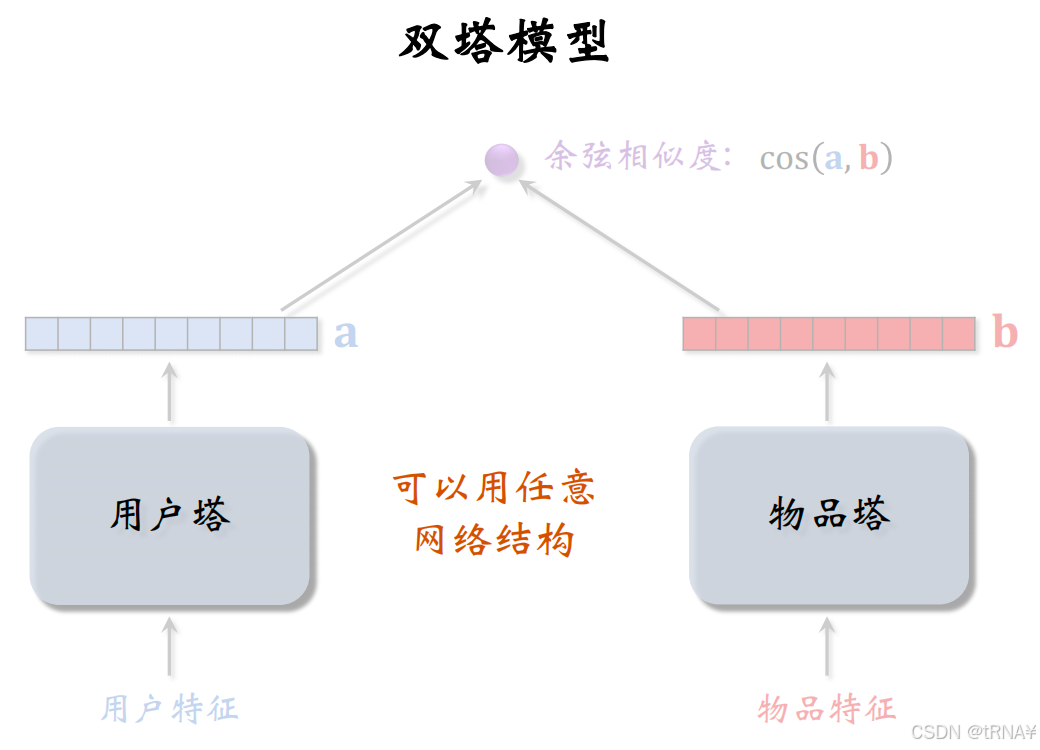
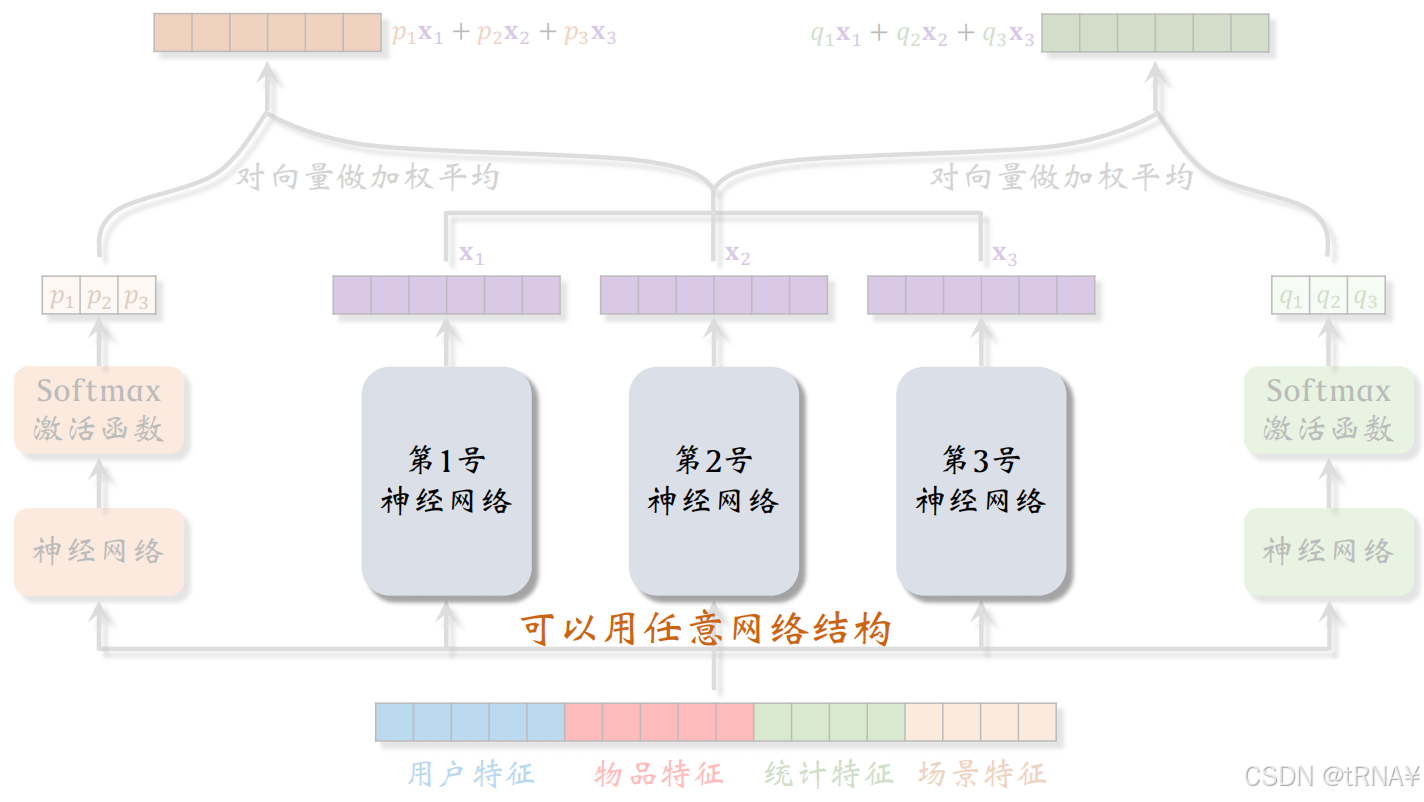
双塔模型
在双塔模型中,用户塔、物品塔可以用任意的神经网络结构,最简单的就是全连接神经网络,可以换为深度交叉网络DCN,效果更好
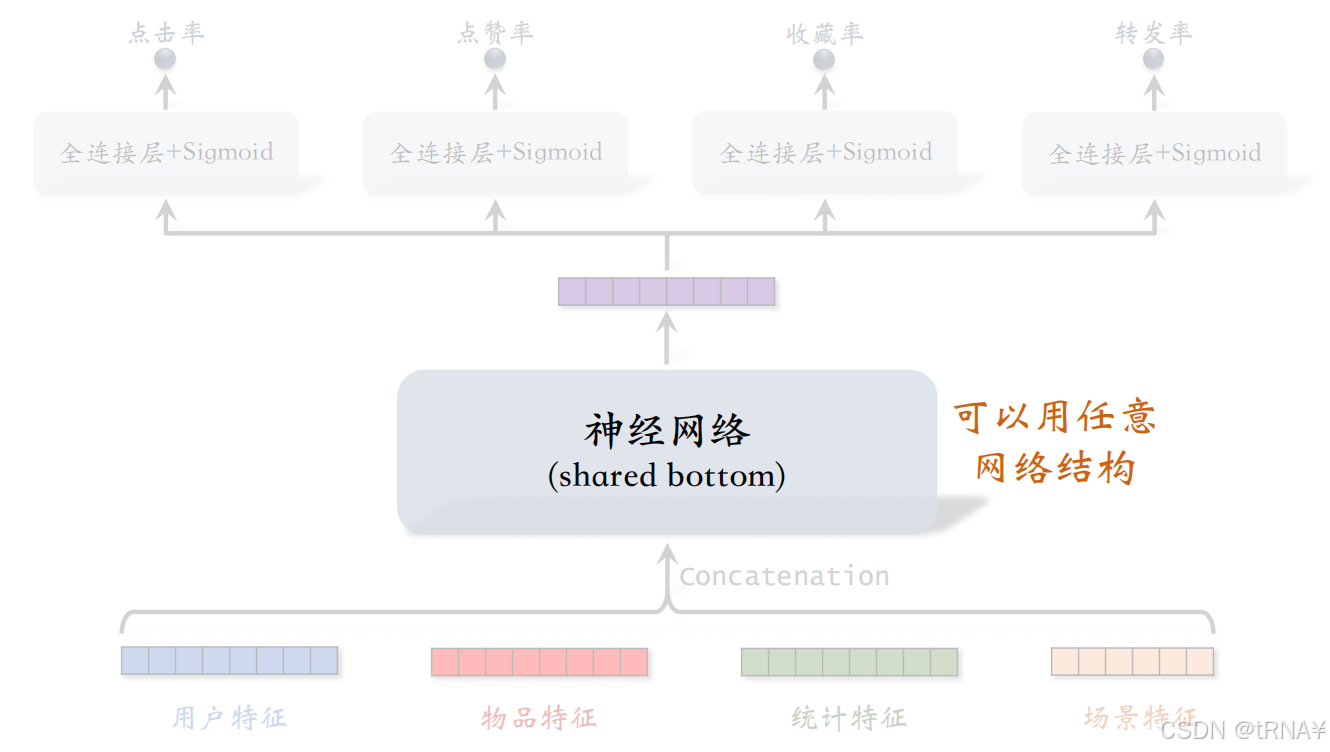
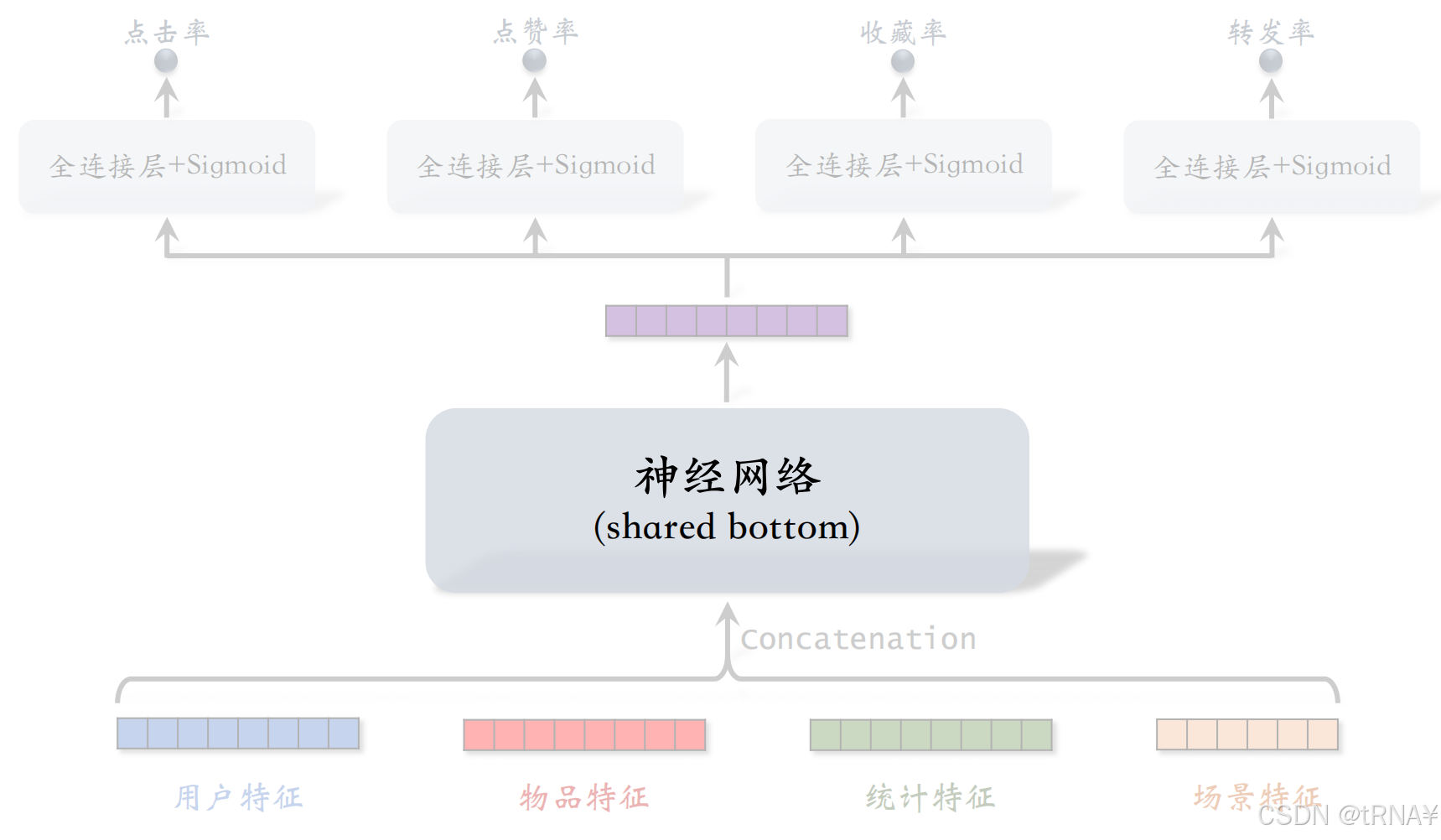
多目标模型
中间的神经网络被所有任务共享,所以叫做shared bottom。它的网络结构可以任意,最简单的实现就是用多个全连接层,如果用更好的神经网络结构如DCN,模型预估的准确性会更高
MMoE
这3个专家神经网络也可以用任意的结构,包括全连接网络、深度交叉网络等
交叉层
DCN的基本组成单元。每个交叉层的输入、输出都是向量,且形状(维度)相同
x0为输入,经过 i层 后神经网络的输出为xi,下面详细讲解第i个交叉层的结构:
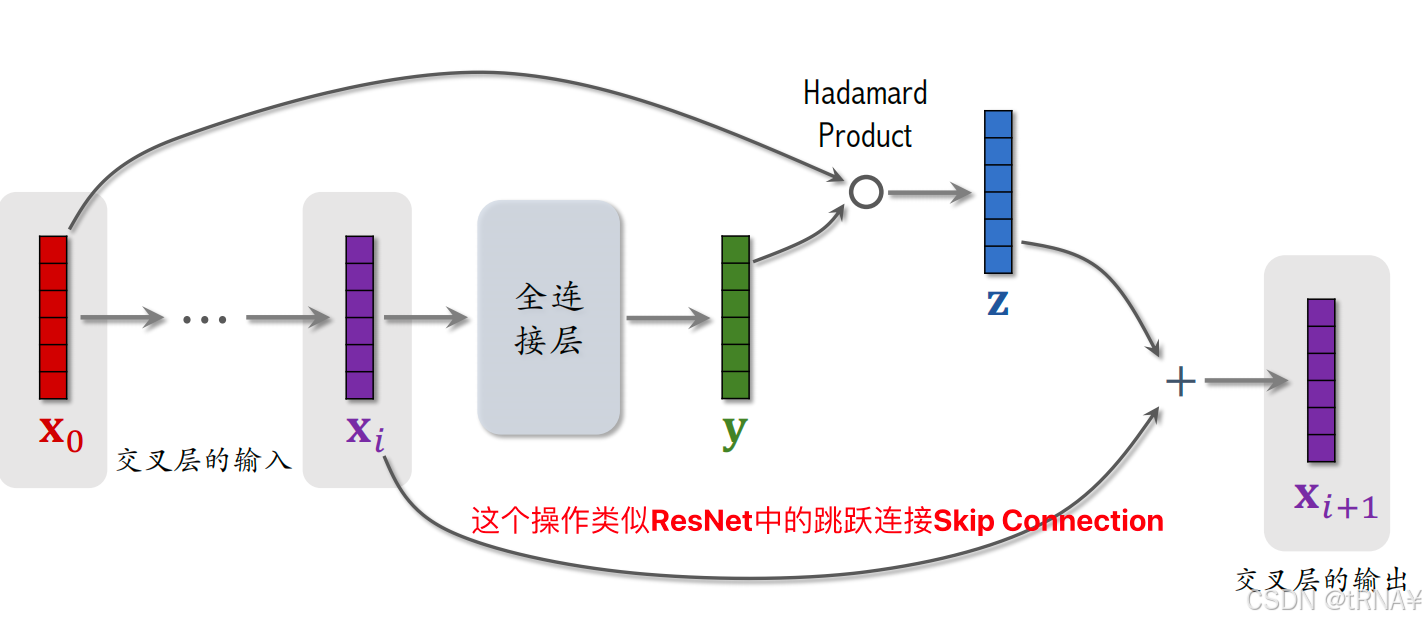
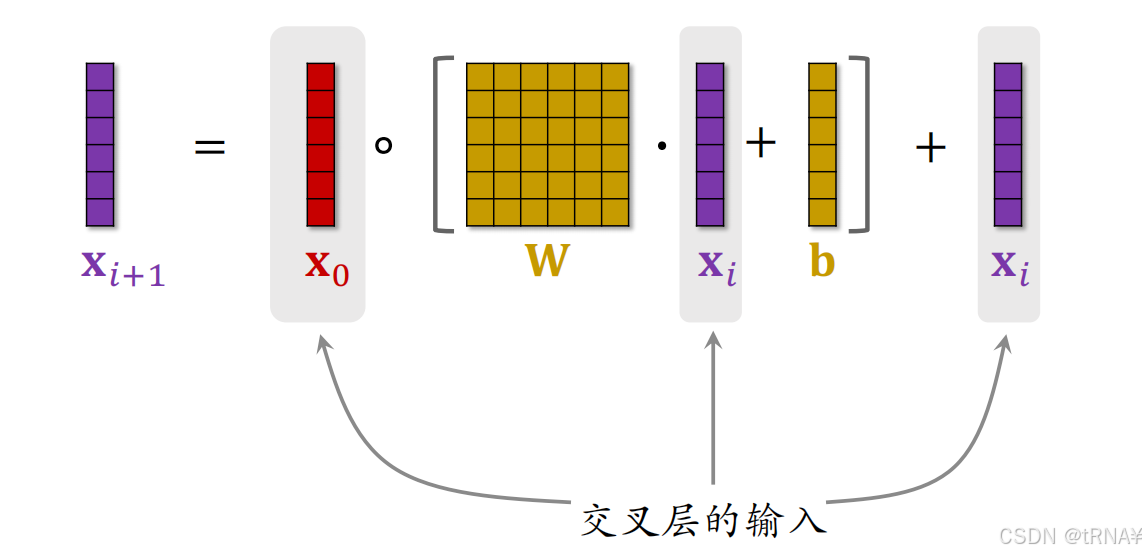
具体拆解Xi+1的计算步骤:
参数全在全连接层里,即W和b,需要在训练过程中用梯度去更新;其余操作为向量哈达玛积和向量加法,都没有参数
[ ]中的计算得出的是y
[ ]中的计算是在全连接层中计算的,X0和[ ]的乘积为哈达玛乘积(Hadamard Product):逐元素相乘,输入输出向量维度一致。因为是逐元素相乘,故要求输入维度一致
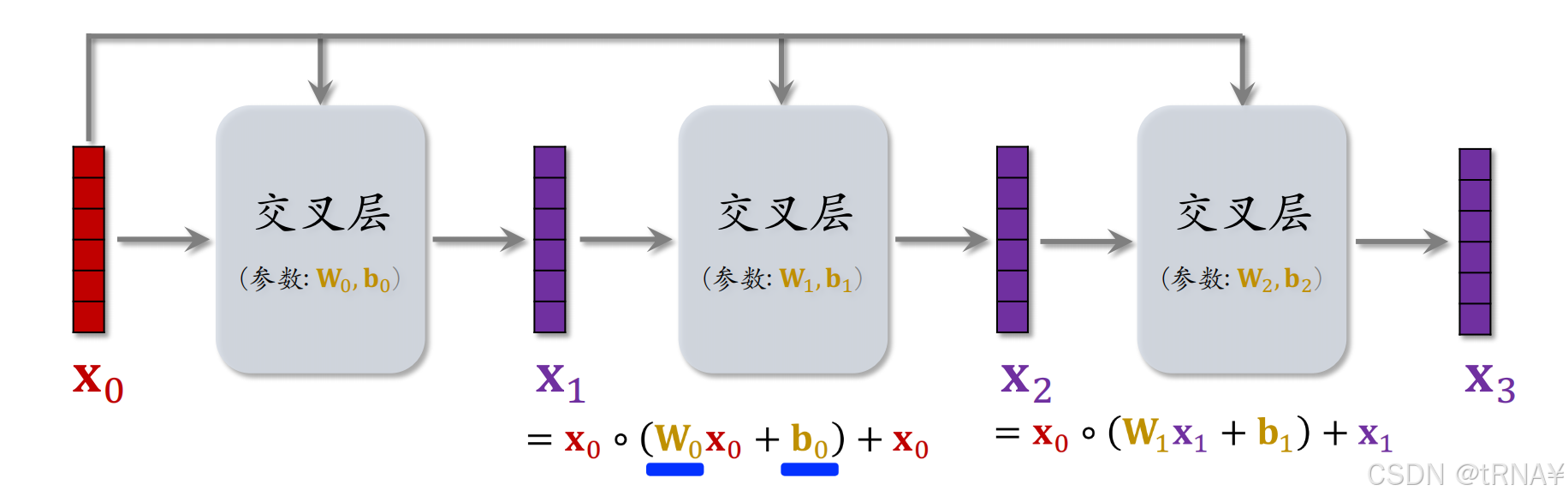
交叉网络
交叉网络是由多个交叉层组成的,在交叉网络中不断做矩阵计算
x_0向量是交叉网络的输入
深度交叉网络
结合交叉网络和全连接网络,两个网络并联;再加上全连接层,即为DCN
这里可以回顾一下FM是如何引入交叉特征的,就可以理解为什么结合交叉网络和全连接网络了。
最后的全连接层相当于在融合特征和交叉特征。
4.3LHUC(PPNet)
在工业界有效,只能用于精排
在多目标排序中的神经网络可以使用LHUC
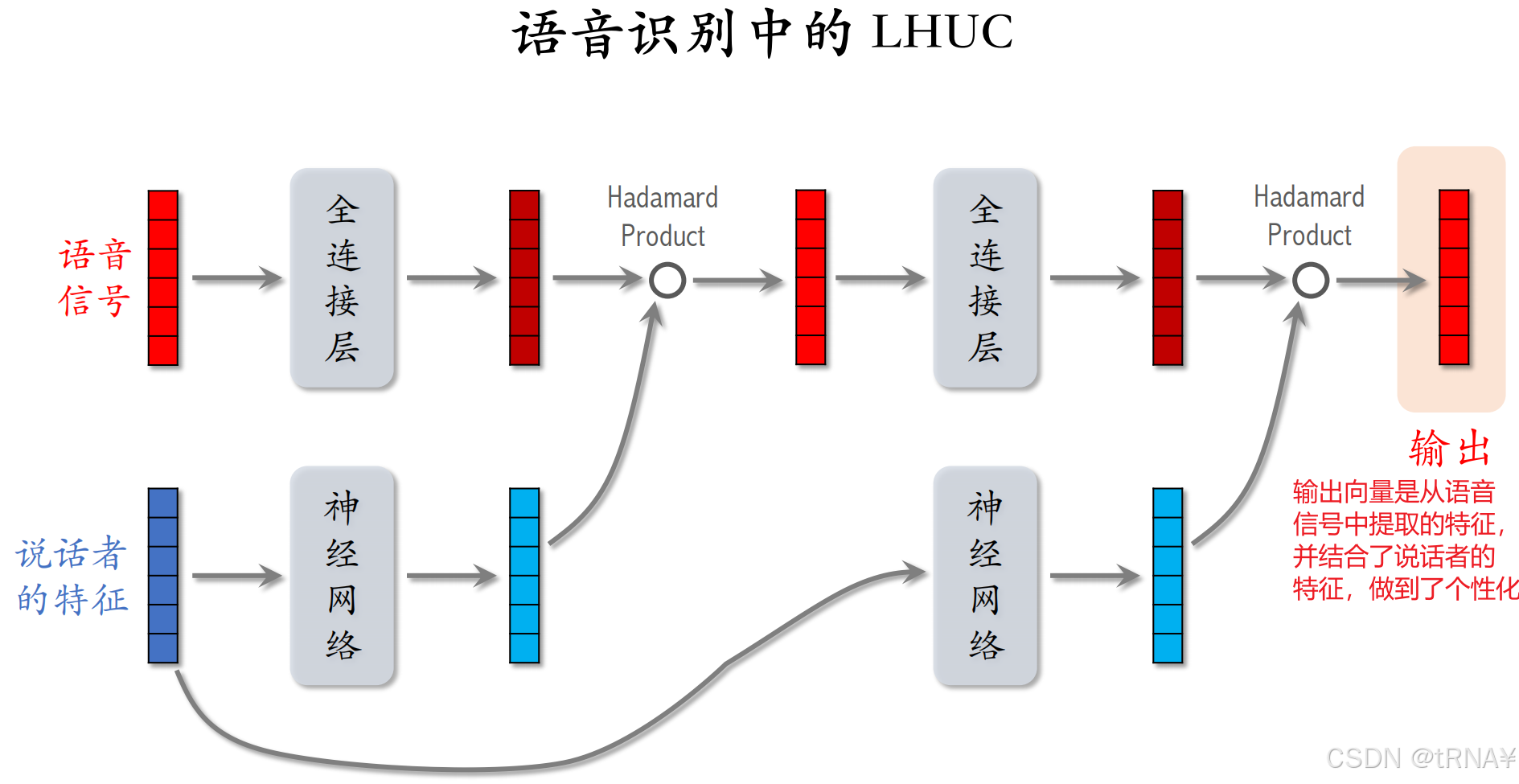
LHUC起源于语音识别
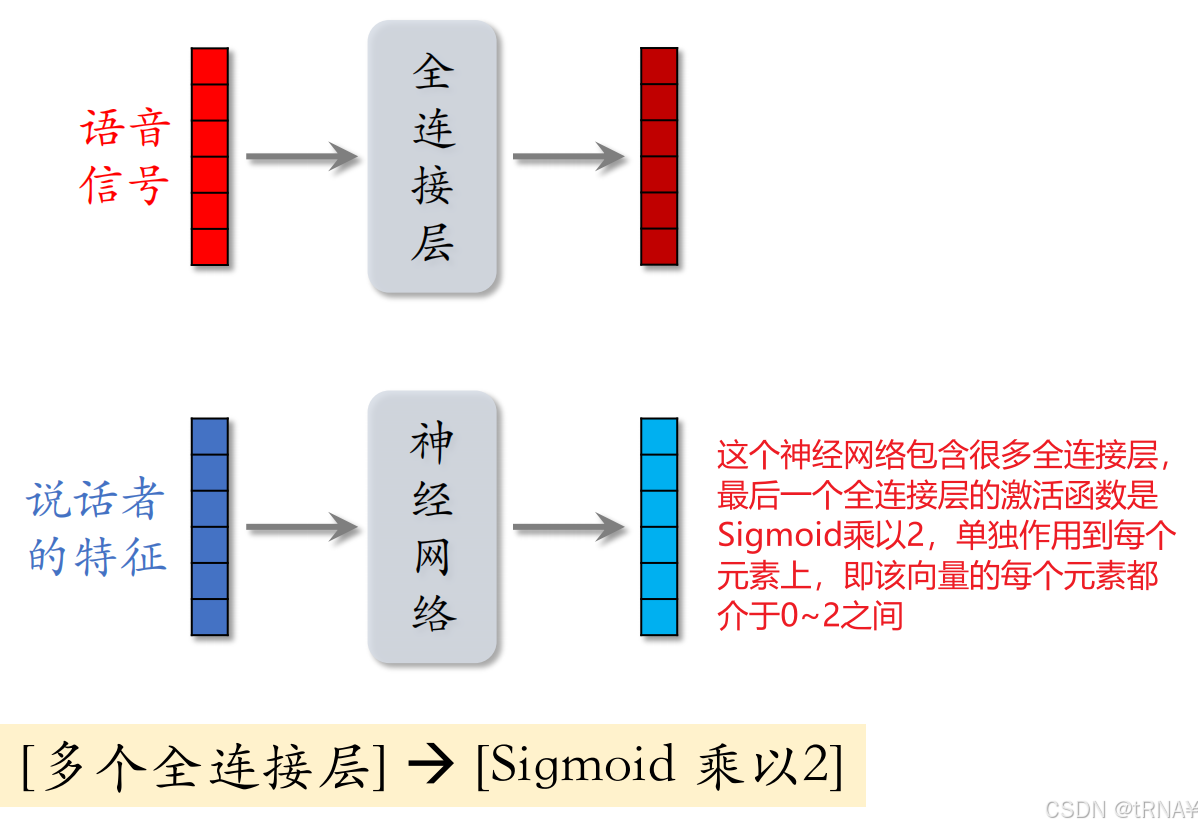
接下来我们看看LHUC在语音识别中是如何实现特征交叉的。
从图中我们可以看到依然是和DCN一样使用哈达玛乘积。
两个向量形状完全一致,这样才可以做哈达玛积(逐元素相乘
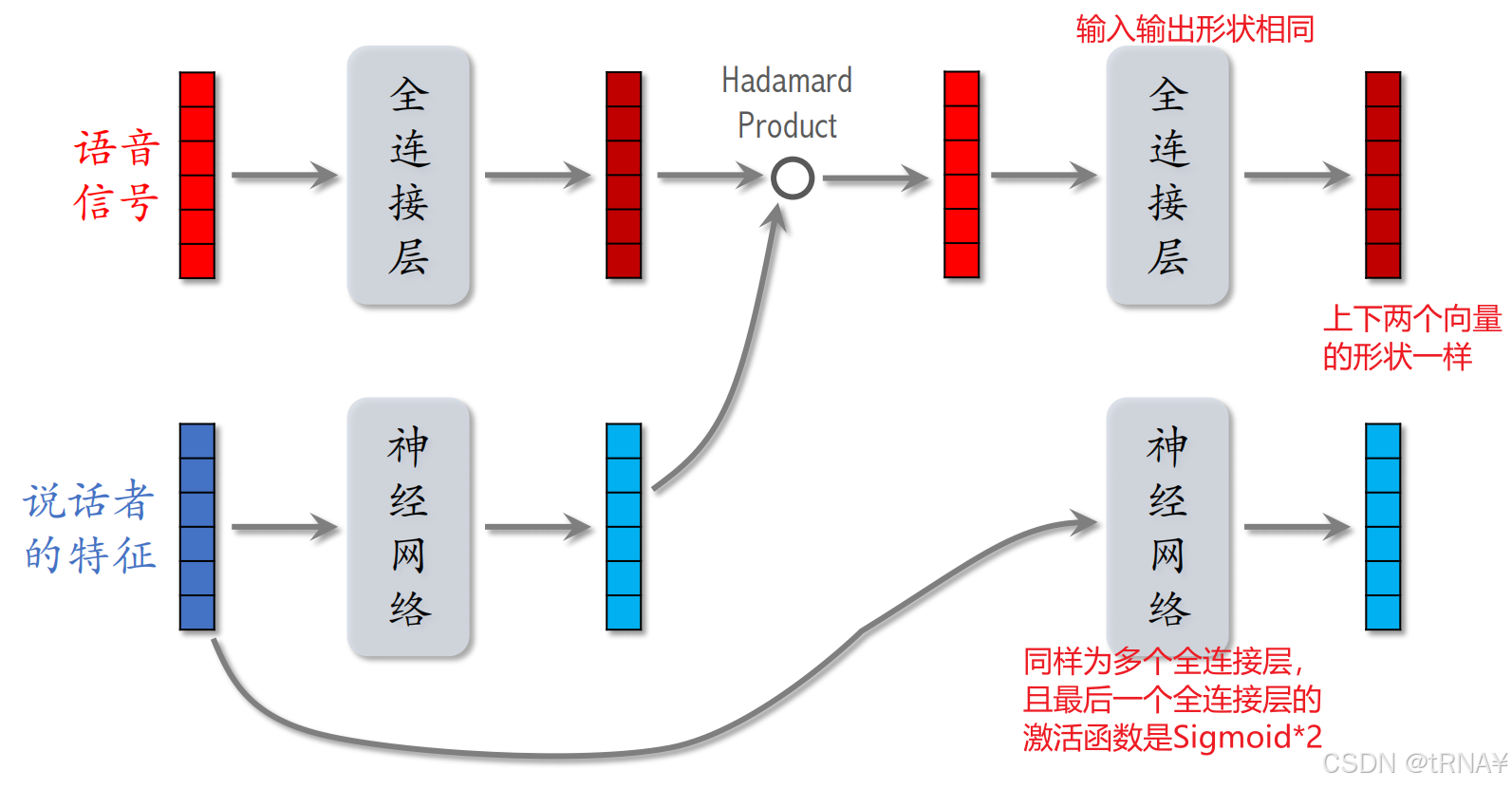
具体例子:LHUC重复了两个模块(做了两次哈达玛积),实践中想实现更深的网络也没有问题:

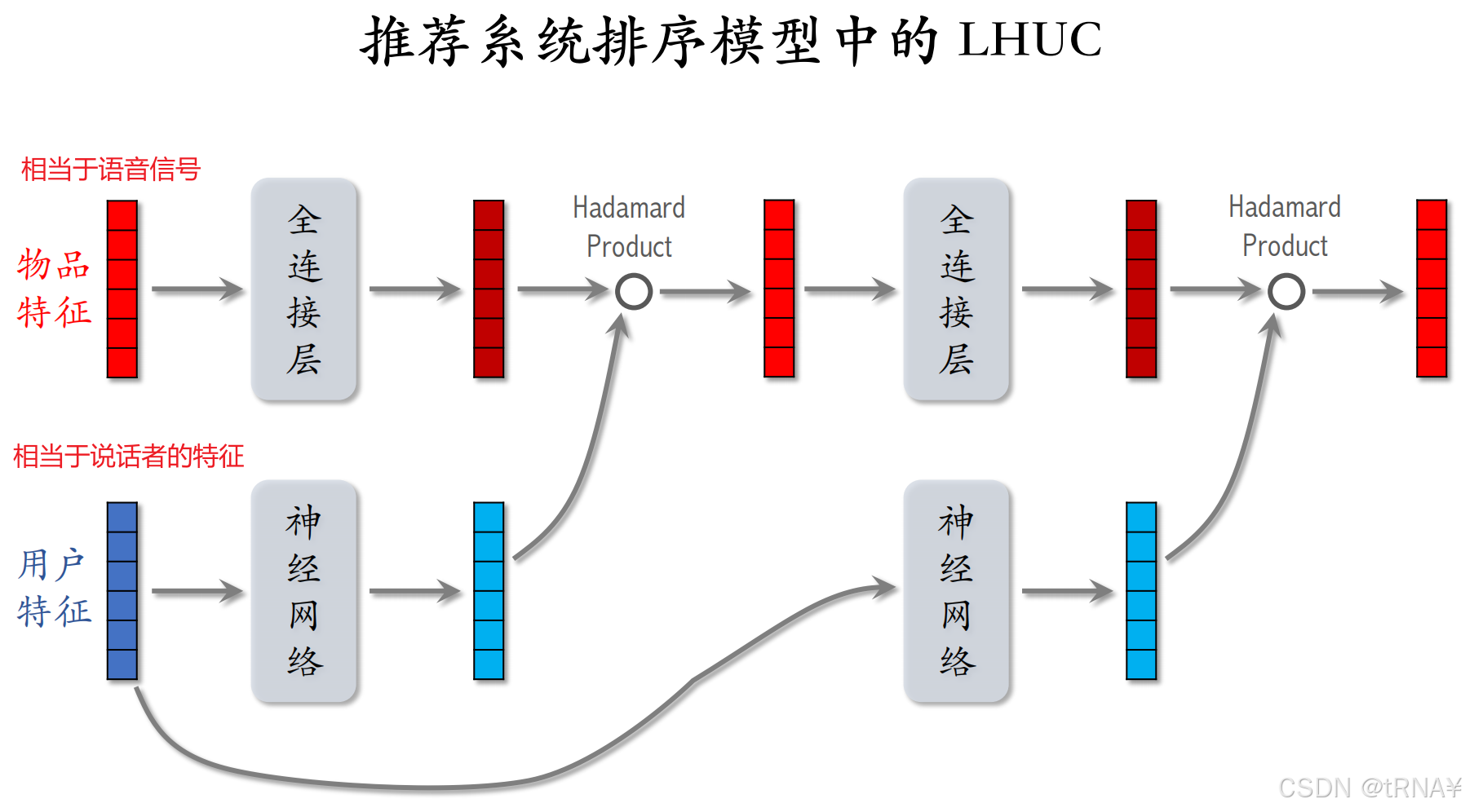
PPNet
快手将LHUC应用在推荐精排,称作PPNet
4.4SENet和Bilinear交叉
这两种方法用在排序模型上都有收益
SENet
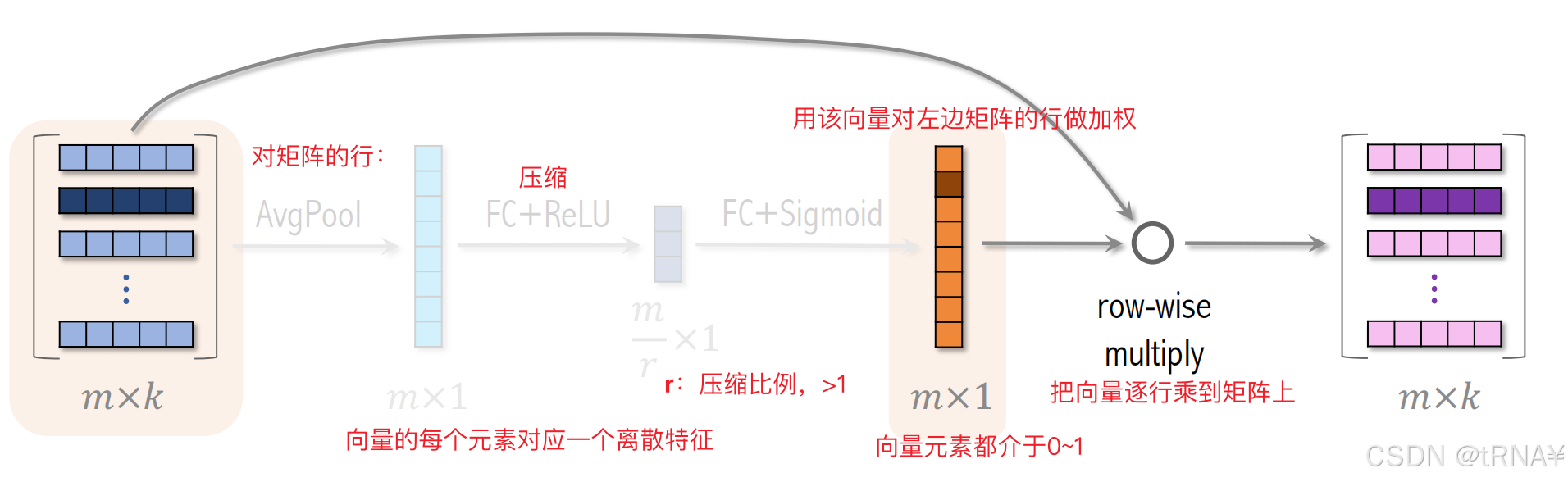
AvgPool后:向量的每一个元素对应一个特征。
FC+Relu后:对特征做压缩,r>1
Fc+Sigmoid:恢复出一个 m 维的向量,橙色向量的元素都介于0-1之间,使用橙色向量对输入向量进行加权,把向量逐行乘在矩阵上,得到粉色矩阵,大小与输入矩阵一样。
比方说学出物品 id 对物品重要性不高,那么就给物品 id emb降权。
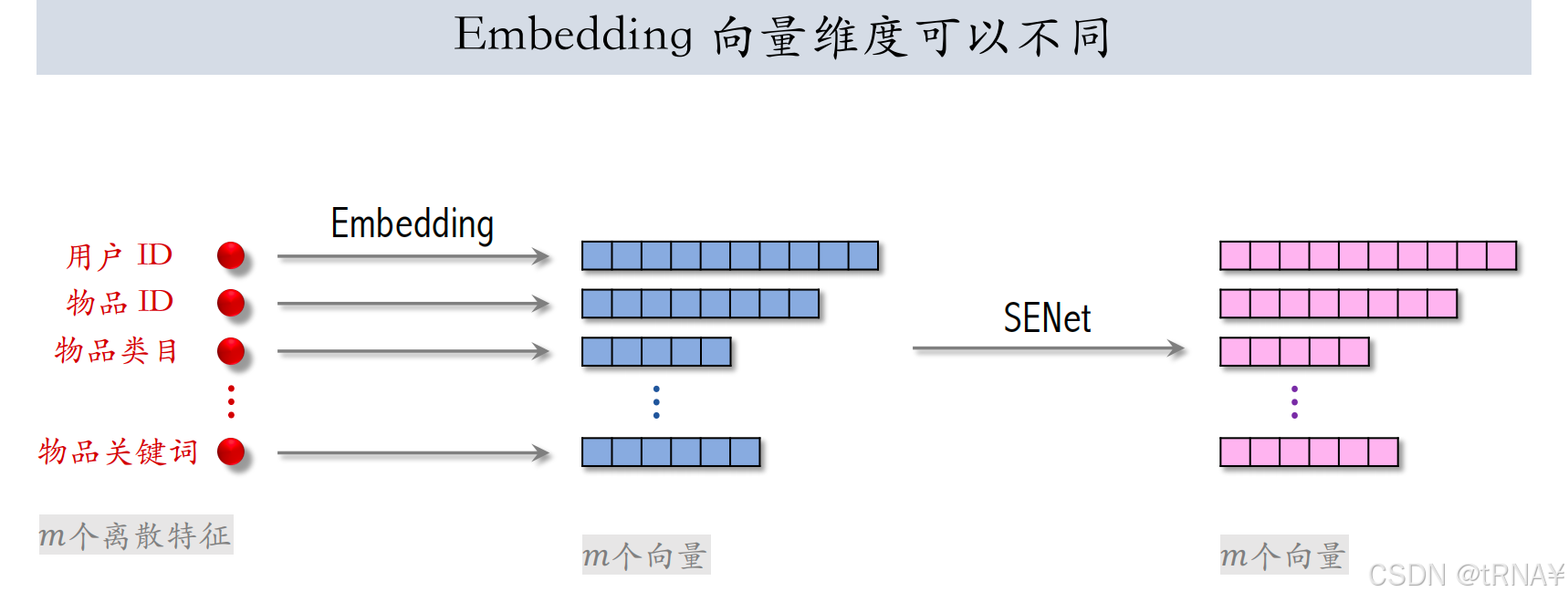
summary
- 本质对离散特征做 field-wise 加权。
- m个特征,m 个 fields(特征),权重向量 m维。 SENet 会根据所有特征自动判断每个 field的特征重要性,重要的field权重高。
Field间特征交叉
简单的特征交叉有以下两种方法:
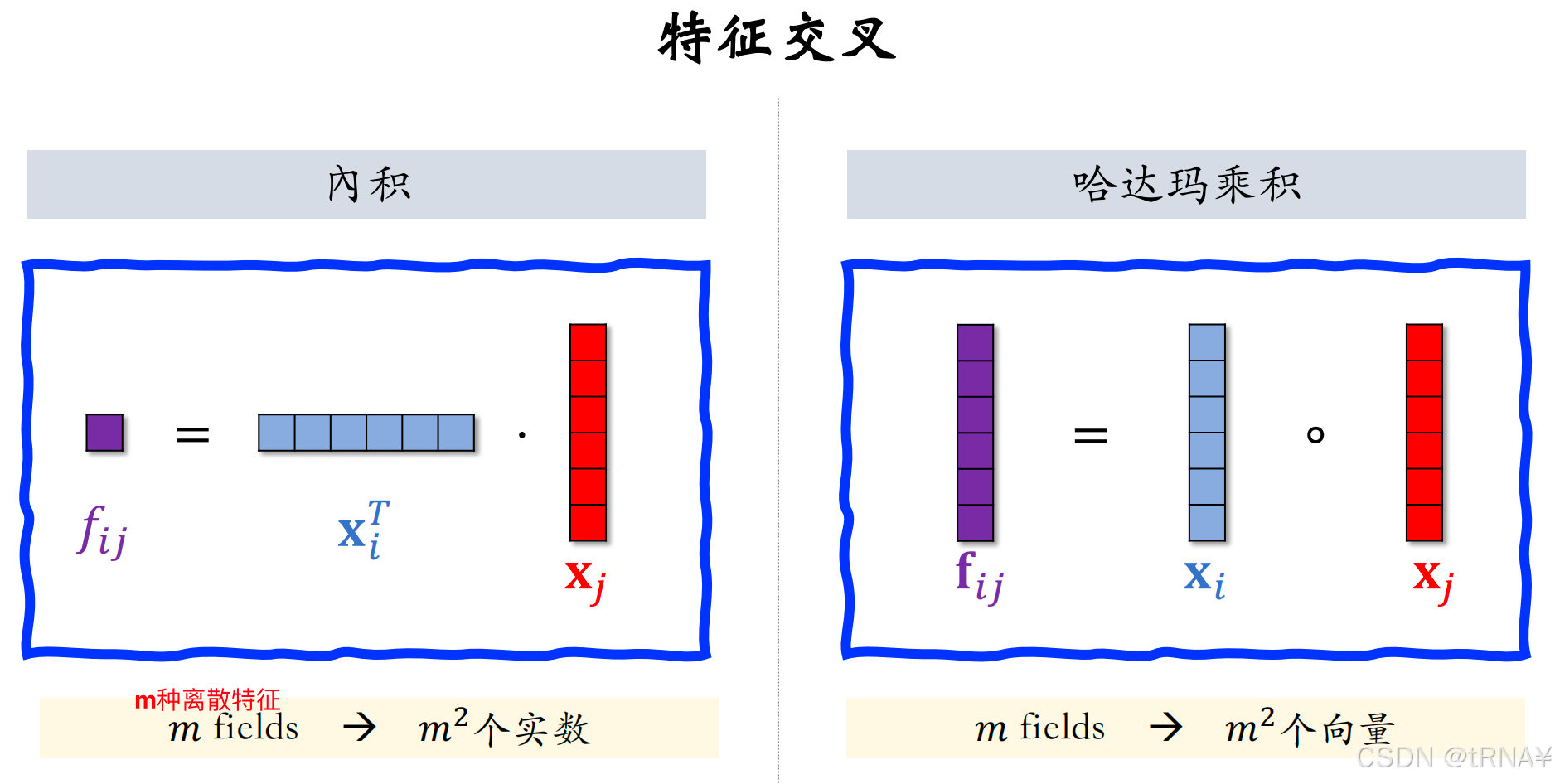
推荐系统中m(离散特征)的数量不是很大,量级也就几十
- 左侧内积,m^2个实数,可以接受
- 右侧哈达玛积(逐元素相乘),m^2个向量,不能接受。故一般人工选择一些pair交叉,不能对所有m fields两两交叉
不论是内积or哈达玛积,都要求每个特征的embedding向量形状一样,都是k维向量;若形状不同,无法计算内积or哈达玛积
Bilinear Cross
需要W参数矩阵,会导致参数数量过多
如何解决?
answer:指定一部分特征做特征交叉
方式1:内积
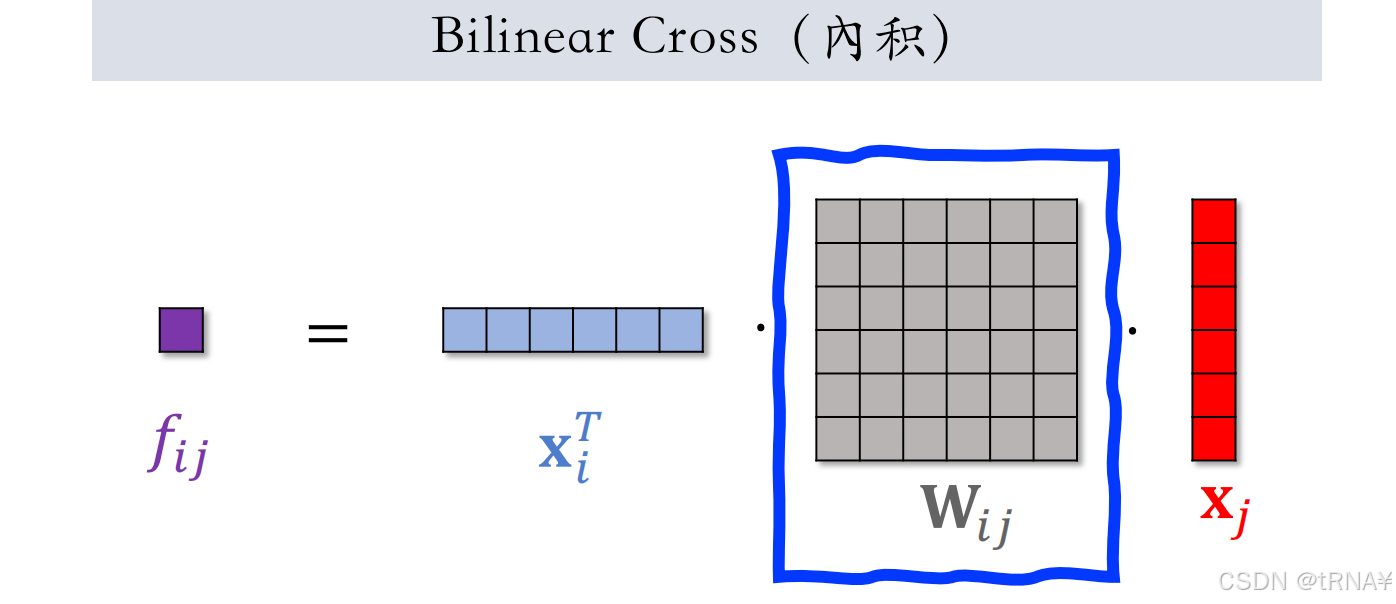
- Xi和Xj是两个特征的Embedding,它们的形状可以相同也可以不同
- f_ij是两个field的交叉。若有m个field,则会产生m^2个交叉特征(实数)(特征之间两两做交叉)
- W_ij为参数矩阵,若有m个field,则会产生 m^2 / 2 个参数矩阵。假如每个参数矩阵大小都是64*64,有1000个这样的参数矩阵,那么Bilinear Cross的参数量是400w
方式2:哈达玛积
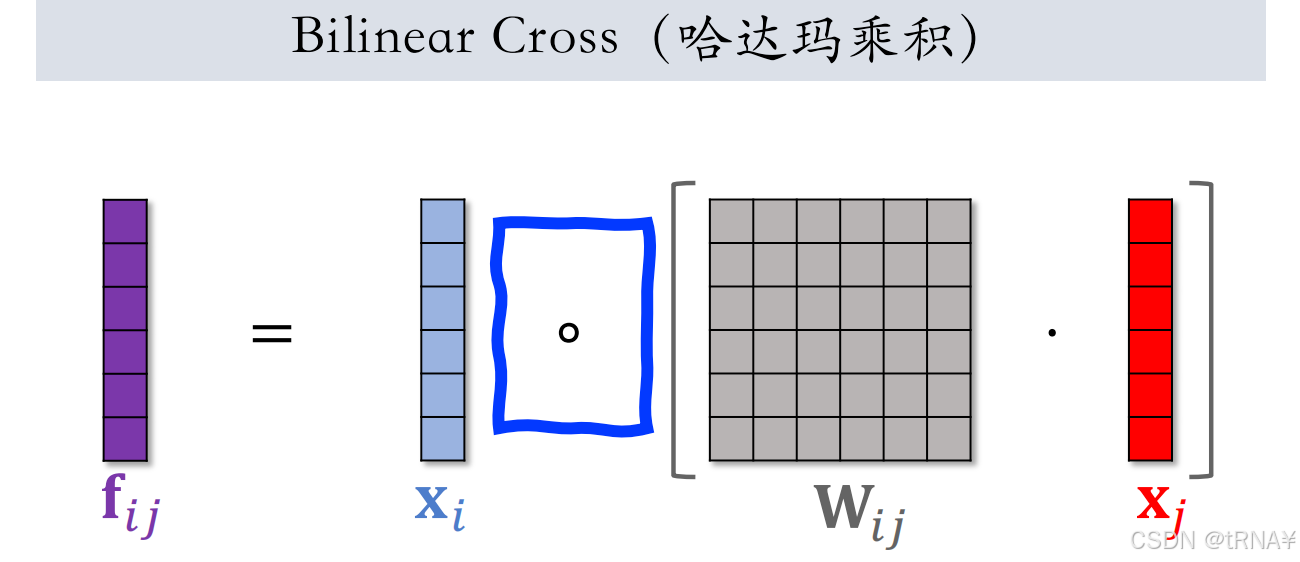
- 先把参数矩阵W_ij 和 特征向量x_j 相乘,得到一个向量;再求两个向量的哈达玛积(逐元素相乘)
- 输出向量f_ij。若有m个field,会产生m^2个向量,对m^2个向量做concatenation,得到的向量维度太大,且其中大多数都是无意义的特征
- 因此在实践中,最好人工指定一部分特征做交叉,这样既可以减少参数数量,也可以让concatenation之后的向量变小
FiBiNet = SENet + Bilinear Cross
FiBiNet在精排模型上有很好的效果
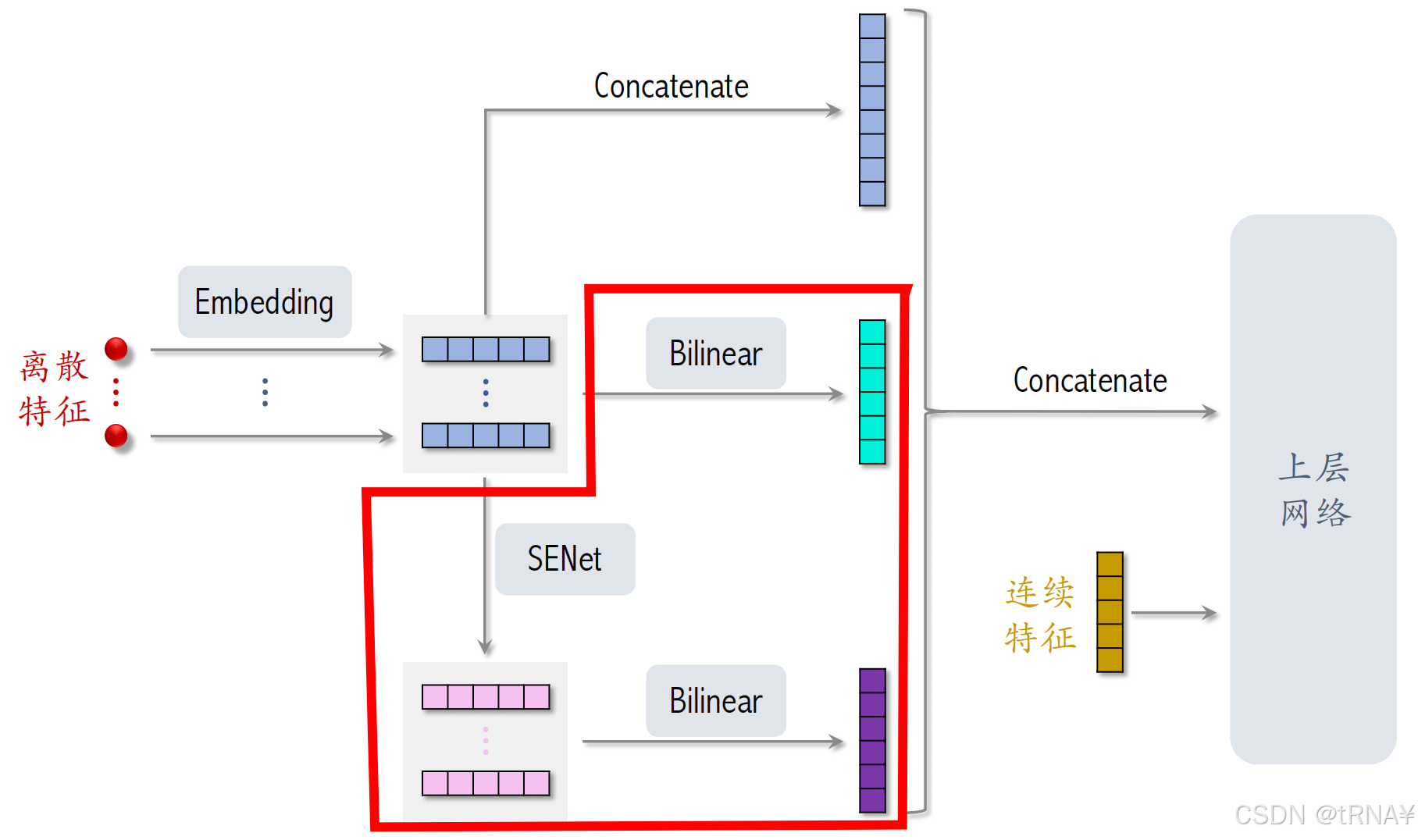
- FiBiNet还做了其他的特征变换
- 对这些embedding向量做Bilinear Cross,得到很多交叉特征,拼接成一个向量
- 用SENet对这些embedding向量做加权,得到同样大小的向量(代表不同特征的权重);再对这些向量做Bilinear Cross,得到很多交叉特征,拼接成一个向量
- 把FiBiNet对离散特征变换之后得到的特征向量、变换后的连续特征一起输入上层的神经网络
参考文章:
【下】王树森《小红书推荐系统公开课》- 课程笔记(特征交叉、行为序列、重排/推荐系统多样性、物品冷启动、涨指标的方法)_王树森推荐系统-优快云博客
4.5思考问题(复习回顾)
为什么要交叉特征?应用到召回,排序模型中会有更好的预测效果。
FM模型的原理?优点?
FM模型如何解决参数量过大的问题?
DCN的组成单元(层,网络,最终结构)
DCN交叉层中的结构是怎样的?
LHUC的原理(结构,如何实现特征交叉?)
SENet的结构(过程)
简单的特征交叉方法有哪些?
如何做field间交叉?Bilinear Cross有哪两种方式?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









