







3.1多目标排序模型
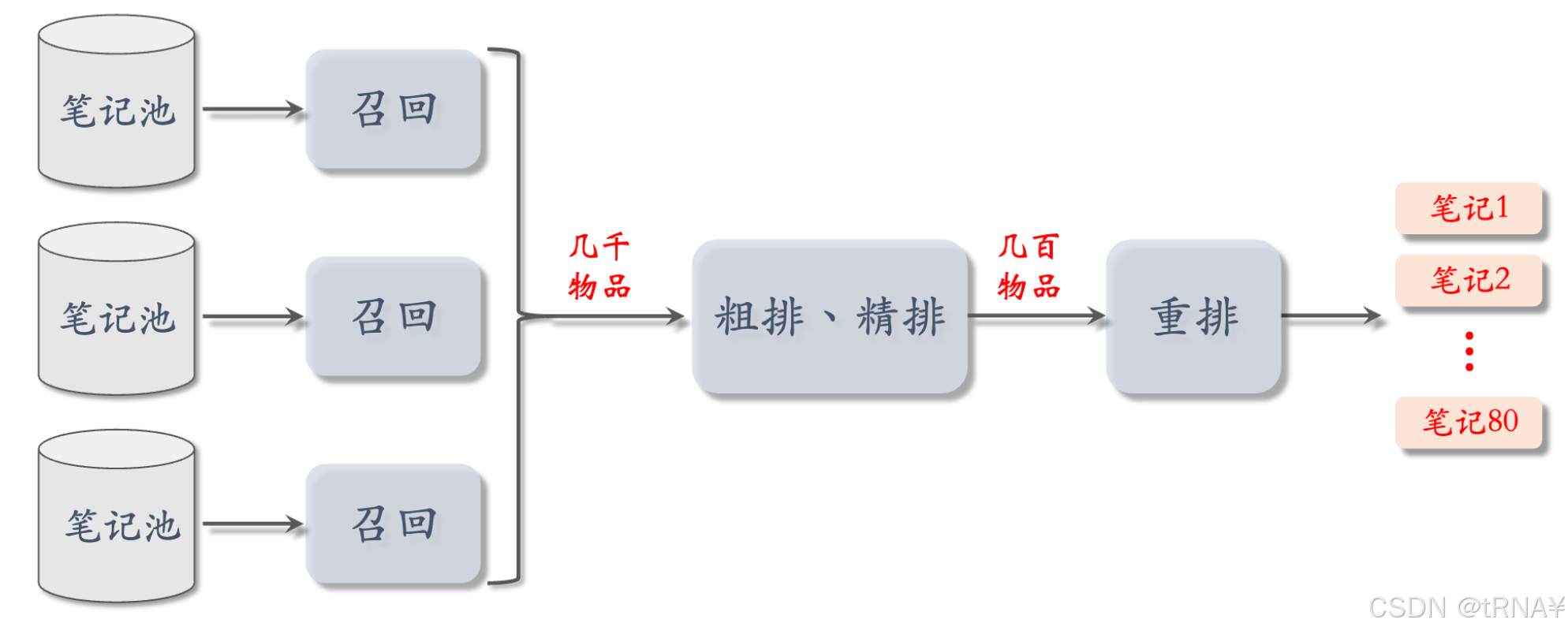
推荐系统链路
回顾一下第一章理解不同步骤之间的目标和联系,还有基础的指标定义:第一章 推荐系统基础(王树森学习笔记)-优快云博客
- 有很多条召回通道,从几亿篇笔记中取出几千篇
- 从中选出用户最感兴趣的,要用到粗排和精排,粗排给召回的笔记逐一打分,保留分数最高的几百篇
- 然后用精排模型给粗排选出的几百篇笔记打分,不做截断,让几百篇笔记全都带着精排分数进入重排
- 重排做多样性抽样,把相似内容打散,最终有几十篇笔记被选中,展示给用户
排序的依据
排序的依据其实就是用户对物品的感兴趣程度---感兴趣程度是由消费指标衡量的
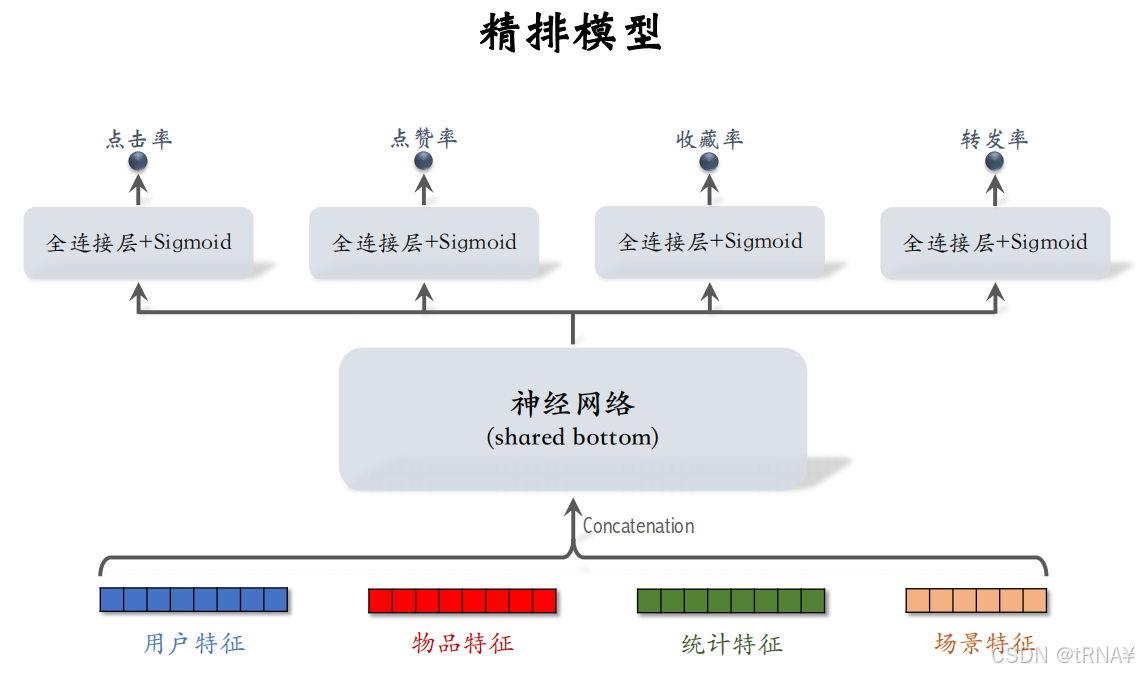
- 在把笔记展示给用户之前,需要事先预估用户对笔记的兴趣(排序模型预估点击率、点赞率、收藏率、转发率等多种分数);
- 融合这些预估分数,比如加权和(比如点击率的权重是1,点赞率、收藏率、转发率的权重是2),权重是做ab测试调出来的;
- 根据融合的分数做排序、截断,保留分数高的笔记
多目标模型
工业界基本上用的都是这种模型,该模型的目标是预估点击率,点赞率等指标
模型结构
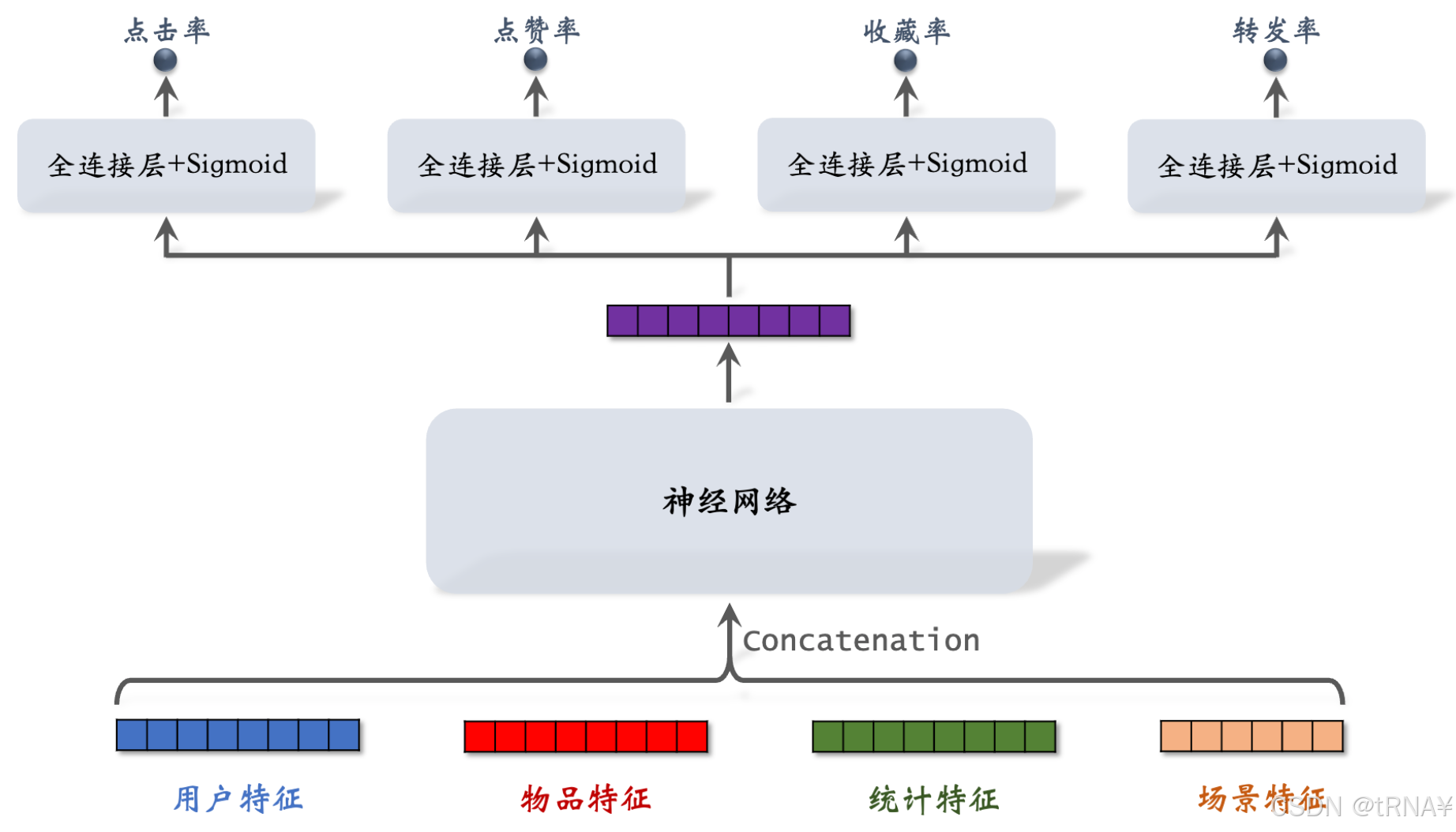
模型输入:向量
| 用户特征 | 用户ID、用户画像 |
| 物品特征 | 物品ID、物品画像、作者信息 |
| 统计特征 | 用户统计特征(用户在过去30天中一共曝光/点击...了多少篇笔记) 物品统计特征(候选物品在过去30天中一共获得了多少次曝光/点击...机会) |
| 场景特征 | 当前时间(如当前是否是周末或节假日) 用户所在地点(候选物品和用户是否在同一城市) |
输出
4个预估值,都介于0~1之间,排序主要依靠这4个预估值
训练
二元分类(0和1)用交叉熵损失函数。
目标是要最小化y和p的差值

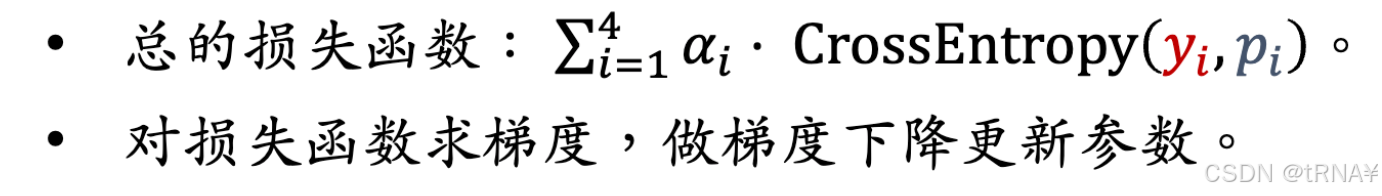
优化
梯度下降
训练中的困难
类别不平衡(正样本和负样本的数量不平衡,负样本很多)
解决:
负样本降采样(down-sampling)(ps这里可以回忆一下第二章召回中什么方法也用到了降采样)
- 保留一小部分负样本
- 让正负样本数量平衡,节约计算(比如原本一天积累的数据需要在集群上训练10h,做降采样后,负样本减少很多,训练只需3h)
预估值校准

很多人看到这里可能不明白为什么负样本变少会导致预估点击率大于真实点击率。
这是因为样本降采样之后,负样本的数量减少,负样本的比例就减少,正样本的比例就增加,也就是预估点击率会大于真实点击率。正样本就是用户感兴趣的物品。

对预估点击率的校准公式:左边的 表示校准之后的点击率,右边是对预估点击率
做的变换,α为采样率
在线上做排序时,首先让模型预估点击率,然后用上述公式做校准,拿校准之后的点击率
做排序的依据
3.2Multi-gate Mixture-of-Experts(MMOE)
模型结构
模型的目标也是预估用户的消费指标---用户对物品的感兴趣程度
输入:与多目标模型的输入一样
输出:预估的消费指标的值
- 3个神经网络结构相同,都是由很多全连接层组成,但它们不共享参数
- 3个神经网络各输出一个向量(后续用作求加权和)
- “专家”(实践中通常用4个或8个。专家神经网络的数量是个超参数,需要手动调)
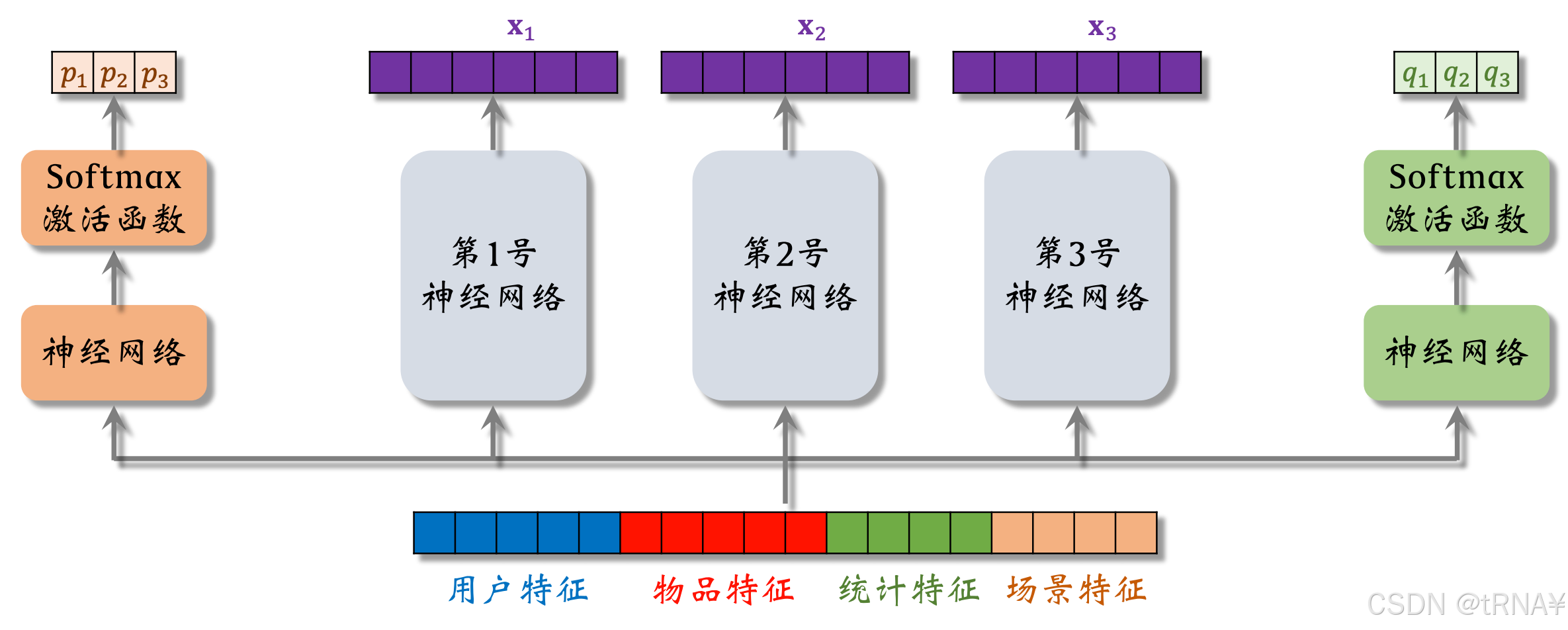
- softmax输出向量的3个元素都>0且相加为1
- p1~p3分别对应3个专家神经网络,之后会将这3个元素作为权重,对向量x1~x3做加权平均。q1~q3同理
加权平均
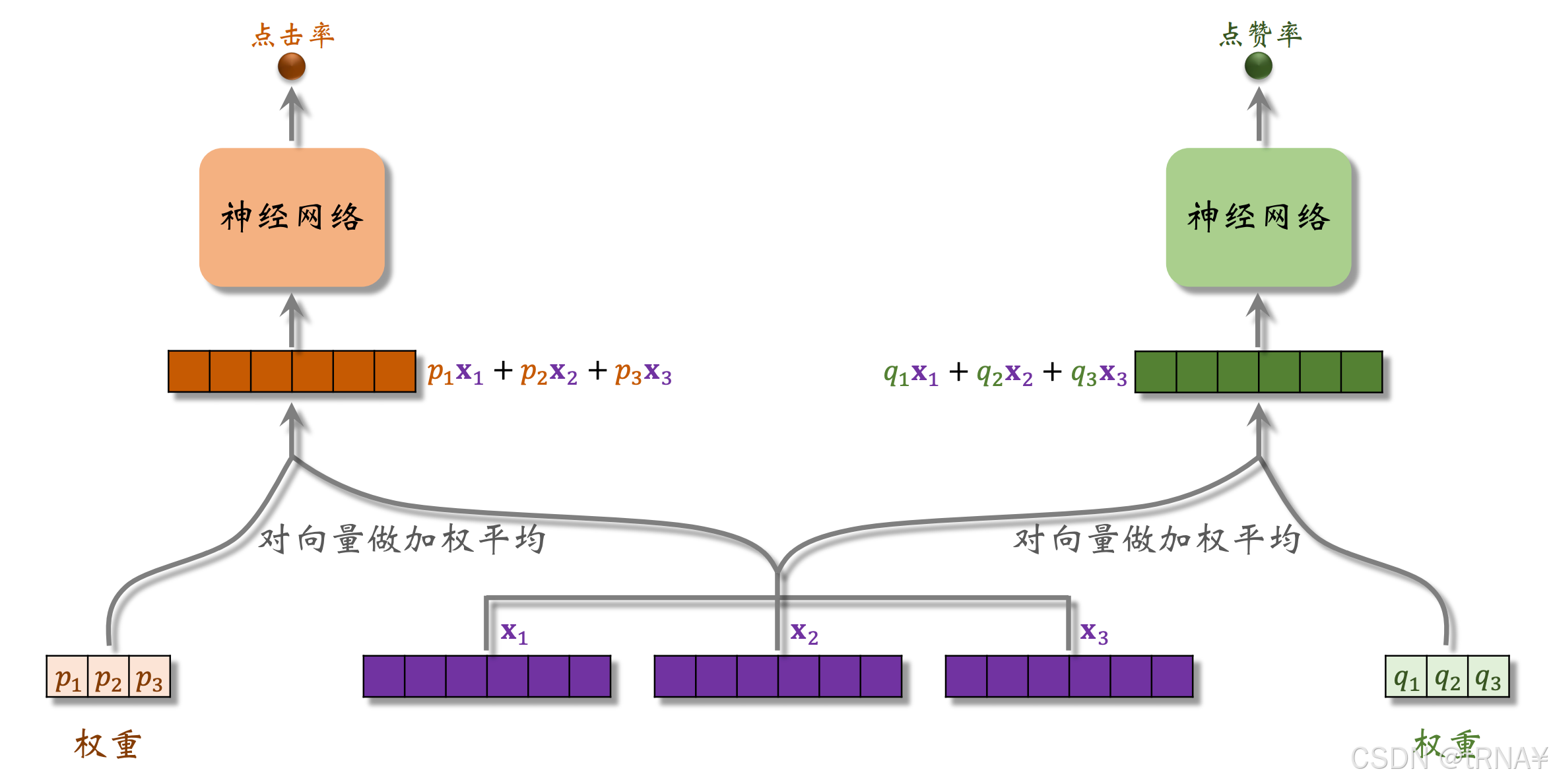
对神经网络输出的向量做加权平均,用加权平均得到的向量去预估某个业务指标。若多目标模型有n个目标,就要用n组权重
与多目标模型的区别:神经网络不共享参数,激活函数不同
极化现象
sofemax会发生极化,也就是softmax的输出值,有一个接近于1,其余值接近0;
这就意味着,我们只使用了一个专家(神经网络),而忽略了其他专家,没有对专家做融合
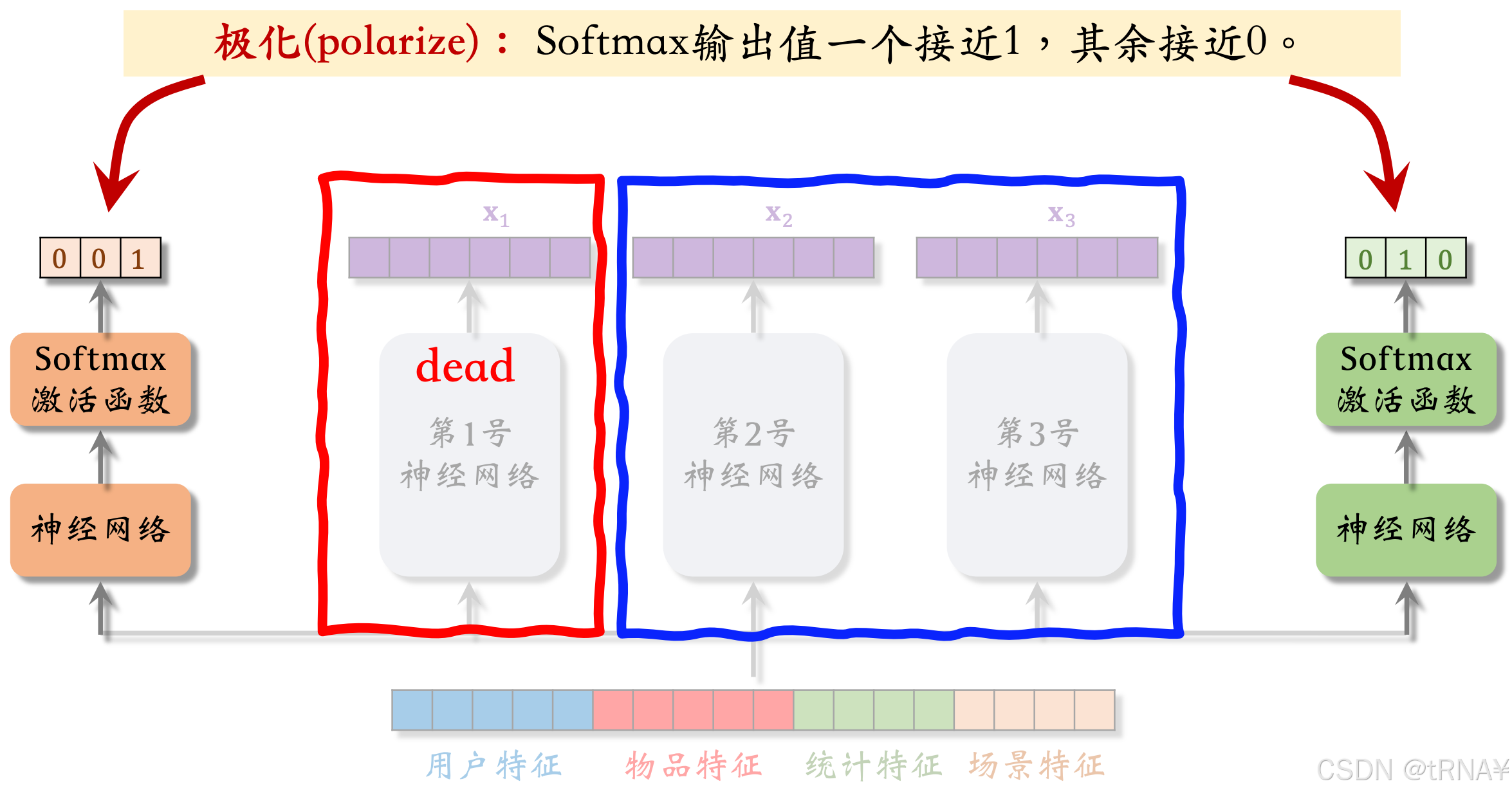
解决极化现象
解决方法:dropout
在训练时,对softmax的输出使用dropout,这样会强迫每个任务根据部分专家做预测
- softmax输出的n个数值被mask的概率都是10%
- 每个专家被随机丢弃的概率都是10%
如果用dropout,不太可能会发生极化,否则预测的结果会特别差。假如发生极化,softmax输出的某个元素接近1,万一这个元素被mask,预测的结果会错得离谱。为了让预测尽量精准,神经网络会尽量避免极化的发生,避免softmax输出的某个元素接近1。用了dropout,基本上能避免极化
最后,并不是使用了MMoE模型的效果就一定会好。
3.3预估分数融合
简单的加权和

点击率乘以其他项的加权和

海外某短视频APP的融分公式
Ptime是指预估短视频的观看时长,w1和α1都是超参数需要手动调,通过线上ab选出合适的值

国内某短视频APP的融分公式
不是直接用预估的分数,而是用每个分数的排名
α和β都是需要调的超参数。预估的播放时长越长,排名越靠前,越小,最终得分就越高

某电商的融分公式
指数α1~α4是超参数,需要调。若都为1,该公式就表示电商的营收,有很明确的物理意义

3.4视频播放建模
这一小节我们讨论播放时长和完播率两个指标
播放时长
图文 VS 视频
- 图文笔记排序的主要依据:点击、点赞、收藏、转发、评论...
- 视频排序的依据还有播放时长和完播
视频播放时长是连续变量,但直接用回归拟合效果不好,建议用YouTube的时长建模
神经网络Share Bottom(被所有任务共享),每个全连接层对应一个目标(比如点击、点赞、收藏、播放时长),这里只关心播放时长的预估:
我们观察图中y和p的形式,它们是非常相似的;这就意味着我们可以用exp(z)来作t(播放时长)的预估
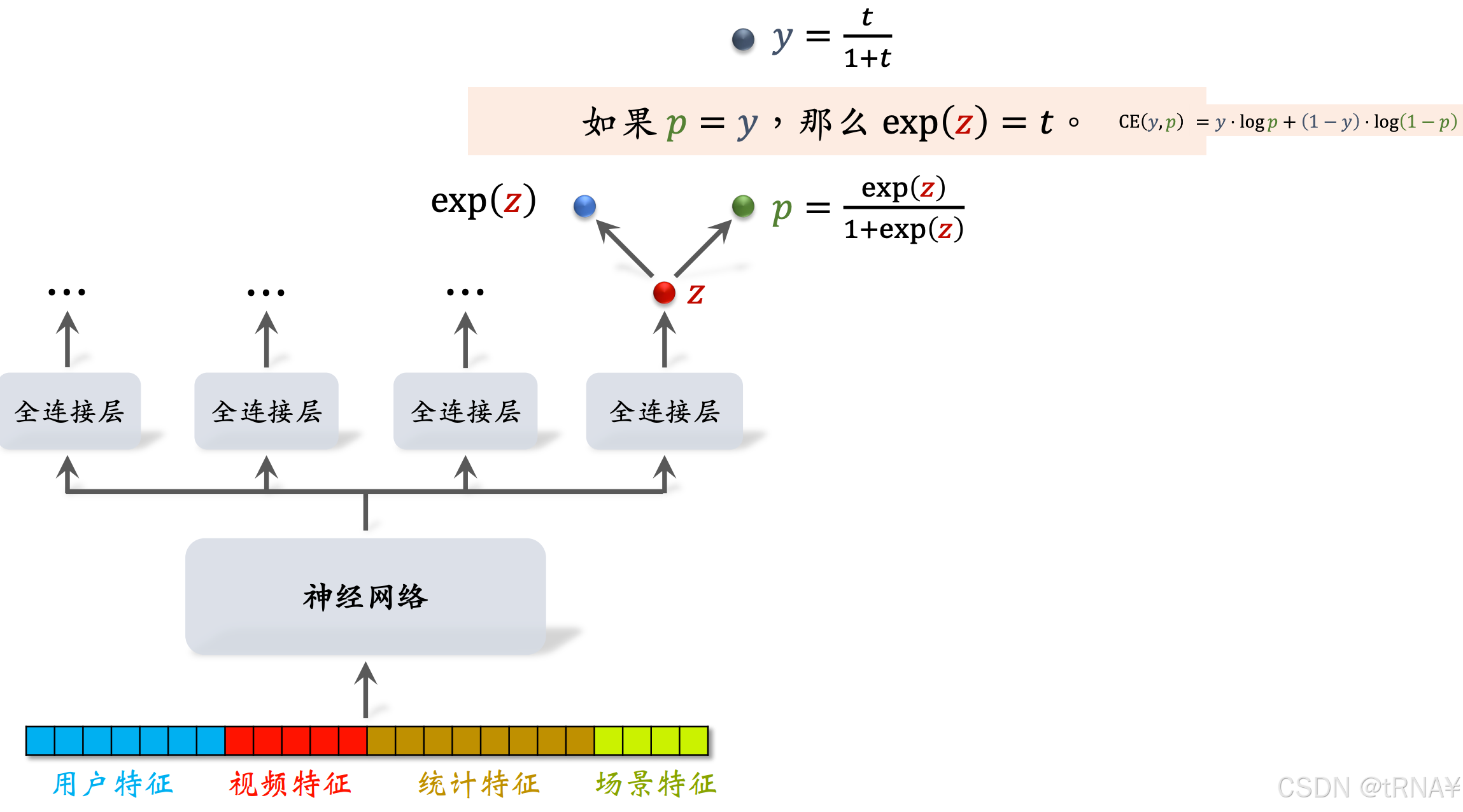
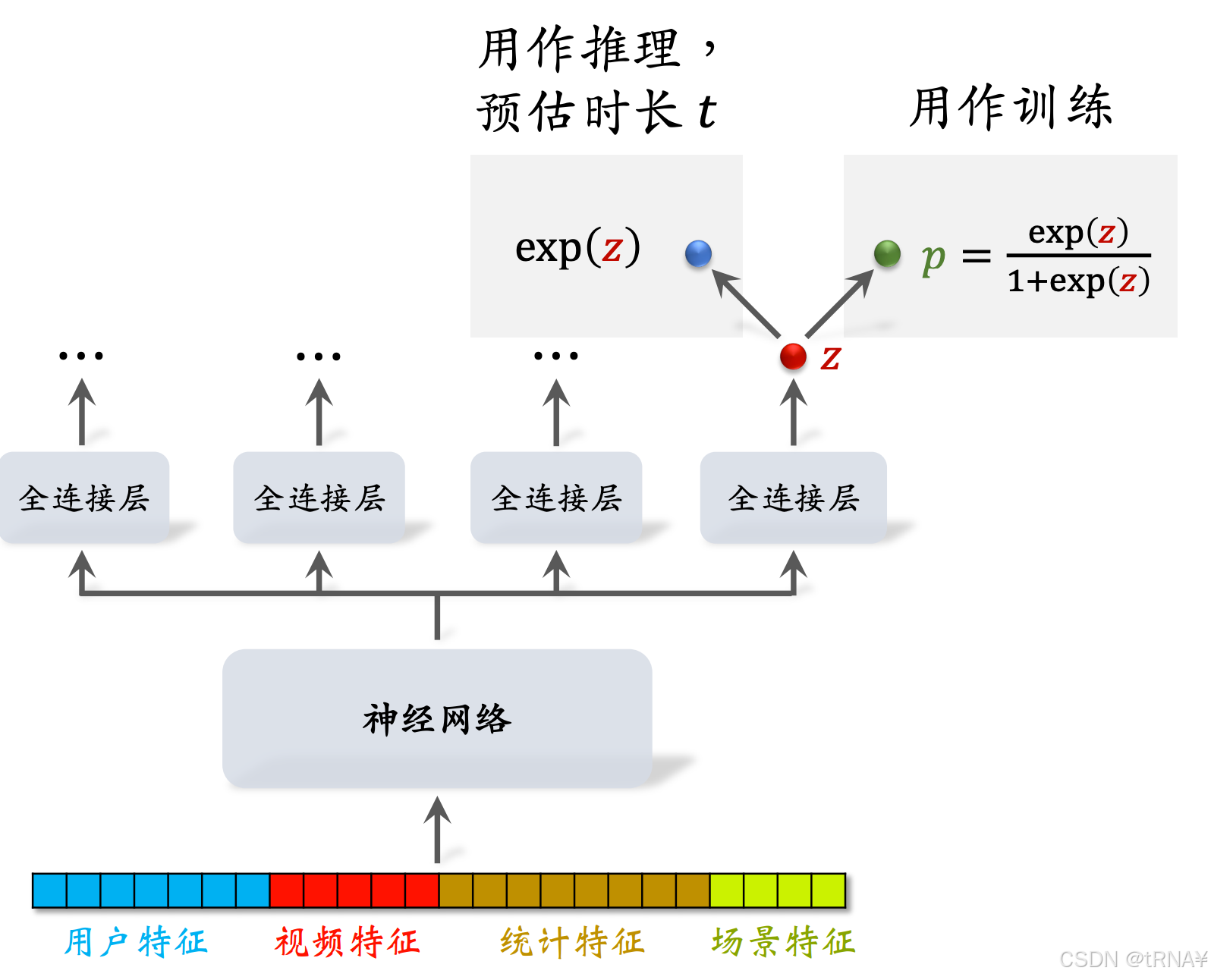
建模
实践中把分母1+t去掉也没问题,相当于给损失函数做加权,权重是播放时长
最终把exp(z)作为融分公式中的一项,它会影响到视频的排序

完播率
完播率有两种建模方法:回归、二元分类
回归

二元分类
完播指标是工程师自己定义的
最后一个公式的含义是:预测完播率为80%的概率为73%

预估的播放率会跟点击率等指标一起作为排序的依据;但是完播率不行。WHY?
reason:视频的完播率与时长有关,视频越长,完播率越低。加入排序依据对短视频有利,对长视频不利。
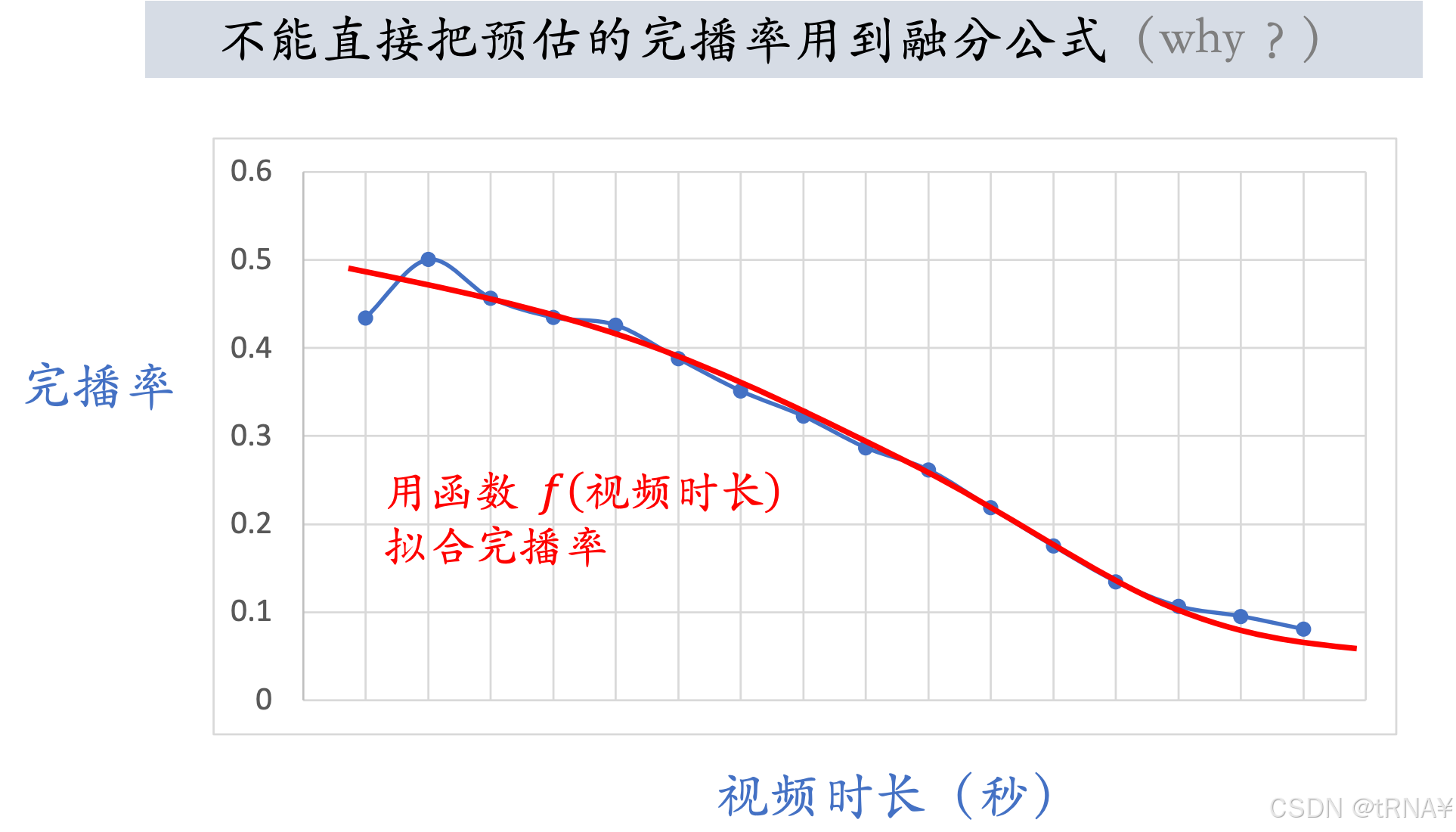
如何解决这个问题呢?
answer:引入新定义,把它作为排序依据作为融分公式中的一项。
视频越长,函数值f越小,把调整之后的分数记作,可以反映出用户对视频的兴趣,而且对长、短视频是公平的

3.5排序模型的特征
排序所需特征
5.1 用户画像(User Profile)-较为静态
- 用户ID(本身没有意义,但是embedding向量很重要)
- 人口统计学属性:性别、年龄
- 账号信息:新老、活跃度…
- 感兴趣的类目、关键词、品牌等
5.2 物品画像(Item Profile)-静态
- 物品ID
- 发布时间/年龄
- GeoHash、所在城市
- 标题、类目、关键词、品牌等
- 字数、图片数、视频清晰度、标签数等
- 内容信息量、图片美学(CV和NLP算法打的分数)
5.3 用户统计特征-动态
- 用户最近30天(7天,1天…)天的曝光数、点击数、点赞数、收藏数…
- 按照笔记图文/视频分桶
- 按照笔记类目分桶
5.4 笔记统计特征-动态
- 笔记最近30天(7天,1天…)的曝光数、点击数、点赞数、收藏数…
- 按照用户性别分桶,按年龄分桶
- 作者特征(发布笔记数、粉丝数、消费指标)
5.5 场景特征
- 用户定位GeoHash、城市
- 当前时刻(分段)
- 是否是周末、是否是节假日
- 手机品牌、手机型号、操作系统
特征处理

连续特征:其他变换
- 曝光数、点击数、点赞数等数值做log(1+x),可以解决异常值问题
- 曝光数等(大多数笔记只有几百次,少数笔记能有上百万次)为长尾分布,计算会出现异常(训练梯度会很离谱,推理的预估值会很奇怪)
- 或者把点击数、点赞数等转化为点击率、点赞率等值,并做平滑(去掉偶然性造成的波动)
- 实际处理中,两种变换之后的连续特征都会作为模型的输入,如log(1+点击数)、平滑之后的点击率都会被用到
特征覆盖率
现实生活中很多特征会缺失,例如用户注册时少填写信息。
提高特征覆盖率可以让精排模型更准
另外还要考虑,当特征缺失时,用什么作为默认值
数据服务
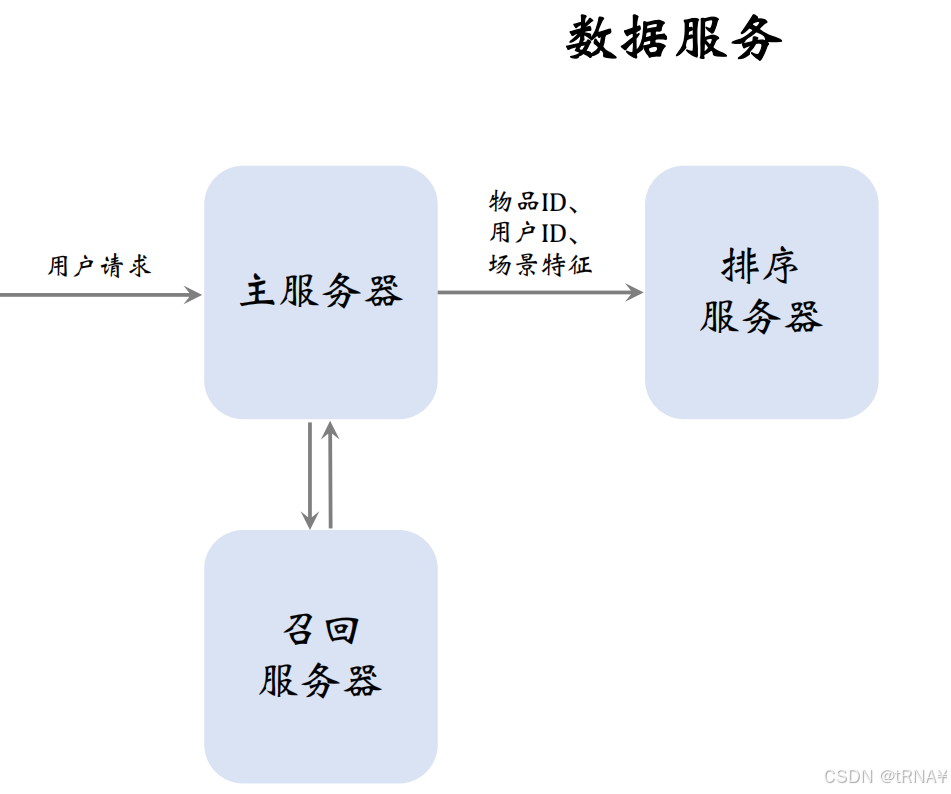
当用户刷小红书时,用户请求会被发送到推荐系统的主服务器上,主服务器会把请求发送到召回服务器上。做完召回后,召回服务器会把几十路召回的结果做归并,把几千篇笔记的ID返回给主服务器(召回需要调用用户画像)
主服务器把笔记ID、用户ID、场景特征(1个用户ID+几千个笔记ID。笔记ID是召回的结果,用户ID和场景特征都是从用户请求中获取的,场景特征包括当前时刻、用户所在地点以及手机的型号和操作系统)发送给排序服务器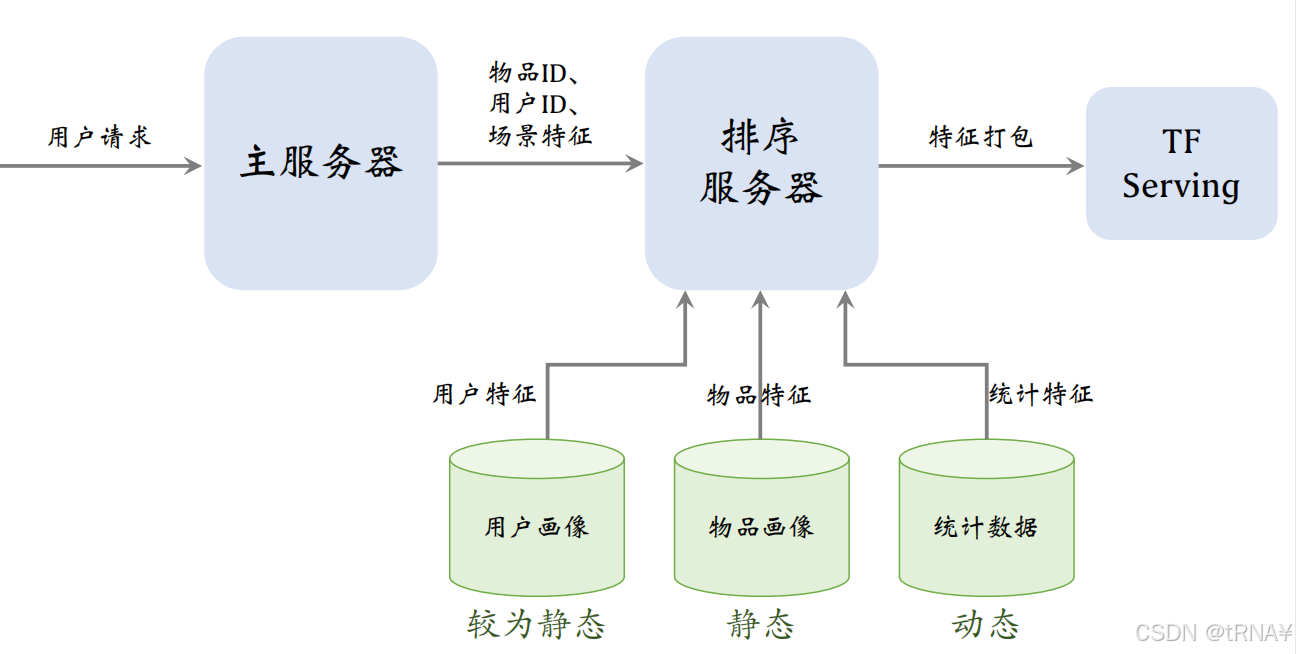

3.6粗排模型
粗排 vs 精排

精排&双塔
| 精排 | 双塔 | |
| 模型类型 | 排序 | 召回 |
| 特征融合 | 前期融合 | 后期融合 |
| 神经网络层 | 被多个任务共享 | 物品塔,用户塔各不相关 |
| 计算量 | 大 | 小(每次只计算一个用户的特征) |
| 精确程度 | 高 | 不如精排 |
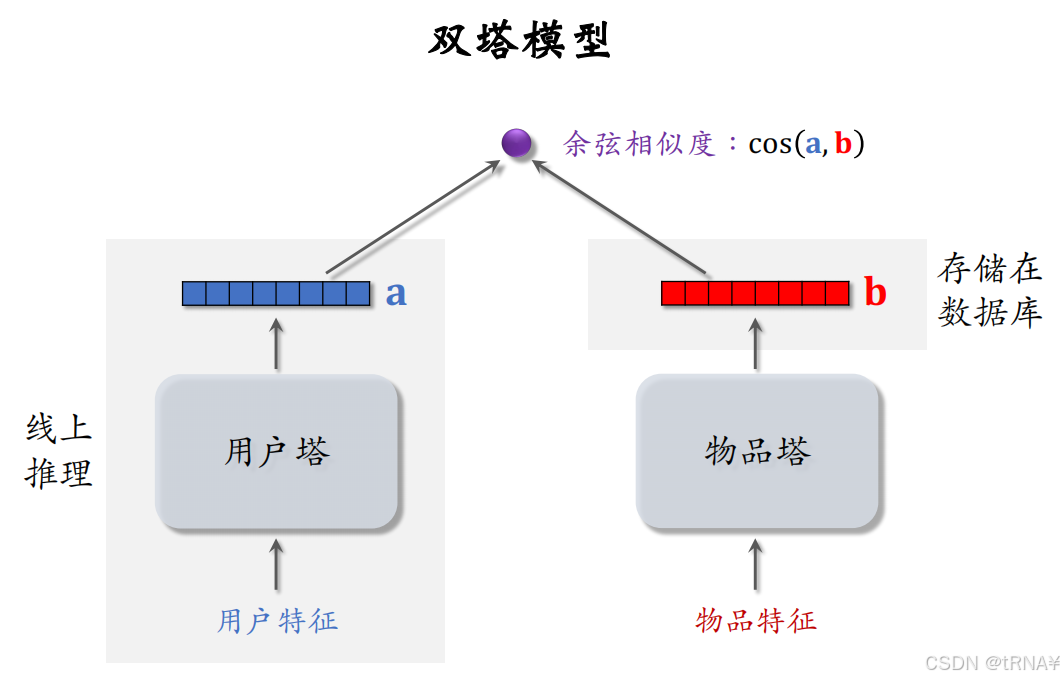
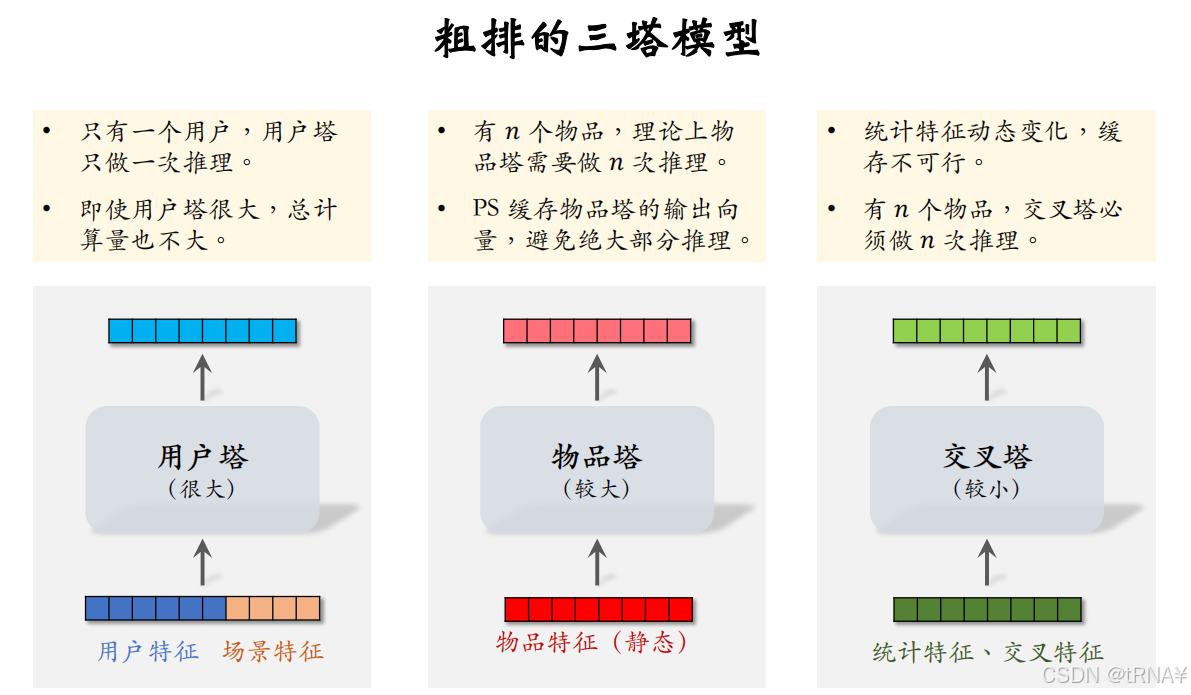
粗排的三塔模型
模型结构
三塔模型介于前期融合(把底层特征做concatenation)和后期融合之间,是把三个塔输出的向量做concatenation
这里回顾一下,双塔模型也就是召回我们用的是后期融合;排序模型我们做的是前期融合。
输入
用户塔:用户特征,场景特征
物品塔:物品特征
交叉塔:用户统计特征和物品统计特征
输出
预估的消费指标
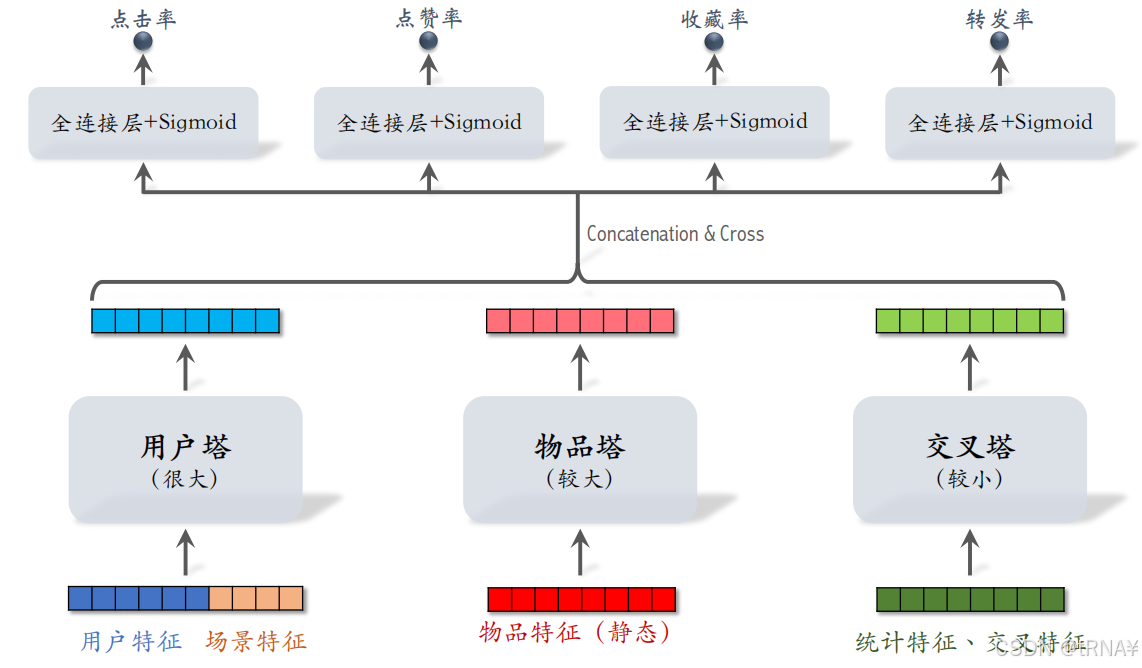
物品的命中率有99%,基本不需要做推理。
统计特征会实时动态变化(每当一个用户发生点击等行为,其统计特征都发生变化;每当一个物品获得曝光和交互,其点击次数、点击率等指标都会发生变化)。由于交叉塔的输入会实时发生变化,不应该缓存交叉塔输出的向量,交叉塔在线上的推理避免不掉,故交叉塔必须足够小、计算够快(通常来说交叉塔只有一层,宽度也比较小)
模型的上层结构
模型上层做n次推理,代价远大于交叉塔的n次推理
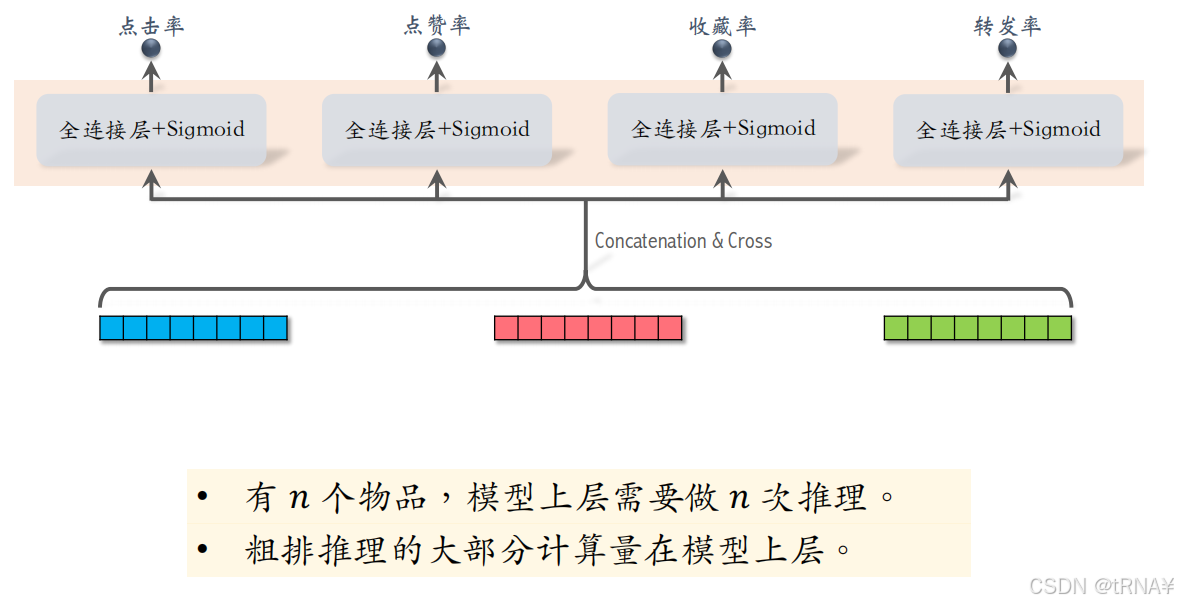
三塔模型的线上推理
- 交叉塔的输入都是动态特征,不能做缓存
- 三个塔各输出一个向量,融合起来作为上层网络的输入

3.7思考问题(复习回顾)
推荐系统链路的每一步都做了什么,它们的共同目标是什么?
排序的依据是什么?
消费指标有哪些?定义分别是什么?这个问题的回答请看我推荐系统专栏的第一章
介绍多目标模型(模型/训练/优化),它的目标函数,输入输出是什么?
在多目标排序模型的训练中,有什么困难?怎么解决?
为什么要进行预估值校准?怎么校准?
MMOE(模型/训练/优化),它的目标函数,输入输出是什么?
MMOE有什么问题?怎么解决?
融合预估分数有哪几种方式?它们的原理是什么?
如何对播放时长和完播率建模?
完播率有哪两种建模方法?
为什么不能将预估的视频的完播率用到融分公式?
排序模型需要哪些特征?
如何和处理这些特征?
特征覆盖率的问题怎么解决?
三塔模型的模型结构。推理代价主要来源于哪个塔?

















 887
887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









