




 本文介绍了使用Verilog进行超前进位加法器的设计,通过计算G和P信号来提前处理进位,采用流水线技术提高运算速度。设计包括了G和P信号的计算、进位信号的生成、以及多级触发器的插入,以实现16位加法器的并行和串行结合运算。通过模块化设计,实现了不同层次的加法和进位计算,优化了电路延迟。
本文介绍了使用Verilog进行超前进位加法器的设计,通过计算G和P信号来提前处理进位,采用流水线技术提高运算速度。设计包括了G和P信号的计算、进位信号的生成、以及多级触发器的插入,以实现16位加法器的并行和串行结合运算。通过模块化设计,实现了不同层次的加法和进位计算,优化了电路延迟。
建议先看我的这篇文章超前进位加法器
思想:
超前进位的思想:通过计算G和P信号,来解决后面三个16bit模块的进位信号,因此可以把高位的三个16bit模块并行起来。
流水线的做法: 在关键路径上插触发器,尽量均衡各部分的延时。
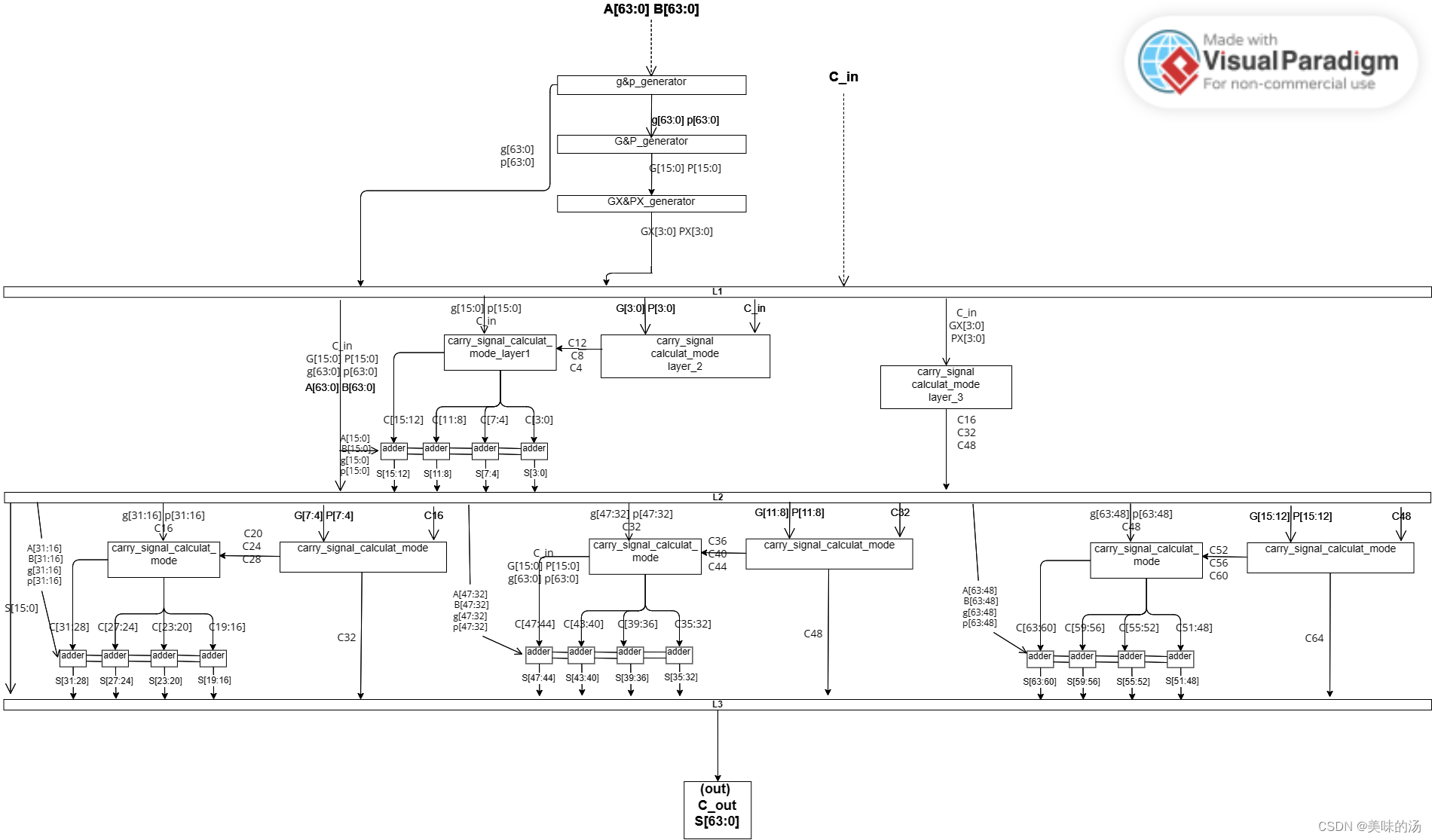
具体设计:g和p信号的计算以及G(GX)和P(PX)信号的计算,与C_in无关,因此可以单独先算出来。 通过这些进位产生/传播信号计算各模块的C_in。然后就是把关键路径尽量均分,这里插入三级触发器。
架构图如下:
verilog代码实现
module adder_nocarry(
input A,B,C_in,
output S
);
assign S = A ^ B ^ C_in;
endmodule
module adder_16bit( //超前三位计算进位信号
input [15:0]A,B,
input [15:0]C,
output [15:0]Y
);
generate
genvar i;
for(i=0;i<16;i=i+1)
begin
adder_nocarry a (A[i],B[i],C[i],Y[i]);
end
endgenerate
endmodule
module Carry_signal_cal_mode(
input [3:0]g,p,
input C_in,
output [3:0]C
);
assign C[0] = g[0] | (p[0]&C_in);
assign C[1] = g[1] | (p[1]&g[0]) | (p[0]&p[1]&C_in) ;
assign C[2] = g[2] | (p[2]&g[1]) | (p[2]&p[1]&g[0]) | (p[2]&p[1]&p[0]&C_in);
assign C[3] = g[3] | (p[3]&g[2]) | (p[3]&p[2]&g[1]) | (p[3]&p[2]&p[1]&g[0]) | (p[3]&p[2]&p[1]&p[0]&C_in) ;
endmodule
module Carry_signal_cal_mode_16bit(
input [15:0]g,p,
input [3:0]C_in,
output [15:0]C
);
generate
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2190
2190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









