



 文章介绍了如何在Yolov5中添加ASFF(AdaptiveSpatialFeatureFusion)模块以增强特征提取能力,详细提供了修改Yolov5模型的步骤,包括在common.py和yolo.py文件中添加相关代码,并创建新的配置文件yolov5s-ASFF.yaml。尽管实验结果显示ASFF仅将mAP提升了1%,但增加了网络复杂性和资源消耗。
文章介绍了如何在Yolov5中添加ASFF(AdaptiveSpatialFeatureFusion)模块以增强特征提取能力,详细提供了修改Yolov5模型的步骤,包括在common.py和yolo.py文件中添加相关代码,并创建新的配置文件yolov5s-ASFF.yaml。尽管实验结果显示ASFF仅将mAP提升了1%,但增加了网络复杂性和资源消耗。
前言
Yolov5是单阶段目标检测算法的一种,网上有很多改进其性能的方法,添加ASFF模块就是其中一种,但是ASFF本身是用于Yolov3的,在v5中无法直接应用,且网上许多博客都是介绍这个模块的原理,没有直接可以应用的代码程序,我这里提供一种方案,如果有什么错误或理解不到位的地方,欢迎评论区指正。
一、ASFF来源及功能
ASFF:Adaptively Spatial Feature Fusion (自适应空间特征融合)
论文来源:Learning Spatial Fusion for Single-Shot Object Detection
代码地址:ASFF
关于ASFF的功能,在网络中所起到的作用,网上已有许多博客,这里不再多说,可以参考以下几位博主的博文:
个人的理解,ASFF就是对特征图金字塔的每一张图片进行卷积、池化等处理提取权重,然后在作用在某一层上,试图利用另外两层的信息来改善指定层次的特征提取能力。
但是在作者实验后发现,加入ASFF模块后,mAP值仅仅从原始网络的92.8%提高到93.8%。然而网络的参数量却翻了一倍达到1200万+,训练时的显存消耗、训练时间也多了不少,感觉有点得不偿失☹️。
提示:下面给出我所用的ASFF代码以及如何在Yolov5/6.0中使用
二、ASFF代码
这里的代码我结合yolov5的网络结构进行过修改,所以会与原代码不同.
第一步,在models/common.py文件最下面添加下面的代码:
def add_conv(in_ch, out_ch, ksize, stride, leaky=True):
"""
Add a conv2d / batchnorm / leaky ReLU block.
Args:
in_ch (int): number of input channels of the convolution layer.
out_ch (int): number of output channels of the convolution layer.
ksize (int): kernel size of the convolution layer.
stride (int): stride of the convolution layer.
Returns:
stage (Sequential) : Sequential layers composing a convolution block.
"""
stage = nn.Sequential()
pad = (ksize - 1) // 2
stage.add_module('conv', nn.Conv2d(in_channels=in_ch,
out_channels=out_ch, kernel_size=ksize, stride=stride,
padding=pad, bias=False))
stage.add_module('batch_norm', nn.BatchNorm2d(out_ch))
if leaky:
stage.add_module('leaky', nn.LeakyReLU(0.1))
else:
stage.add_module('relu6', nn.ReLU6(inplace=True))
return stage
class ASFF(nn.Module):
def __init__(self, level, rfb=False, vis=False):
super(ASFF, self).__init__()
self.level = level
# 特征金字塔从上到下三层的channel数
# 对应特征图大小(以640*640输入为例)分别为20*20, 40*40, 80*80
self.dim = [512, 256, 128]
self.inter_dim = self.dim[self.level]
if level==0: # 特征图最小的一层,channel数512
self.stride_level_1 = add_conv(256, self.inter_dim, 3, 2)
self.stride_level_2 = add_conv(128, self.inter_dim, 3, 2)
self.expand = add_conv(self.inter_dim, 512, 3, 1)
elif level==1: # 特征图大小适中的一层,channel数256
self.compress_level_0 = add_conv(512, self.inter_dim, 1, 1)
self.stride_level_2 = add_conv(128, self.inter_dim, 3, 2)
self.expand = add_conv(self.inter_dim, 256, 3, 1)
elif level==2: # 特征图最大的一层,channel数128
self.compress_level_0 = add_conv(512, self.inter_dim, 1, 1)
self.compress_level_1 = add_conv(256, self.inter_dim, 1, 1)
self.expand = add_conv(self.inter_dim, 128, 3, 1)
compress_c = 8 if rfb else 16 #when adding rfb, we use half number of channels to save memory
self.weight_level_0 = add_conv(self.inter_dim, compress_c, 1, 1)
self.weight_level_1 = add_conv(self.inter_dim, compress_c, 1, 1)
self.weight_level_2 = add_conv(self.inter_dim, compress_c, 1, 1)
self.weight_levels = nn.Conv2d(compress_c*3, 3, kernel_size=1, stride=1, padding=0)
self.vis= vis
def forward(self, x_level_0, x_level_1, x_level_2):
if self.level==0:
level_0_resized = x_level_0
level_1_resized = self.stride_level_1(x_level_1)
level_2_downsampled_inter =F.max_pool2d(x_level_2, 3, stride=2, padding=1)
level_2_resized = self.stride_level_2(level_2_downsampled_inter)
elif self.level==1:
level_0_compressed = self.compress_level_0(x_level_0)
level_0_resized =F.interpolate(level_0_compressed, scale_factor=2, mode='nearest')
level_1_resized =x_level_1
level_2_resized =self.stride_level_2(x_level_2)
elif self.level==2:
level_0_compressed = self.compress_level_0(x_level_0)
level_0_resized =F.interpolate(level_0_compressed, scale_factor=4, mode='nearest')
level_1_compressed = self.compress_level_1(x_level_1)
level_1_resized =F.interpolate(level_1_compressed, scale_factor=2, mode='nearest')
level_2_resized =x_level_2
level_0_weight_v = self.weight_level_0(level_0_resized)
level_1_weight_v = self.weight_level_1(level_1_resized)
level_2_weight_v = self.weight_level_2(level_2_resized)
levels_weight_v = torch.cat((level_0_weight_v, level_1_weight_v, level_2_weight_v),1)
levels_weight = self.weight_levels(levels_weight_v)
levels_weight = F.softmax(levels_weight, dim=1)
fused_out_reduced = level_0_resized * levels_weight[:,0:1,:,:]+\
level_1_resized * levels_weight[:,1:2,:,:]+\
level_2_resized * levels_weight[:,2:,:,:]
out = self.expand(fused_out_reduced)
if self.vis:
return out, levels_weight, fused_out_reduced.sum(dim=1)
else:
return out
二、ASFF融合Yolov5网络
第二步,在models/yolo.py文件的Detect类下面添加下面的类(我的是在92行加的)
class ASFF_Detect(Detect):
# ASFF model for improvement
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__(nc, anchors, ch, inplace)
self.nl = len(anchors)
self.asffs = nn.ModuleList(ASFF(i) for i in range(self.nl))
self.detect = Detect.forward
def forward(self, x): # x中的特征图从大到小,与ASFF中顺序相反,因此输入前先反向
x = x[::-1]
for i in range(self.nl):
x[i] = self.asffs[i](*x)
return self.detect(self, x[::-1])
第三步,在有yolo.py这个文件中,出现 Detect, Segment这个代码片段的地方加入ASFF_Detect,例如我的177行中改动后变成:
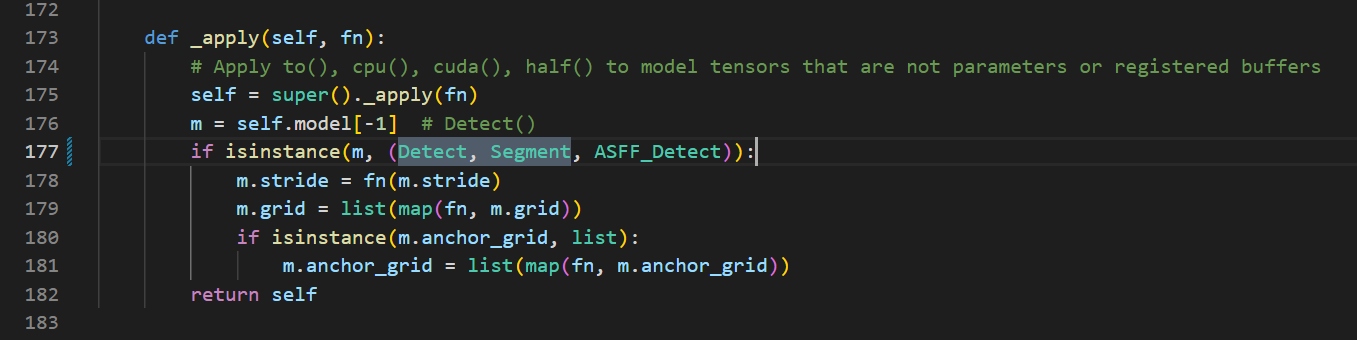
一共会改三处类似的地方,我的分别是177,211,353行。
三、构建使用ASFF的网络
第四步,在models文件夹下新创建一个文件,命名为yolov5s-ASFF.yaml,然后把下面的内容粘贴上去:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 2 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, ASFF_Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
四、查看效果
第五步,在终端中输入命令:
python models/yolo.py --cfg=yolov5s-ASFF.yaml
运行后可以看到我们修改后的模型就被打印出来了:
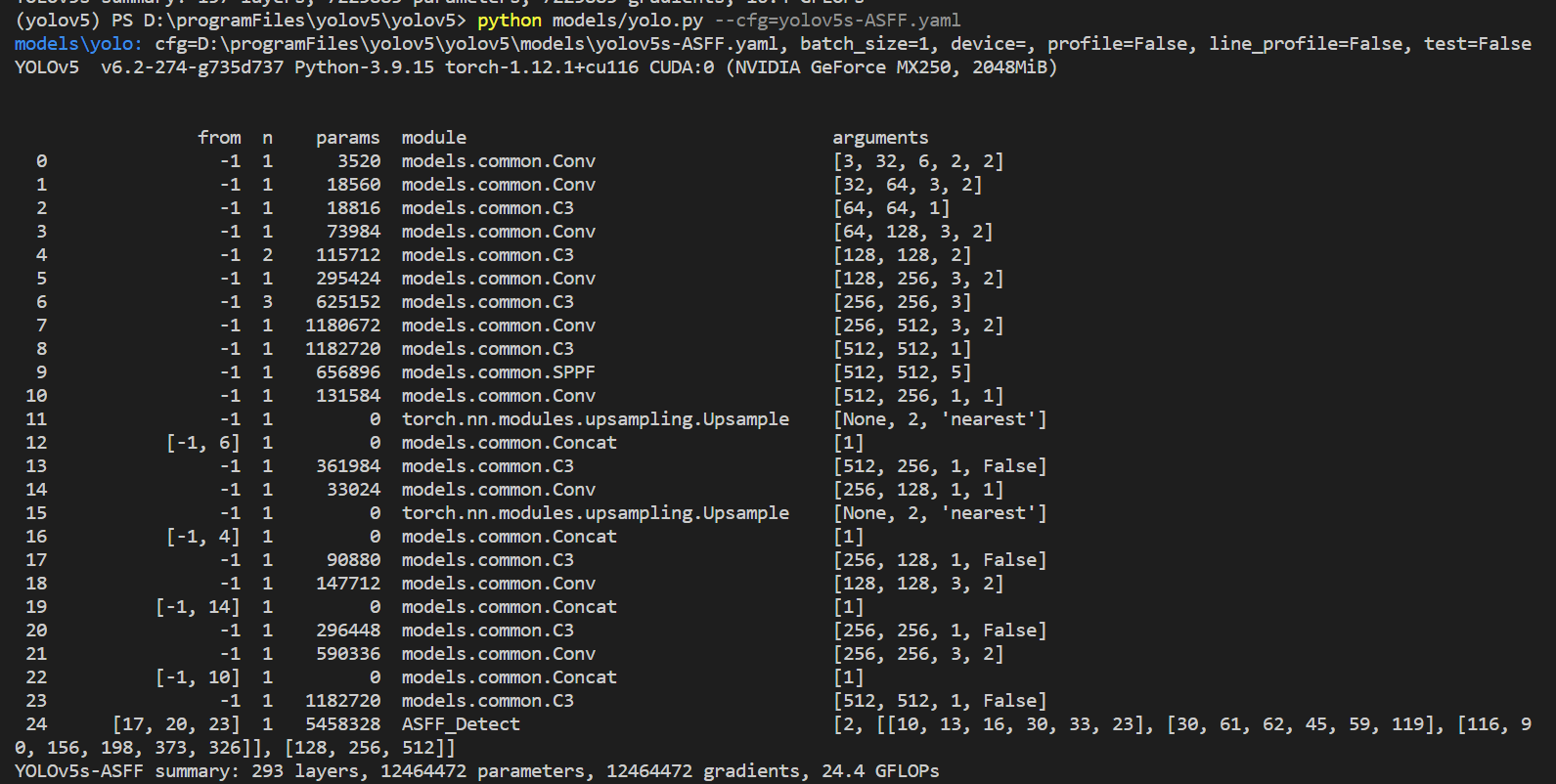
后续训练也是按照原模型的流程进行。
如果觉得本文对你有帮助,不妨动动小手点个赞,你的三连是作者更新的最大动力😊🌹
最后添加一下本文代码的仓库地址(可能有些许差异):https://gitee.com/inavacuum/yolov5_modified

















 1179
1179













 到【灌水乐园】发言
到【灌水乐园】发言







