




步骤一.创建虚拟环境
conda create -n yolov12 python=3.8.20注意:YOLOv12/YOLOv11/YOLOv10/YOLOv9/YOLOv8/YOLOv7a/YOLOv5 环境通用
步骤二.激活虚拟环境
conda activate yolov12 #激活环境步骤三.查询Jetpack出厂版本
Jetson系列平台各型号支持的最高Jetpack版本:
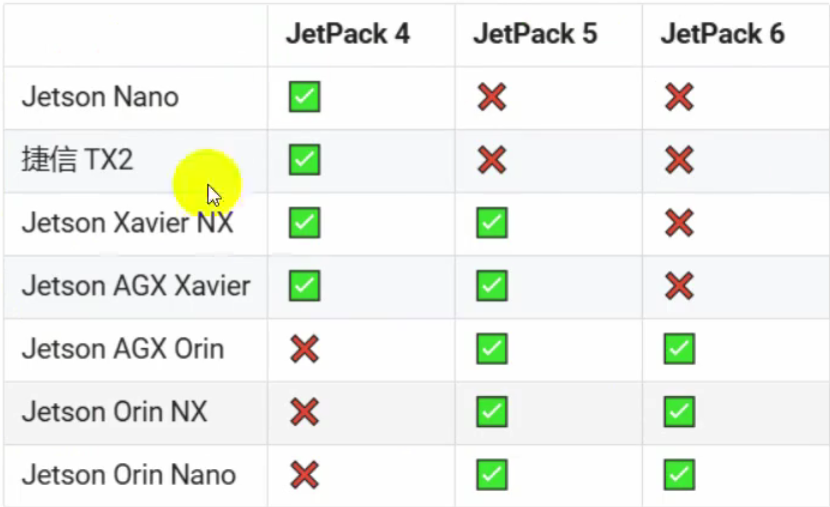
注意:涉及JetPack版本大升级5->6,需要用官方工具重做系统,
查看当前出厂版本
apt-cache show nvidia-jetpack #查看jetpack版本步骤四.Pytorch安装
安装流程(关键)
YOLOv12官方配置环境要求Pytorch版本为2.2.2,笔者JetsonOrinNX的出厂JetPack版本为5.1.3,故按照英伟达官方对于Jetson提供的预编译包链接,选择链接中最贴近2.2版本的torch进行离线下载,再用命令行进行安装。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5427
5427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









